 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for a Good Stereoscopic Image?
Dec 30, 2024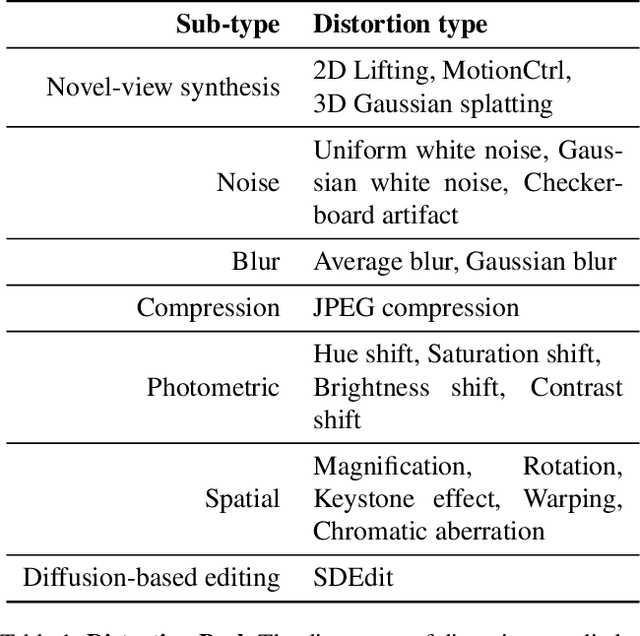

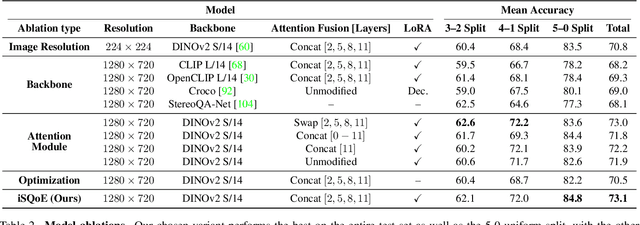
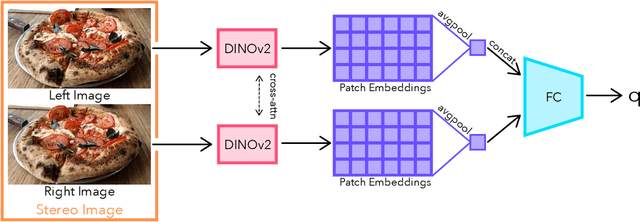
With rapid advancements in virtual reality (VR) headsets, effectively measuring stereoscopic quality of experience (SQoE) has become essential for delivering immersive and comfortable 3D experiences. However, most existing stereo metrics focus on isolated aspects of the viewing experience such as visual discomfort or image quality, and have traditionally faced data limitations. To address these gaps, we present SCOPE (Stereoscopic COntent Preference Evaluation), a new dataset comprised of real and synthetic stereoscopic images featuring a wide range of common perceptual distortions and artifacts. The dataset is labeled with preference annotations collected on a VR headset, with our findings indicating a notable degree of consistency in user preferences across different headsets. Additionally, we present iSQoE, a new model for stereo quality of experience assessment trained on our dataset. We show that iSQoE aligns better with human preferences than existing methods when comparing mono-to-stereo conversion methods.
Disentangling Structure and Appearance in ViT Feature Space
Nov 20, 2023We present a method for semantically transferring the visual appearance of one natural image to another. Specifically, our goal is to generate an image in which objects in a source structure image are "painted" with the visual appearance of their semantically related objects in a target appearance image. To integrate semantic information into our framework, our key idea is to leverage a pre-trained and fixed Vision Transformer (ViT) model. Specifically, we derive novel disentangled representations of structure and appearance extracted from deep ViT features. We then establish an objective function that splices the desired structure and appearance representations, interweaving them together in the space of ViT features. Based on our objective function, we propose two frameworks of semantic appearance transfer -- "Splice", which works by training a generator on a single and arbitrary pair of structure-appearance images, and "SpliceNet", a feed-forward real-time appearance transfer model trained on a dataset of images from a specific domain. Our frameworks do not involve adversarial training, nor do they require any additional input information such as semantic segmentation or correspondences. We demonstrate high-resolution results on a variety of in-the-wild image pairs, under significant variations in the number of objects, pose, and appearance. Code and supplementary material are available in our project page: splice-vit.github.io.
Deep Learning Models for Automated Classification of Dog Emotional States from Facial Expressions
Jun 11, 2022
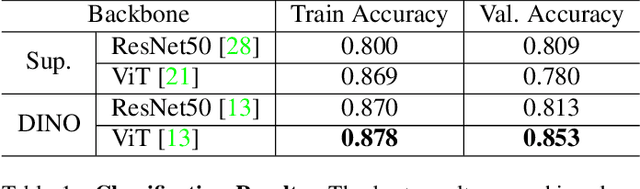
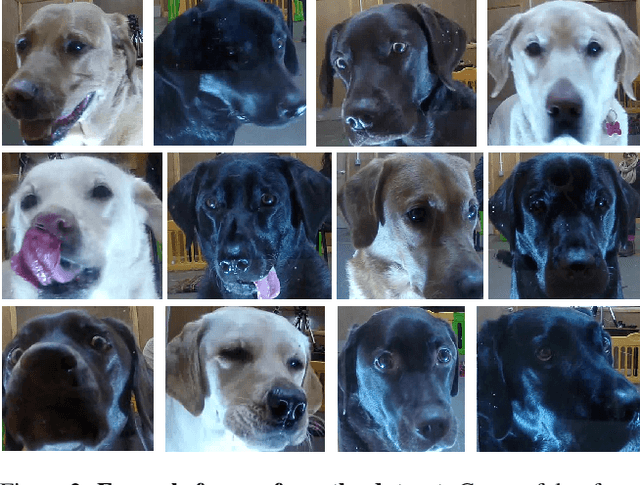
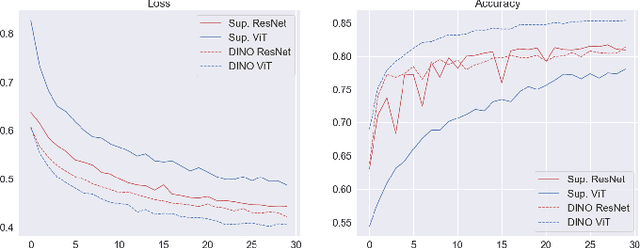
Similarly to humans, facial expressions in animals are closely linked with emotional states. However, in contrast to the human domain, automated recognition of emotional states from facial expressions in animals is underexplored, mainly due to difficulties in data collection and establishment of ground truth concerning emotional states of non-verbal users. We apply recent deep learning techniques to classify (positive) anticipation and (negative) frustration of dogs on a dataset collected in a controlled experimental setting. We explore the suitability of different backbones (e.g. ResNet, ViT) under different supervisions to this task, and find that features of a self-supervised pretrained ViT (DINO-ViT) are superior to the other alternatives. To the best of our knowledge, this work is the first to address the task of automatic classification of canine emotions on data acquired in a controlled experiment.
Deep ViT Features as Dense Visual Descriptors
Dec 10, 2021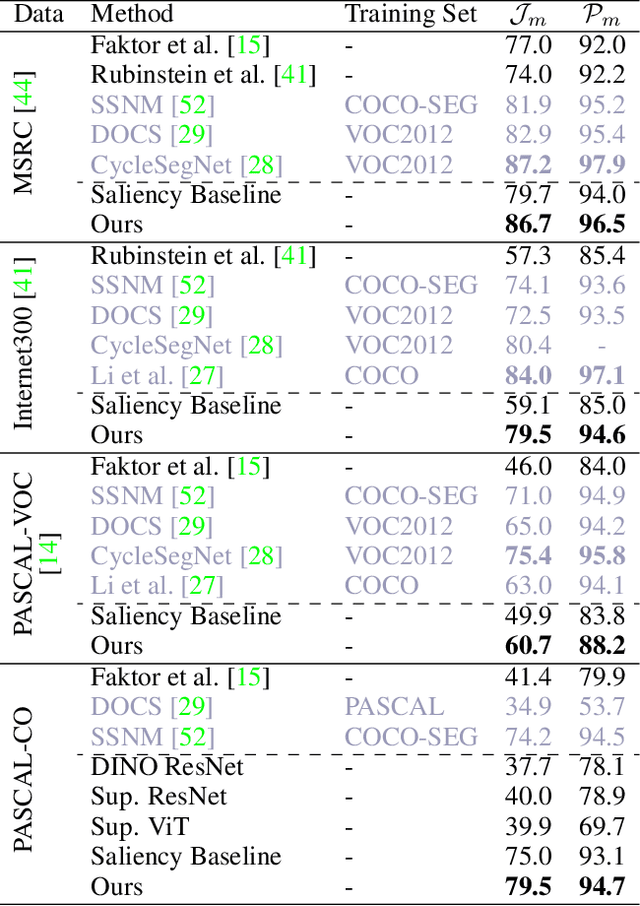
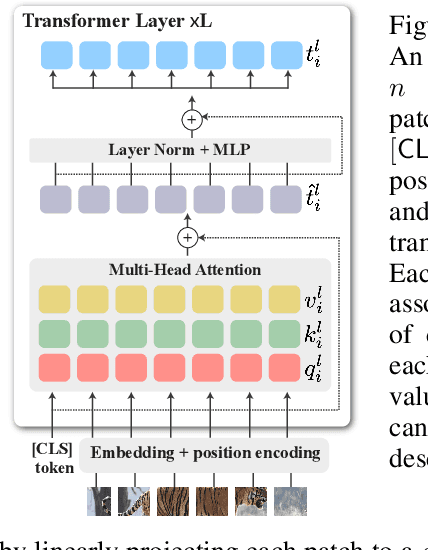


We leverage deep features extracted from a pre-trained Vision Transformer (ViT) as dense visual descriptors. We demonstrate that such features, when extracted from a self-supervised ViT model (DINO-ViT), exhibit several striking properties: (i) the features encode powerful high level information at high spatial resolution -- i.e., capture semantic object parts at fine spatial granularity, and (ii) the encoded semantic information is shared across related, yet different object categories (i.e. super-categories). These properties allow us to design powerful dense ViT descriptors that facilitate a variety of applications, including co-segmentation, part co-segmentation and correspondences -- all achieved by applying lightweight methodologies to deep ViT features (e.g., binning / clustering). We take these applications further to the realm of inter-class tasks -- demonstrating how objects from related categories can be commonly segmented into semantic parts, under significant pose and appearance changes. Our methods, extensively evaluated qualitatively and quantitatively, achieve state-of-the-art part co-segmentation results, and competitive results with recent supervised methods trained specifically for co-segmentation and correspondences.