 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemplate Adaptation for Face Verification and Identification
Paper and Code
Apr 06, 2016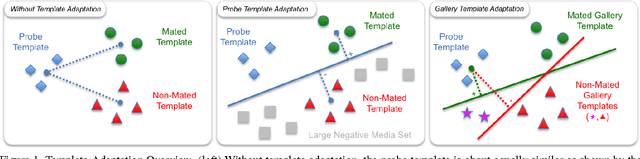
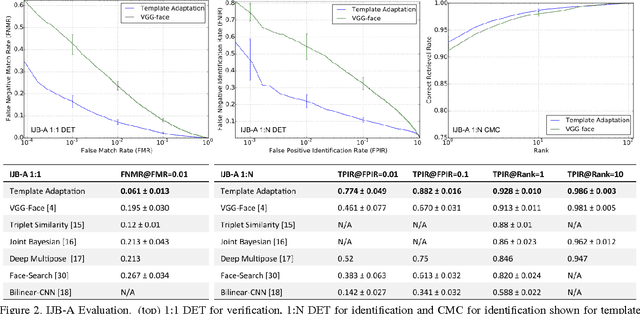

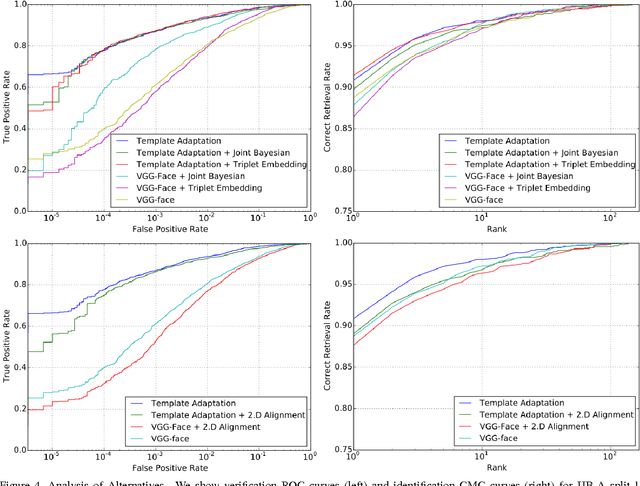
Face recognition performance evaluation has traditionally focused on one-to-one verification, popularized by the Labeled Faces in the Wild dataset for imagery and the YouTubeFaces dataset for videos. In contrast, the newly released IJB-A face recognition dataset unifies evaluation of one-to-many face identification with one-to-one face verification over templates, or sets of imagery and videos for a subject. In this paper, we study the problem of template adaptation, a form of transfer learning to the set of media in a template. Extensive performance evaluations on IJB-A show a surprising result, that perhaps the simplest method of template adaptation, combining deep convolutional network features with template specific linear SVMs, outperforms the state-of-the-art by a wide margin. We study the effects of template size, negative set construction and classifier fusion on performance, then compare template adaptation to convolutional networks with metric learning, 2D and 3D alignment. Our unexpected conclusion is that these other methods, when combined with template adaptation, all achieve nearly the same top performance on IJB-A for template-based face verification and identification.