 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Spatio-Temporal Contrastive Learning with Self-Supervision
Paper and Code
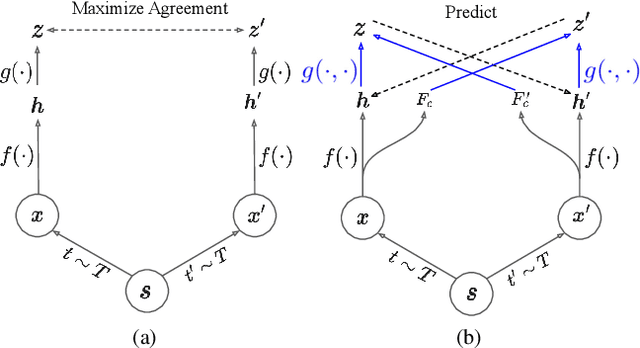
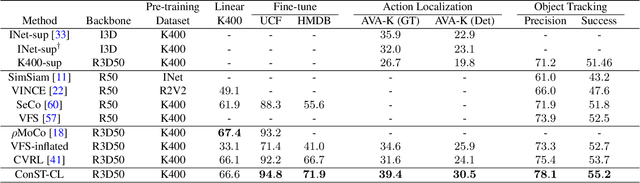
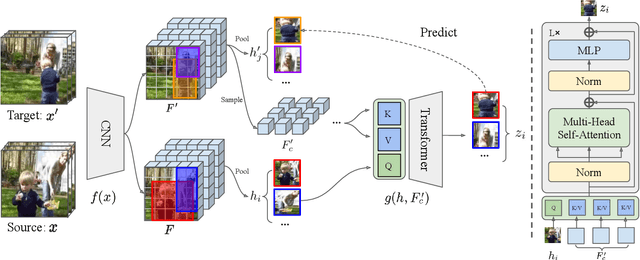
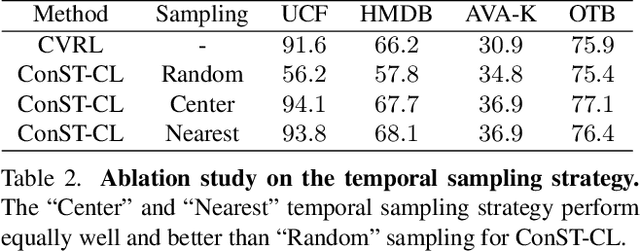
A modern self-supervised learning algorithm typically enforces persistency of the representations of an instance across views. While being very effective on learning holistic image and video representations, such an approach becomes sub-optimal for learning spatio-temporally fine-grained features in videos, where scenes and instances evolve through space and time. In this paper, we present the Contextualized Spatio-Temporal Contrastive Learning (ConST-CL) framework to effectively learn spatio-temporally fine-grained representations using self-supervision. We first design a region-based self-supervised pretext task which requires the model to learn to transform instance representations from one view to another guided by context features. Further, we introduce a simple network design that effectively reconciles the simultaneous learning process of both holistic and local representations. We evaluate our learned representations on a variety of downstream tasks and ConST-CL achieves state-of-the-art results on four datasets. For spatio-temporal action localization, ConST-CL achieves 39.4% mAP with ground-truth boxes and 30.5% mAP with detected boxes on the AVA-Kinetics validation set. For object tracking, ConST-CL achieves 78.1% precision and 55.2% success scores on OTB2015. Furthermore, ConST-CL achieves 94.8% and 71.9% top-1 fine-tuning accuracy on video action recognition datasets, UCF101 and HMDB51 respectively. We plan to release our code and models to the public.