 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Diffusion Preview with Consistency Solver
Dec 15, 2025The slow inference process of image diffusion models significantly degrades interactive user experiences. To address this, we introduce Diffusion Preview, a novel paradigm employing rapid, low-step sampling to generate preliminary outputs for user evaluation, deferring full-step refinement until the preview is deemed satisfactory. Existing acceleration methods, including training-free solvers and post-training distillation, struggle to deliver high-quality previews or ensure consistency between previews and final outputs. We propose ConsistencySolver derived from general linear multistep methods, a lightweight, trainable high-order solver optimized via Reinforcement Learning, that enhances preview quality and consistency. Experimental results demonstrate that ConsistencySolver significantly improves generation quality and consistency in low-step scenarios, making it ideal for efficient preview-and-refine workflows. Notably, it achieves FID scores on-par with Multistep DPM-Solver using 47% fewer steps, while outperforming distillation baselines. Furthermore, user studies indicate our approach reduces overall user interaction time by nearly 50% while maintaining generation quality. Code is available at https://github.com/G-U-N/consolver.
Video Creation by Demonstration
Dec 12, 2024



We explore a novel video creation experience, namely Video Creation by Demonstration. Given a demonstration video and a context image from a different scene, we generate a physically plausible video that continues naturally from the context image and carries out the action concepts from the demonstration. To enable this capability, we present $\delta$-Diffusion, a self-supervised training approach that learns from unlabeled videos by conditional future frame prediction. Unlike most existing video generation controls that are based on explicit signals, we adopts the form of implicit latent control for maximal flexibility and expressiveness required by general videos. By leveraging a video foundation model with an appearance bottleneck design on top, we extract action latents from demonstration videos for conditioning the generation process with minimal appearance leakage. Empirically, $\delta$-Diffusion outperforms related baselines in terms of both human preference and large-scale machine evaluations, and demonstrates potentials towards interactive world simulation. Sampled video generation results are available at https://delta-diffusion.github.io/.
VideoPrism: A Foundational Visual Encoder for Video Understanding
Feb 20, 2024
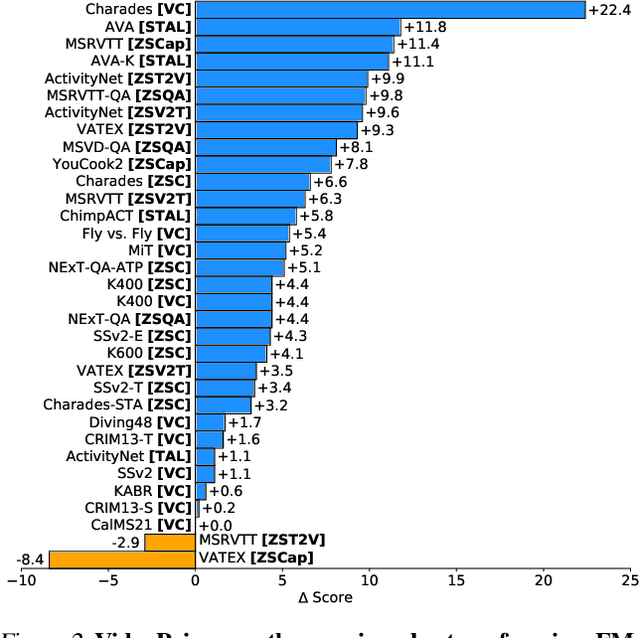
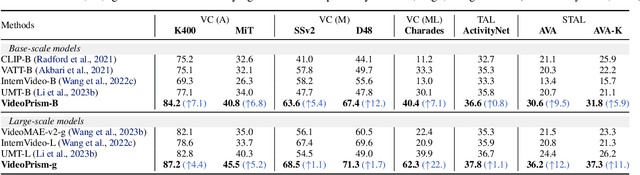
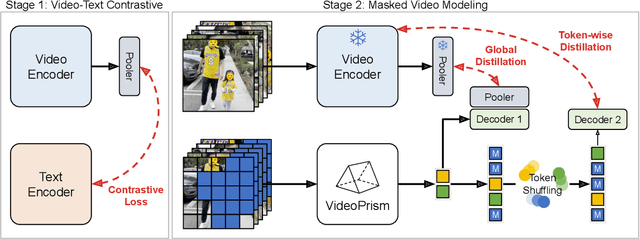
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 30 out of 33 video understanding benchmarks.
Distilling Vision-Language Models on Millions of Videos
Jan 11, 2024



The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video-language model is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%.
PolyMaX: General Dense Prediction with Mask Transformer
Nov 09, 2023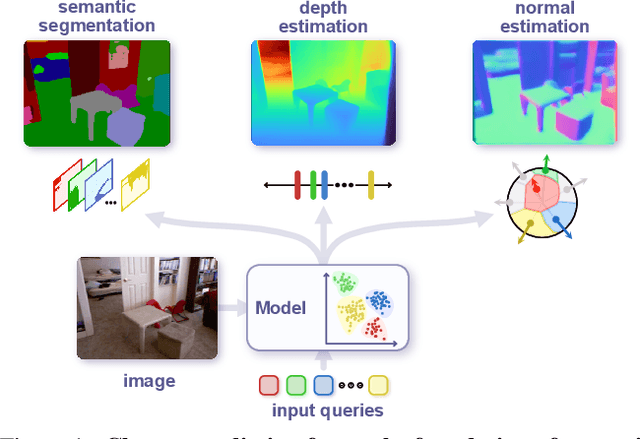
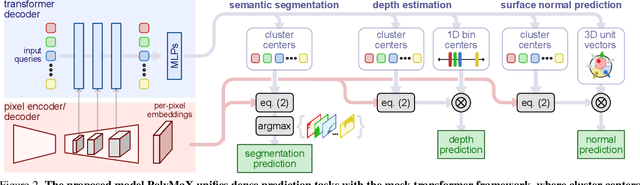
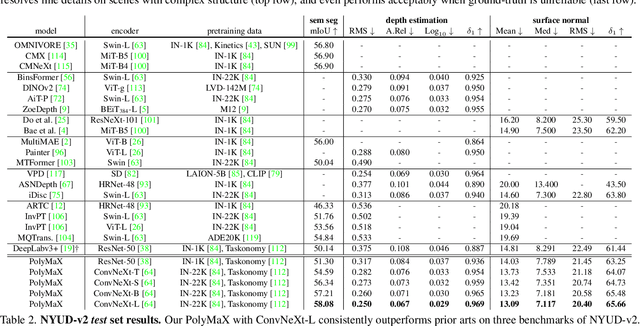
Dense prediction tasks, such as semantic segmentation, depth estimation, and surface normal prediction, can be easily formulated as per-pixel classification (discrete outputs) or regression (continuous outputs). This per-pixel prediction paradigm has remained popular due to the prevalence of fully convolutional networks. However, on the recent frontier of segmentation task, the community has been witnessing a shift of paradigm from per-pixel prediction to cluster-prediction with the emergence of transformer architectures, particularly the mask transformers, which directly predicts a label for a mask instead of a pixel. Despite this shift, methods based on the per-pixel prediction paradigm still dominate the benchmarks on the other dense prediction tasks that require continuous outputs, such as depth estimation and surface normal prediction. Motivated by the success of DORN and AdaBins in depth estimation, achieved by discretizing the continuous output space, we propose to generalize the cluster-prediction based method to general dense prediction tasks. This allows us to unify dense prediction tasks with the mask transformer framework. Remarkably, the resulting model PolyMaX demonstrates state-of-the-art performance on three benchmarks of NYUD-v2 dataset. We hope our simple yet effective design can inspire more research on exploiting mask transformers for more dense prediction tasks. Code and model will be made available.
Learning from Semantic Alignment between Unpaired Multiviews for Egocentric Video Recognition
Aug 23, 2023We are concerned with a challenging scenario in unpaired multiview video learning. In this case, the model aims to learn comprehensive multiview representations while the cross-view semantic information exhibits variations. We propose Semantics-based Unpaired Multiview Learning (SUM-L) to tackle this unpaired multiview learning problem. The key idea is to build cross-view pseudo-pairs and do view-invariant alignment by leveraging the semantic information of videos. To facilitate the data efficiency of multiview learning, we further perform video-text alignment for first-person and third-person videos, to fully leverage the semantic knowledge to improve video representations. Extensive experiments on multiple benchmark datasets verify the effectiveness of our framework. Our method also outperforms multiple existing view-alignment methods, under the more challenging scenario than typical paired or unpaired multimodal or multiview learning. Our code is available at https://github.com/wqtwjt1996/SUM-L.
VideoGLUE: Video General Understanding Evaluation of Foundation Models
Jul 06, 2023



We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action recognition, temporal localization, and spatiotemporal localization), eight datasets well received by the community, and four adaptation methods tailoring a foundation model (FM) for a downstream task. Moreover, we propose a scalar VideoGLUE score (VGS) to measure an FMs efficacy and efficiency when adapting to general video understanding tasks. Our main findings are as follows. First, task-specialized models significantly outperform the six FMs studied in this work, in sharp contrast to what FMs have achieved in natural language and image understanding. Second,video-native FMs, whose pretraining data contains the video modality, are generally better than image-native FMs in classifying motion-rich videos, localizing actions in time, and understanding a video of more than one action. Third, the video-native FMs can perform well on video tasks under light adaptations to downstream tasks(e.g., freezing the FM backbones), while image-native FMs win in full end-to-end finetuning. The first two observations reveal the need and tremendous opportunities to conduct research on video-focused FMs, and the last confirms that both tasks and adaptation methods matter when it comes to the evaluation of FMs.
Spatiotemporally Discriminative Video-Language Pre-Training with Text Grounding
Mar 28, 2023



Most of existing video-language pre-training methods focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. In this work, we propose a simple yet effective video-language pre-training framework, namely G-ViLM, to learn discriminative spatiotemporal features. Two novel designs involving spatiotemporal grounding and temporal grouping promote learning local region-noun alignment and temporal-aware features simultaneously. Specifically, spatiotemporal grounding aggregates semantically similar video tokens and aligns them with noun phrases extracted from the caption to promote local region-noun correspondences. Moreover, temporal grouping leverages cut-and-paste to manually create temporal scene changes and then learns distinguishable features from different scenes. Comprehensive evaluations demonstrate that G-ViLM performs favorably against existing approaches on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition and temporal action localization. G-ViLM performs competitively on all evaluated tasks and in particular achieves R@10 of 65.1 on zero-shot MSR-VTT retrieval, over 9% higher than the state-of-the-art method.
Unified Visual Relationship Detection with Vision and Language Models
Mar 16, 2023



This work focuses on training a single visual relationship detector predicting over the union of label spaces from multiple datasets. Merging labels spanning different datasets could be challenging due to inconsistent taxonomies. The issue is exacerbated in visual relationship detection when second-order visual semantics are introduced between pairs of objects. To address this challenge, we propose UniVRD, a novel bottom-up method for Unified Visual Relationship Detection by leveraging vision and language models (VLMs). VLMs provide well-aligned image and text embeddings, where similar relationships are optimized to be close to each other for semantic unification. Our bottom-up design enables the model to enjoy the benefit of training with both object detection and visual relationship datasets. Empirical results on both human-object interaction detection and scene-graph generation demonstrate the competitive performance of our model. UniVRD achieves 38.07 mAP on HICO-DET, outperforming the current best bottom-up HOI detector by 60% relatively. More importantly, we show that our unified detector performs as well as dataset-specific models in mAP, and achieves further improvements when we scale up the model.
Surrogate Gap Minimization Improves Sharpness-Aware Training
Mar 19, 2022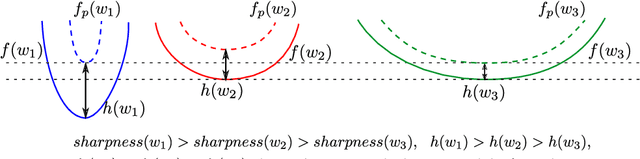
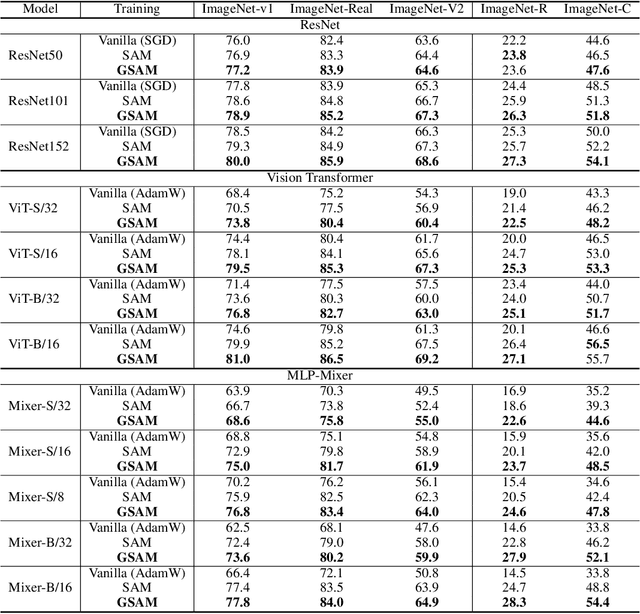


The recently proposed Sharpness-Aware Minimization (SAM) improves generalization by minimizing a \textit{perturbed loss} defined as the maximum loss within a neighborhood in the parameter space. However, we show that both sharp and flat minima can have a low perturbed loss, implying that SAM does not always prefer flat minima. Instead, we define a \textit{surrogate gap}, a measure equivalent to the dominant eigenvalue of Hessian at a local minimum when the radius of the neighborhood (to derive the perturbed loss) is small. The surrogate gap is easy to compute and feasible for direct minimization during training. Based on the above observations, we propose Surrogate \textbf{G}ap Guided \textbf{S}harpness-\textbf{A}ware \textbf{M}inimization (GSAM), a novel improvement over SAM with negligible computation overhead. Conceptually, GSAM consists of two steps: 1) a gradient descent like SAM to minimize the perturbed loss, and 2) an \textit{ascent} step in the \textit{orthogonal} direction (after gradient decomposition) to minimize the surrogate gap and yet not affect the perturbed loss. GSAM seeks a region with both small loss (by step 1) and low sharpness (by step 2), giving rise to a model with high generalization capabilities. Theoretically, we show the convergence of GSAM and provably better generalization than SAM. Empirically, GSAM consistently improves generalization (e.g., +3.2\% over SAM and +5.4\% over AdamW on ImageNet top-1 accuracy for ViT-B/32). Code is released at \url{ https://sites.google.com/view/gsam-iclr22/home}.