 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Modal Sets
Paper and Code
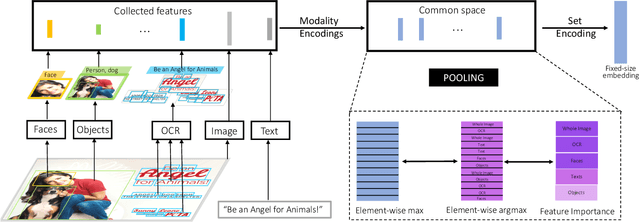

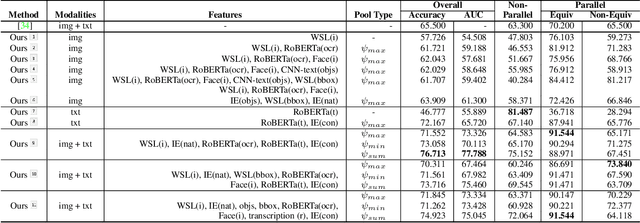

Many vision-related tasks benefit from reasoning over multiple modalities to leverage complementary views of data in an attempt to learn robust embedding spaces. Most deep learning-based methods rely on a late fusion technique whereby multiple feature types are encoded and concatenated and then a multi layer perceptron (MLP) combines the fused embedding to make predictions. This has several limitations, such as an unnatural enforcement that all features be present at all times as well as constraining only a constant number of occurrences of a feature modality at any given time. Furthermore, as more modalities are added, the concatenated embedding grows. To mitigate this, we propose Deep Multi-Modal Sets: a technique that represents a collection of features as an unordered set rather than one long ever-growing fixed-size vector. The set is constructed so that we have invariance both to permutations of the feature modalities as well as to the cardinality of the set. We will also show that with particular choices in our model architecture, we can yield interpretable feature performance such that during inference time we can observe which modalities are most contributing to the prediction.With this in mind, we demonstrate a scalable, multi-modal framework that reasons over different modalities to learn various types of tasks. We demonstrate new state-of-the-art performance on two multi-modal datasets (Ads-Parallelity [34] and MM-IMDb [1]).