 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ground Multi-Agent Communication with Autoencoders
Oct 28, 2021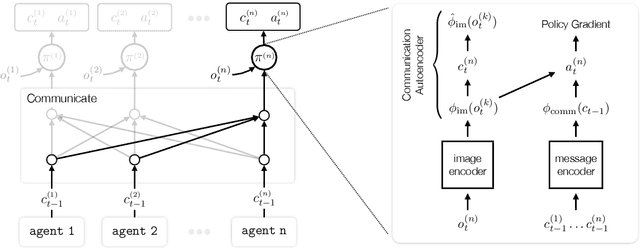
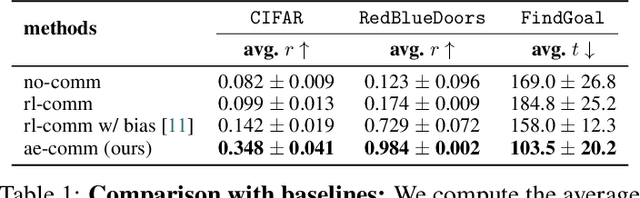
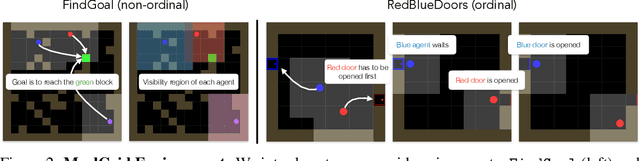

Communication requires having a common language, a lingua franca, between agents. This language could emerge via a consensus process, but it may require many generations of trial and error. Alternatively, the lingua franca can be given by the environment, where agents ground their language in representations of the observed world. We demonstrate a simple way to ground language in learned representations, which facilitates decentralized multi-agent communication and coordination. We find that a standard representation learning algorithm -- autoencoding -- is sufficient for arriving at a grounded common language. When agents broadcast these representations, they learn to understand and respond to each other's utterances and achieve surprisingly strong task performance across a variety of multi-agent communication environments.
Cross-Modal Retrieval Augmentation for Multi-Modal Classification
Apr 16, 2021
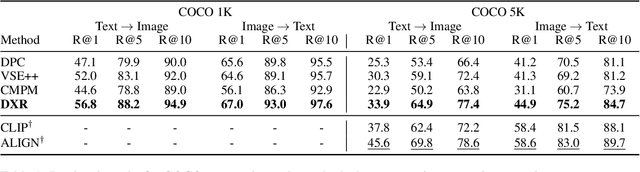

Recent advances in using retrieval components over external knowledge sources have shown impressive results for a variety of downstream tasks in natural language processing. Here, we explore the use of unstructured external knowledge sources of images and their corresponding captions for improving visual question answering (VQA). First, we train a novel alignment model for embedding images and captions in the same space, which achieves substantial improvement in performance on image-caption retrieval w.r.t. similar methods. Second, we show that retrieval-augmented multi-modal transformers using the trained alignment model improve results on VQA over strong baselines. We further conduct extensive experiments to establish the promise of this approach, and examine novel applications for inference time such as hot-swapping indices.
End-to-end Face Detection and Cast Grouping in Movies Using Erdős-Rényi Clustering
Sep 07, 2017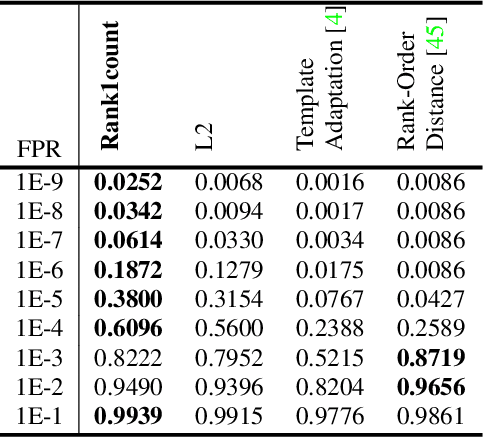

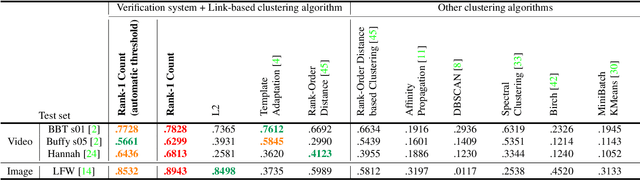
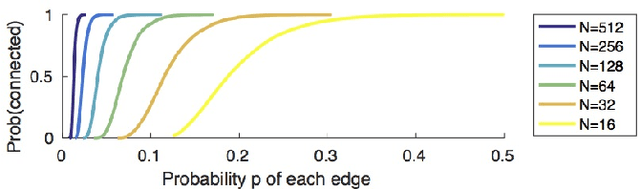
We present an end-to-end system for detecting and clustering faces by identity in full-length movies. Unlike works that start with a predefined set of detected faces, we consider the end-to-end problem of detection and clustering together. We make three separate contributions. First, we combine a state-of-the-art face detector with a generic tracker to extract high quality face tracklets. We then introduce a novel clustering method, motivated by the classic graph theory results of Erd\H{o}s and R\'enyi. It is based on the observations that large clusters can be fully connected by joining just a small fraction of their point pairs, while just a single connection between two different people can lead to poor clustering results. This suggests clustering using a verification system with very few false positives but perhaps moderate recall. We introduce a novel verification method, rank-1 counts verification, that has this property, and use it in a link-based clustering scheme. Finally, we define a novel end-to-end detection and clustering evaluation metric allowing us to assess the accuracy of the entire end-to-end system. We present state-of-the-art results on multiple video data sets and also on standard face databases.
Template Adaptation for Face Verification and Identification
Apr 06, 2016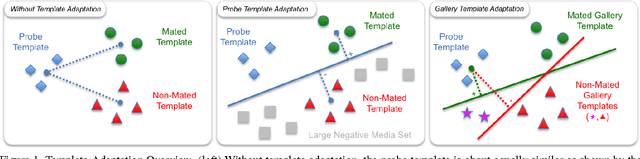
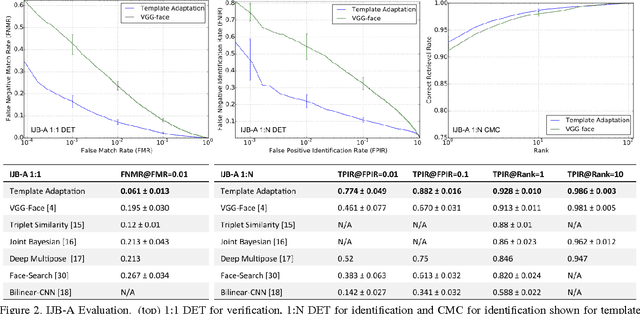

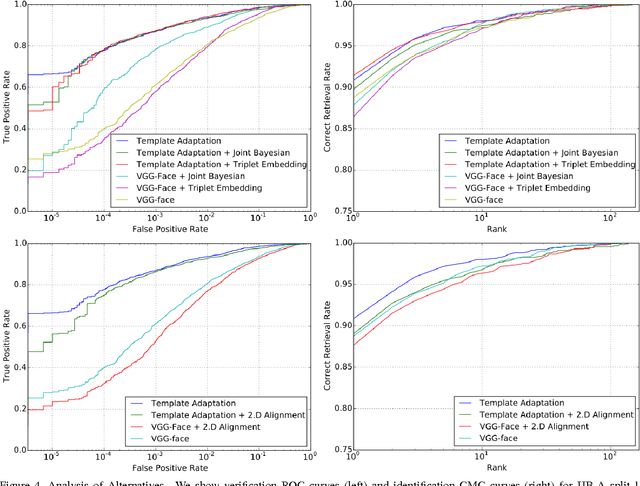
Face recognition performance evaluation has traditionally focused on one-to-one verification, popularized by the Labeled Faces in the Wild dataset for imagery and the YouTubeFaces dataset for videos. In contrast, the newly released IJB-A face recognition dataset unifies evaluation of one-to-many face identification with one-to-one face verification over templates, or sets of imagery and videos for a subject. In this paper, we study the problem of template adaptation, a form of transfer learning to the set of media in a template. Extensive performance evaluations on IJB-A show a surprising result, that perhaps the simplest method of template adaptation, combining deep convolutional network features with template specific linear SVMs, outperforms the state-of-the-art by a wide margin. We study the effects of template size, negative set construction and classifier fusion on performance, then compare template adaptation to convolutional networks with metric learning, 2D and 3D alignment. Our unexpected conclusion is that these other methods, when combined with template adaptation, all achieve nearly the same top performance on IJB-A for template-based face verification and identification.
Factored Latent Analysis for far-field tracking data
Jul 11, 2012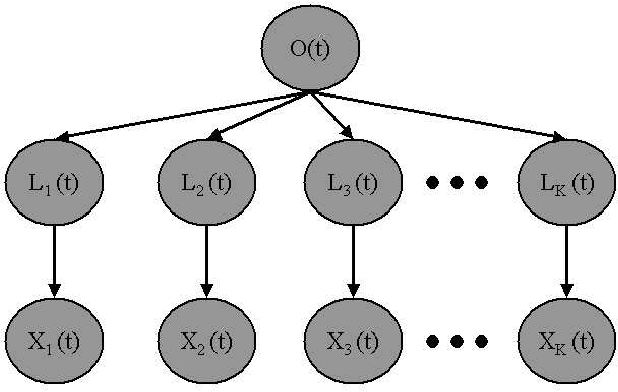

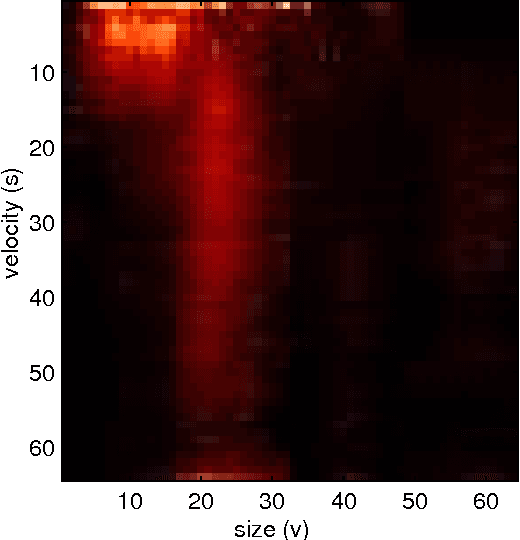

This paper uses Factored Latent Analysis (FLA) to learn a factorized, segmental representation for observations of tracked objects over time. Factored Latent Analysis is latent class analysis in which the observation space is subdivided and each aspect of the original space is represented by a separate latent class model. One could simply treat these factors as completely independent and ignore their interdependencies or one could concatenate them together and attempt to learn latent class structure for the complete observation space. Alternatively, FLA allows the interdependencies to be exploited in estimating an effective model, which is also capable of representing a factored latent state. In this paper, FLA is used to learn a set of factored latent classes to represent different modalities of observations of tracked objects. Different characteristics of the state of tracked objects are each represented by separate latent class models, including normalized size, normalized speed, normalized direction, and position. This model also enables effective temporal segmentation of these sequences. This method is data-driven, unsupervised using only pairwise observation statistics. This data-driven and unsupervised activity classi- fication technique exhibits good performance in multiple challenging environments.