 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generation with a Sphere Encoder
Feb 16, 2026We introduce the Sphere Encoder, an efficient generative framework capable of producing images in a single forward pass and competing with many-step diffusion models using fewer than five steps. Our approach works by learning an encoder that maps natural images uniformly onto a spherical latent space, and a decoder that maps random latent vectors back to the image space. Trained solely through image reconstruction losses, the model generates an image by simply decoding a random point on the sphere. Our architecture naturally supports conditional generation, and looping the encoder/decoder a few times can further enhance image quality. Across several datasets, the sphere encoder approach yields performance competitive with state of the art diffusions, but with a small fraction of the inference cost. Project page is available at https://sphere-encoder.github.io .
PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Dec 31, 2025Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
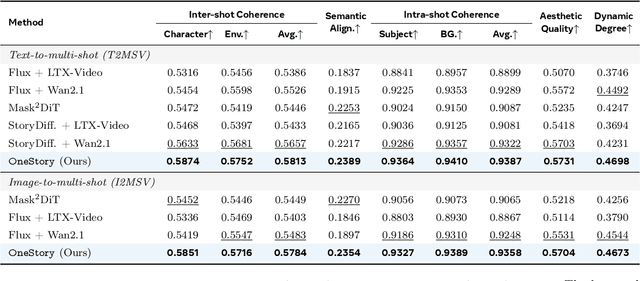
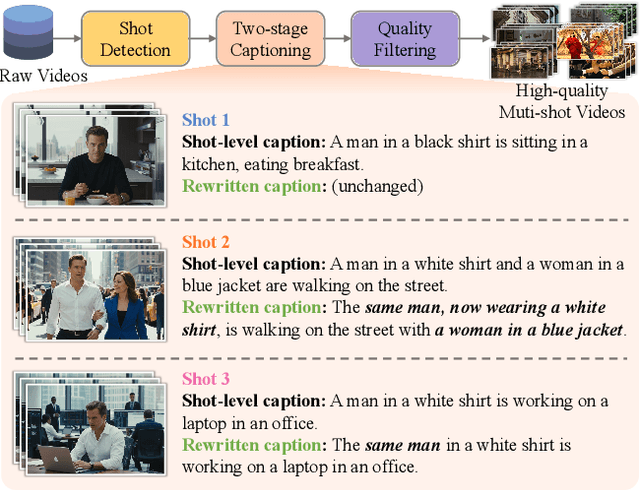

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Zero-Shot Vision Encoder Grafting via LLM Surrogates
May 28, 2025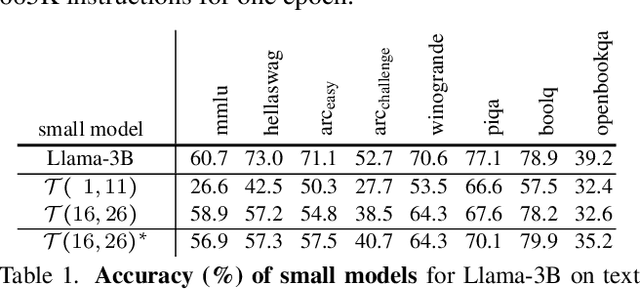
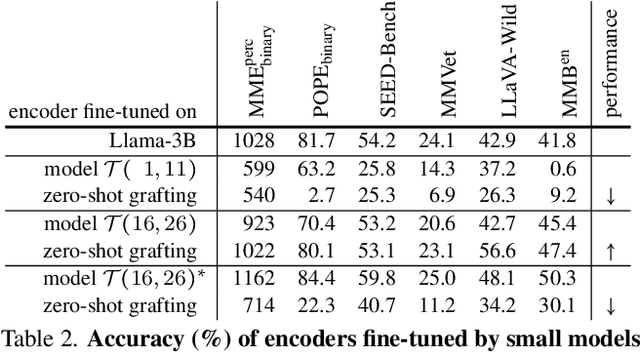
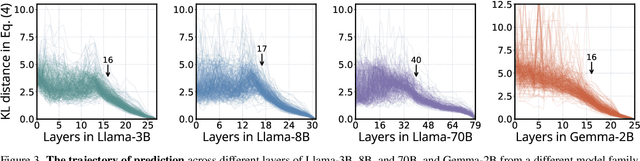

Vision language models (VLMs) typically pair a modestly sized vision encoder with a large language model (LLM), e.g., Llama-70B, making the decoder the primary computational burden during training. To reduce costs, a potential promising strategy is to first train the vision encoder using a small language model before transferring it to the large one. We construct small "surrogate models" that share the same embedding space and representation language as the large target LLM by directly inheriting its shallow layers. Vision encoders trained on the surrogate can then be directly transferred to the larger model, a process we call zero-shot grafting -- when plugged directly into the full-size target LLM, the grafted pair surpasses the encoder-surrogate pair and, on some benchmarks, even performs on par with full decoder training with the target LLM. Furthermore, our surrogate training approach reduces overall VLM training costs by ~45% when using Llama-70B as the decoder.
Adaptive Caching for Faster Video Generation with Diffusion Transformers
Nov 04, 2024



Generating temporally-consistent high-fidelity videos can be computationally expensive, especially over longer temporal spans. More-recent Diffusion Transformers (DiTs) -- despite making significant headway in this context -- have only heightened such challenges as they rely on larger models and heavier attention mechanisms, resulting in slower inference speeds. In this paper, we introduce a training-free method to accelerate video DiTs, termed Adaptive Caching (AdaCache), which is motivated by the fact that "not all videos are created equal": meaning, some videos require fewer denoising steps to attain a reasonable quality than others. Building on this, we not only cache computations through the diffusion process, but also devise a caching schedule tailored to each video generation, maximizing the quality-latency trade-off. We further introduce a Motion Regularization (MoReg) scheme to utilize video information within AdaCache, essentially controlling the compute allocation based on motion content. Altogether, our plug-and-play contributions grant significant inference speedups (e.g. up to 4.7x on Open-Sora 720p - 2s video generation) without sacrificing the generation quality, across multiple video DiT baselines.
MarDini: Masked Autoregressive Diffusion for Video Generation at Scale
Oct 26, 2024



We introduce MarDini, a new family of video diffusion models that integrate the advantages of masked auto-regression (MAR) into a unified diffusion model (DM) framework. Here, MAR handles temporal planning, while DM focuses on spatial generation in an asymmetric network design: i) a MAR-based planning model containing most of the parameters generates planning signals for each masked frame using low-resolution input; ii) a lightweight generation model uses these signals to produce high-resolution frames via diffusion de-noising. MarDini's MAR enables video generation conditioned on any number of masked frames at any frame positions: a single model can handle video interpolation (e.g., masking middle frames), image-to-video generation (e.g., masking from the second frame onward), and video expansion (e.g., masking half the frames). The efficient design allocates most of the computational resources to the low-resolution planning model, making computationally expensive but important spatio-temporal attention feasible at scale. MarDini sets a new state-of-the-art for video interpolation; meanwhile, within few inference steps, it efficiently generates videos on par with those of much more expensive advanced image-to-video models.
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Apr 08, 2024



With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
VideoGLUE: Video General Understanding Evaluation of Foundation Models
Jul 06, 2023



We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action recognition, temporal localization, and spatiotemporal localization), eight datasets well received by the community, and four adaptation methods tailoring a foundation model (FM) for a downstream task. Moreover, we propose a scalar VideoGLUE score (VGS) to measure an FMs efficacy and efficiency when adapting to general video understanding tasks. Our main findings are as follows. First, task-specialized models significantly outperform the six FMs studied in this work, in sharp contrast to what FMs have achieved in natural language and image understanding. Second,video-native FMs, whose pretraining data contains the video modality, are generally better than image-native FMs in classifying motion-rich videos, localizing actions in time, and understanding a video of more than one action. Third, the video-native FMs can perform well on video tasks under light adaptations to downstream tasks(e.g., freezing the FM backbones), while image-native FMs win in full end-to-end finetuning. The first two observations reveal the need and tremendous opportunities to conduct research on video-focused FMs, and the last confirms that both tasks and adaptation methods matter when it comes to the evaluation of FMs.
Emergent Correspondence from Image Diffusion
Jun 06, 2023Finding correspondences between images is a fundamental problem in computer vision. In this paper, we show that correspondence emerges in image diffusion models without any explicit supervision. We propose a simple strategy to extract this implicit knowledge out of diffusion networks as image features, namely DIffusion FeaTures (DIFT), and use them to establish correspondences between real images. Without any additional fine-tuning or supervision on the task-specific data or annotations, DIFT is able to outperform both weakly-supervised methods and competitive off-the-shelf features in identifying semantic, geometric, and temporal correspondences. Particularly for semantic correspondence, DIFT from Stable Diffusion is able to outperform DINO and OpenCLIP by 19 and 14 accuracy points respectively on the challenging SPair-71k benchmark. It even outperforms the state-of-the-art supervised methods on 9 out of 18 categories while remaining on par for the overall performance. Project page: https://diffusionfeatures.github.io
PromptFusion: Decoupling Stability and Plasticity for Continual Learning
Mar 13, 2023Continual learning refers to the capability of continuously learning from a stream of data. Current research mainly focuses on relieving catastrophic forgetting, and most of their success is at the cost of limiting the performance of newly incoming tasks. Such a trade-off is referred to as the stabilityplasticity dilemma and is a more general and challenging problem for continual learning. However, the inherent conflict between these two concepts makes it seemingly impossible to devise a satisfactory solution to both of them simultaneously. Therefore, we ask, "is it possible to divide them into two problems to conquer independently?" To this end, we propose a prompt-tuning-based method termed PromptFusion to enable the decoupling of stability and plasticity. Specifically, PromptFusion consists of a carefully designed Stabilizer module that deals with catastrophic forgetting and a Booster module to learn new knowledge concurrently. During training, PromptFusion first passes an input image to the two modules separately. Then the resulting logits are further fused with a learnable weight parameter. Finally, a weight mask is applied to the derived logits to balance between old and new classes. Extensive experiments show that our method achieves promising results on popular continual learning datasets for both class-incremental and domain incremental settings. Especially on Split-Imagenet-R, one of the most challenging datasets for class-incremental learning, our method exceeds state-of-the-art prompt-based methods L2P and DualPrompt by more than 10%.