 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep ViT Features as Dense Visual Descriptors
Paper and Code
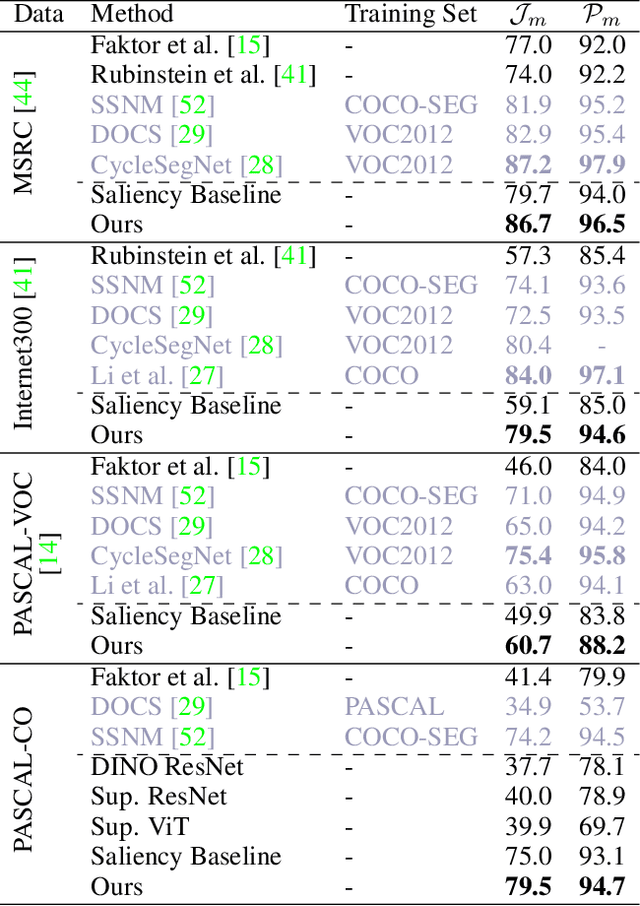
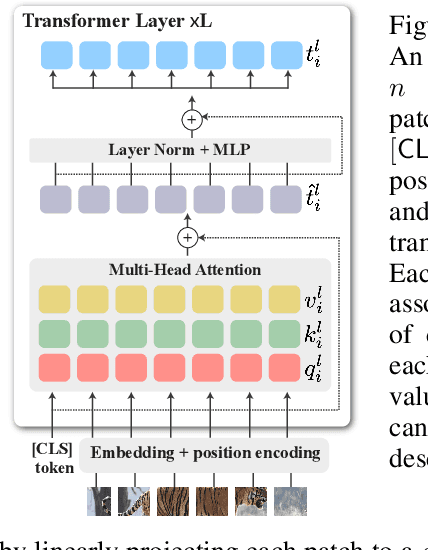


We leverage deep features extracted from a pre-trained Vision Transformer (ViT) as dense visual descriptors. We demonstrate that such features, when extracted from a self-supervised ViT model (DINO-ViT), exhibit several striking properties: (i) the features encode powerful high level information at high spatial resolution -- i.e., capture semantic object parts at fine spatial granularity, and (ii) the encoded semantic information is shared across related, yet different object categories (i.e. super-categories). These properties allow us to design powerful dense ViT descriptors that facilitate a variety of applications, including co-segmentation, part co-segmentation and correspondences -- all achieved by applying lightweight methodologies to deep ViT features (e.g., binning / clustering). We take these applications further to the realm of inter-class tasks -- demonstrating how objects from related categories can be commonly segmented into semantic parts, under significant pose and appearance changes. Our methods, extensively evaluated qualitatively and quantitatively, achieve state-of-the-art part co-segmentation results, and competitive results with recent supervised methods trained specifically for co-segmentation and correspondences.