 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Synthesis with Pixel-Space Diffusion Models
Nov 12, 2024Synthesizing a novel view from a single input image is a challenging task. Traditionally, this task was approached by estimating scene depth, warping, and inpainting, with machine learning models enabling parts of the pipeline. More recently, generative models are being increasingly employed in novel view synthesis (NVS), often encompassing the entire end-to-end system. In this work, we adapt a modern diffusion model architecture for end-to-end NVS in the pixel space, substantially outperforming previous state-of-the-art (SOTA) techniques. We explore different ways to encode geometric information into the network. Our experiments show that while these methods may enhance performance, their impact is minor compared to utilizing improved generative models. Moreover, we introduce a novel NVS training scheme that utilizes single-view datasets, capitalizing on their relative abundance compared to their multi-view counterparts. This leads to improved generalization capabilities to scenes with out-of-domain content.
Simple ReFlow: Improved Techniques for Fast Flow Models
Oct 10, 2024



Diffusion and flow-matching models achieve remarkable generative performance but at the cost of many sampling steps, this slows inference and limits applicability to time-critical tasks. The ReFlow procedure can accelerate sampling by straightening generation trajectories. However, ReFlow is an iterative procedure, typically requiring training on simulated data, and results in reduced sample quality. To mitigate sample deterioration, we examine the design space of ReFlow and highlight potential pitfalls in prior heuristic practices. We then propose seven improvements for training dynamics, learning and inference, which are verified with thorough ablation studies on CIFAR10 $32 \times 32$, AFHQv2 $64 \times 64$, and FFHQ $64 \times 64$. Combining all our techniques, we achieve state-of-the-art FID scores (without / with guidance, resp.) for fast generation via neural ODEs: $2.23$ / $1.98$ on CIFAR10, $2.30$ / $1.91$ on AFHQv2, $2.84$ / $2.67$ on FFHQ, and $3.49$ / $1.74$ on ImageNet-64, all with merely $9$ neural function evaluations.
Nested Diffusion Processes for Anytime Image Generation
May 30, 2023Diffusion models are the current state-of-the-art in image generation, synthesizing high-quality images by breaking down the generation process into many fine-grained denoising steps. Despite their good performance, diffusion models are computationally expensive, requiring many neural function evaluations (NFEs). In this work, we propose an anytime diffusion-based method that can generate viable images when stopped at arbitrary times before completion. Using existing pretrained diffusion models, we show that the generation scheme can be recomposed as two nested diffusion processes, enabling fast iterative refinement of a generated image. We use this Nested Diffusion approach to peek into the generation process and enable flexible scheduling based on the instantaneous preference of the user. In experiments on ImageNet and Stable Diffusion-based text-to-image generation, we show, both qualitatively and quantitatively, that our method's intermediate generation quality greatly exceeds that of the original diffusion model, while the final slow generation result remains comparable.
GSURE-Based Diffusion Model Training with Corrupted Data
May 22, 2023Diffusion models have demonstrated impressive results in both data generation and downstream tasks such as inverse problems, text-based editing, classification, and more. However, training such models usually requires large amounts of clean signals which are often difficult or impossible to obtain. In this work, we propose a novel training technique for generative diffusion models based only on corrupted data. We introduce a loss function based on the Generalized Stein's Unbiased Risk Estimator (GSURE), and prove that under some conditions, it is equivalent to the training objective used in fully supervised diffusion models. We demonstrate our technique on face images as well as Magnetic Resonance Imaging (MRI), where the use of undersampled data significantly alleviates data collection costs. Our approach achieves generative performance comparable to its fully supervised counterpart without training on any clean signals. In addition, we deploy the resulting diffusion model in various downstream tasks beyond the degradation present in the training set, showcasing promising results.
Editing Implicit Assumptions in Text-to-Image Diffusion Models
Mar 14, 2023Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.
Image Denoising: The Deep Learning Revolution and Beyond -- A Survey Paper --
Jan 09, 2023Image denoising (removal of additive white Gaussian noise from an image) is one of the oldest and most studied problems in image processing. An extensive work over several decades has led to thousands of papers on this subject, and to many well-performing algorithms for this task. Indeed, 10 years ago, these achievements have led some researchers to suspect that "Denoising is Dead", in the sense that all that can be achieved in this domain has already been obtained. However, this turned out to be far from the truth, with the penetration of deep learning (DL) into image processing. The era of DL brought a revolution to image denoising, both by taking the lead in today's ability for noise removal in images, and by broadening the scope of denoising problems being treated. Our paper starts by describing this evolution, highlighting in particular the tension and synergy that exist between classical approaches and modern DL-based alternatives in design of image denoisers. The recent transitions in the field of image denoising go far beyond the ability to design better denoisers. In the 2nd part of this paper we focus on recently discovered abilities and prospects of image denoisers. We expose the possibility of using denoisers to serve other problems, such as regularizing general inverse problems and serving as the prime engine in diffusion-based image synthesis. We also unveil the idea that denoising and other inverse problems might not have a unique solution as common algorithms would have us believe. Instead, we describe constructive ways to produce randomized and diverse high quality results for inverse problems, all fueled by the progress that DL brought to image denoising. This survey paper aims to provide a broad view of the history of image denoising and closely related topics. Our aim is to give a better context to recent discoveries, and to the influence of DL in our domain.
Imagic: Text-Based Real Image Editing with Diffusion Models
Oct 17, 2022
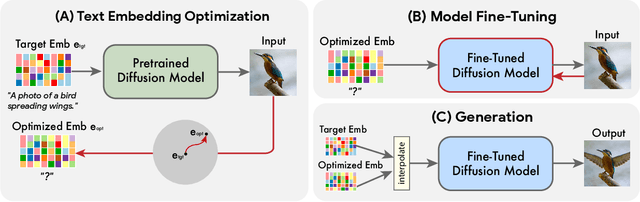


Text-conditioned image editing has recently attracted considerable interest. However, most methods are currently either limited to specific editing types (e.g., object overlay, style transfer), or apply to synthetically generated images, or require multiple input images of a common object. In this paper we demonstrate, for the very first time, the ability to apply complex (e.g., non-rigid) text-guided semantic edits to a single real image. For example, we can change the posture and composition of one or multiple objects inside an image, while preserving its original characteristics. Our method can make a standing dog sit down or jump, cause a bird to spread its wings, etc. -- each within its single high-resolution natural image provided by the user. Contrary to previous work, our proposed method requires only a single input image and a target text (the desired edit). It operates on real images, and does not require any additional inputs (such as image masks or additional views of the object). Our method, which we call "Imagic", leverages a pre-trained text-to-image diffusion model for this task. It produces a text embedding that aligns with both the input image and the target text, while fine-tuning the diffusion model to capture the image-specific appearance. We demonstrate the quality and versatility of our method on numerous inputs from various domains, showcasing a plethora of high quality complex semantic image edits, all within a single unified framework.
JPEG Artifact Correction using Denoising Diffusion Restoration Models
Sep 23, 2022
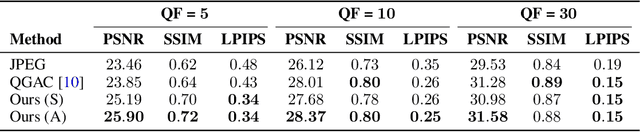

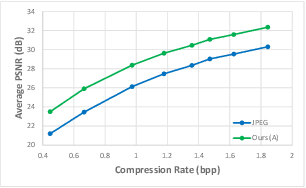
Diffusion models can be used as learned priors for solving various inverse problems. However, most existing approaches are restricted to linear inverse problems, limiting their applicability to more general cases. In this paper, we build upon Denoising Diffusion Restoration Models (DDRM) and propose a method for solving some non-linear inverse problems. We leverage the pseudo-inverse operator used in DDRM and generalize this concept for other measurement operators, which allows us to use pre-trained unconditional diffusion models for applications such as JPEG artifact correction. We empirically demonstrate the effectiveness of our approach across various quality factors, attaining performance levels that are on par with state-of-the-art methods trained specifically for the JPEG restoration task.
Enhancing Diffusion-Based Image Synthesis with Robust Classifier Guidance
Aug 18, 2022



Denoising diffusion probabilistic models (DDPMs) are a recent family of generative models that achieve state-of-the-art results. In order to obtain class-conditional generation, it was suggested to guide the diffusion process by gradients from a time-dependent classifier. While the idea is theoretically sound, deep learning-based classifiers are infamously susceptible to gradient-based adversarial attacks. Therefore, while traditional classifiers may achieve good accuracy scores, their gradients are possibly unreliable and might hinder the improvement of the generation results. Recent work discovered that adversarially robust classifiers exhibit gradients that are aligned with human perception, and these could better guide a generative process towards semantically meaningful images. We utilize this observation by defining and training a time-dependent adversarially robust classifier and use it as guidance for a generative diffusion model. In experiments on the highly challenging and diverse ImageNet dataset, our scheme introduces significantly more intelligible intermediate gradients, better alignment with theoretical findings, as well as improved generation results under several evaluation metrics. Furthermore, we conduct an opinion survey whose findings indicate that human raters prefer our method's results.
Do Perceptually Aligned Gradients Imply Adversarial Robustness?
Jul 22, 2022
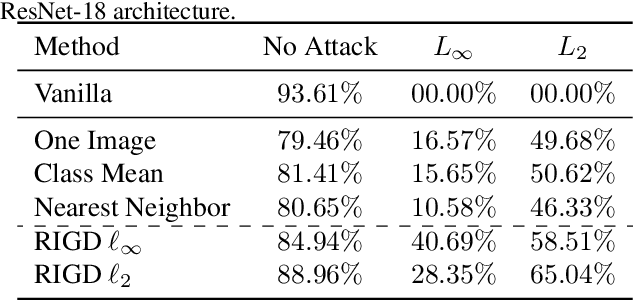
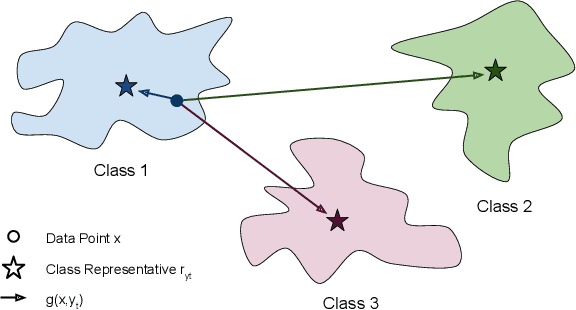

In the past decade, deep learning-based networks have achieved unprecedented success in numerous tasks, including image classification. Despite this remarkable achievement, recent studies have demonstrated that such networks are easily fooled by small malicious perturbations, also known as adversarial examples. This security weakness led to extensive research aimed at obtaining robust models. Beyond the clear robustness benefits of such models, it was also observed that their gradients with respect to the input align with human perception. Several works have identified Perceptually Aligned Gradients (PAG) as a byproduct of robust training, but none have considered it as a standalone phenomenon nor studied its own implications. In this work, we focus on this trait and test whether Perceptually Aligned Gradients imply Robustness. To this end, we develop a novel objective to directly promote PAG in training classifiers and examine whether models with such gradients are more robust to adversarial attacks. Extensive experiments on CIFAR-10 and STL validate that such models have improved robust performance, exposing the surprising bidirectional connection between PAG and robustness.