 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject-Specific Low-Field MRI Synthesis via a Neural Operator
Mar 26, 2026Low-field (LF) magnetic resonance imaging (MRI) improves accessibility and reduces costs but generally has lower signal-to-noise ratios and degraded contrast compared to high field (HF) MRI, limiting its clinical utility. Simulating LF MRI from HF MRI enables virtual evaluation of novel imaging devices and development of LF algorithms. Existing low field simulators rely on noise injection and smoothing, which fail to capture the contrast degradation seen in LF acquisitions. To this end, we introduce an end-to-end LF-MRI synthesis framework that learns HF to LF image degradation directly from a small number of paired HF-LF MRIs. Specifically, we introduce a novel HF to LF coordinate-image decoupled neural operator (H2LO) to model the underlying degradation process, and tailor it to capture high-frequency noise textures and image structure. Experimental results in T1w and T2w MRI demonstrate that H2LO produces more faithful simulated low-field images than existing parameterized noise synthesis models and popular image-to-image translation models. Furthermore, it improves performance in downstream image enhancement tasks, showcasing its potential to enhance LF MRI diagnostic capabilities.
Surrogate Gap Minimization Improves Sharpness-Aware Training
Mar 19, 2022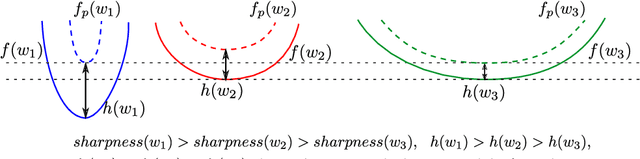
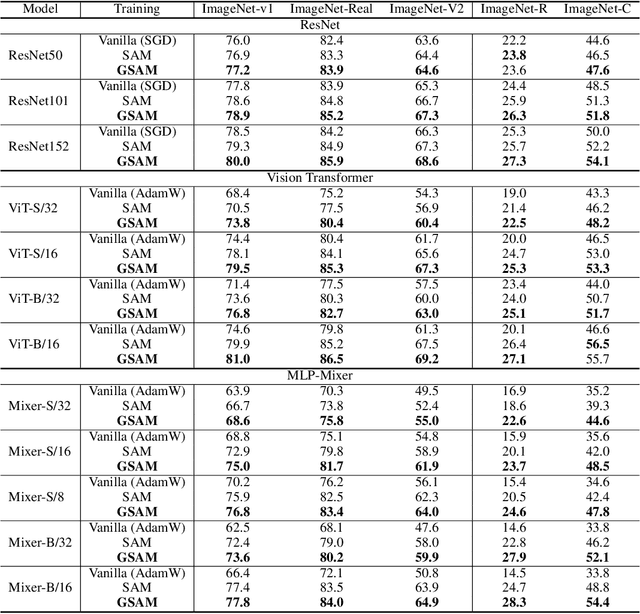


The recently proposed Sharpness-Aware Minimization (SAM) improves generalization by minimizing a \textit{perturbed loss} defined as the maximum loss within a neighborhood in the parameter space. However, we show that both sharp and flat minima can have a low perturbed loss, implying that SAM does not always prefer flat minima. Instead, we define a \textit{surrogate gap}, a measure equivalent to the dominant eigenvalue of Hessian at a local minimum when the radius of the neighborhood (to derive the perturbed loss) is small. The surrogate gap is easy to compute and feasible for direct minimization during training. Based on the above observations, we propose Surrogate \textbf{G}ap Guided \textbf{S}harpness-\textbf{A}ware \textbf{M}inimization (GSAM), a novel improvement over SAM with negligible computation overhead. Conceptually, GSAM consists of two steps: 1) a gradient descent like SAM to minimize the perturbed loss, and 2) an \textit{ascent} step in the \textit{orthogonal} direction (after gradient decomposition) to minimize the surrogate gap and yet not affect the perturbed loss. GSAM seeks a region with both small loss (by step 1) and low sharpness (by step 2), giving rise to a model with high generalization capabilities. Theoretically, we show the convergence of GSAM and provably better generalization than SAM. Empirically, GSAM consistently improves generalization (e.g., +3.2\% over SAM and +5.4\% over AdamW on ImageNet top-1 accuracy for ViT-B/32). Code is released at \url{ https://sites.google.com/view/gsam-iclr22/home}.
FedNI: Federated Graph Learning with Network Inpainting for Population-Based Disease Prediction
Dec 19, 2021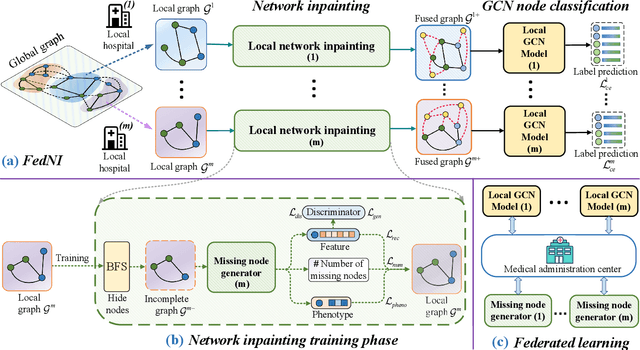


Graph Convolutional Neural Networks (GCNs) are widely used for graph analysis. Specifically, in medical applications, GCNs can be used for disease prediction on a population graph, where graph nodes represent individuals and edges represent individual similarities. However, GCNs rely on a vast amount of data, which is challenging to collect for a single medical institution. In addition, a critical challenge that most medical institutions continue to face is addressing disease prediction in isolation with incomplete data information. To address these issues, Federated Learning (FL) allows isolated local institutions to collaboratively train a global model without data sharing. In this work, we propose a framework, FedNI, to leverage network inpainting and inter-institutional data via FL. Specifically, we first federatively train missing node and edge predictor using a graph generative adversarial network (GAN) to complete the missing information of local networks. Then we train a global GCN node classifier across institutions using a federated graph learning platform. The novel design enables us to build more accurate machine learning models by leveraging federated learning and also graph learning approaches. We demonstrate that our federated model outperforms local and baseline FL methods with significant margins on two public neuroimaging datasets.
Momentum Centering and Asynchronous Update for Adaptive Gradient Methods
Oct 17, 2021
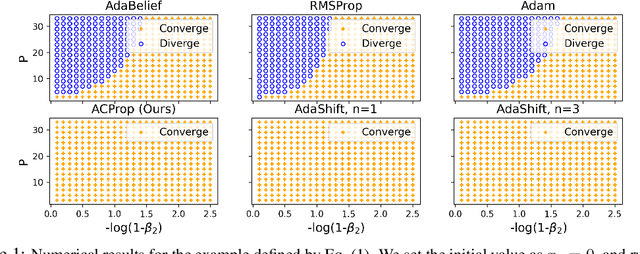
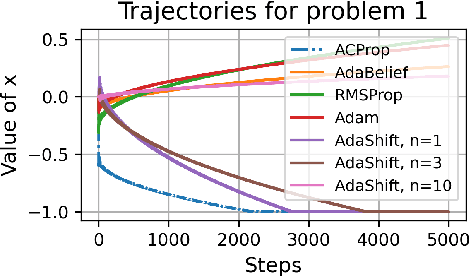
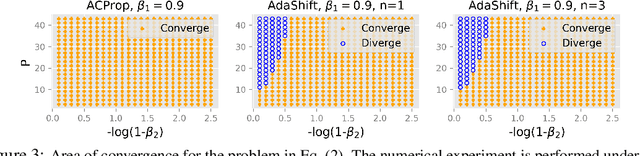
We propose ACProp (Asynchronous-centering-Prop), an adaptive optimizer which combines centering of second momentum and asynchronous update (e.g. for $t$-th update, denominator uses information up to step $t-1$, while numerator uses gradient at $t$-th step). ACProp has both strong theoretical properties and empirical performance. With the example by Reddi et al. (2018), we show that asynchronous optimizers (e.g. AdaShift, ACProp) have weaker convergence condition than synchronous optimizers (e.g. Adam, RMSProp, AdaBelief); within asynchronous optimizers, we show that centering of second momentum further weakens the convergence condition. We demonstrate that ACProp has a convergence rate of $O(\frac{1}{\sqrt{T}})$ for the stochastic non-convex case, which matches the oracle rate and outperforms the $O(\frac{logT}{\sqrt{T}})$ rate of RMSProp and Adam. We validate ACProp in extensive empirical studies: ACProp outperforms both SGD and other adaptive optimizers in image classification with CNN, and outperforms well-tuned adaptive optimizers in the training of various GAN models, reinforcement learning and transformers. To sum up, ACProp has good theoretical properties including weak convergence condition and optimal convergence rate, and strong empirical performance including good generalization like SGD and training stability like Adam. We provide the implementation at https://github.com/juntang-zhuang/ACProp-Optimizer.
Multiple-shooting adjoint method for whole-brain dynamic causal modeling
Feb 14, 2021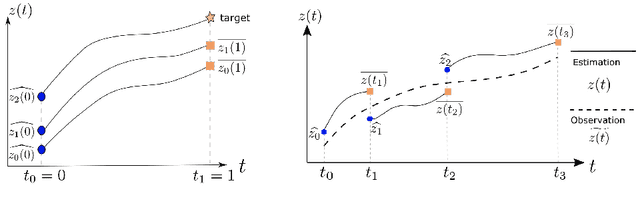

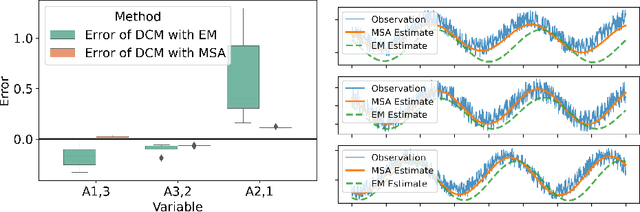
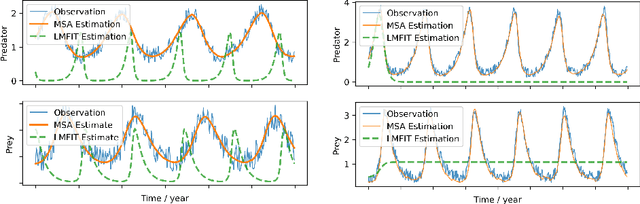
Dynamic causal modeling (DCM) is a Bayesian framework to infer directed connections between compartments, and has been used to describe the interactions between underlying neural populations based on functional neuroimaging data. DCM is typically analyzed with the expectation-maximization (EM) algorithm. However, because the inversion of a large-scale continuous system is difficult when noisy observations are present, DCM by EM is typically limited to a small number of compartments ($<10$). Another drawback with the current method is its complexity; when the forward model changes, the posterior mean changes, and we need to re-derive the algorithm for optimization. In this project, we propose the Multiple-Shooting Adjoint (MSA) method to address these limitations. MSA uses the multiple-shooting method for parameter estimation in ordinary differential equations (ODEs) under noisy observations, and is suitable for large-scale systems such as whole-brain analysis in functional MRI (fMRI). Furthermore, MSA uses the adjoint method for accurate gradient estimation in the ODE; since the adjoint method is generic, MSA is a generic method for both linear and non-linear systems, and does not require re-derivation of the algorithm as in EM. We validate MSA in extensive experiments: 1) in toy examples with both linear and non-linear models, we show that MSA achieves better accuracy in parameter value estimation than EM; furthermore, MSA can be successfully applied to large systems with up to 100 compartments; and 2) using real fMRI data, we apply MSA to the estimation of the whole-brain effective connectome and show improved classification of autism spectrum disorder (ASD) vs. control compared to using the functional connectome. The package is provided \url{https://jzkay12.github.io/TorchDiffEqPack}
AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients
Oct 24, 2020

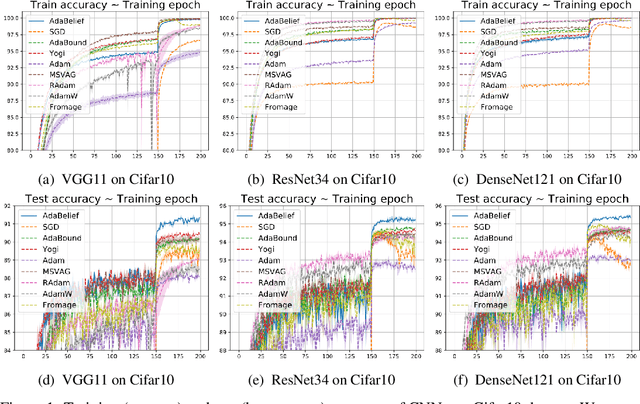

Most popular optimizers for deep learning can be broadly categorized as adaptive methods (e.g. Adam) and accelerated schemes (e.g. stochastic gradient descent (SGD) with momentum). For many models such as convolutional neural networks (CNNs), adaptive methods typically converge faster but generalize worse compared to SGD; for complex settings such as generative adversarial networks (GANs), adaptive methods are typically the default because of their stability.We propose AdaBelief to simultaneously achieve three goals: fast convergence as in adaptive methods, good generalization as in SGD, and training stability. The intuition for AdaBelief is to adapt the stepsize according to the "belief" in the current gradient direction. Viewing the exponential moving average (EMA) of the noisy gradient as the prediction of the gradient at the next time step, if the observed gradient greatly deviates from the prediction, we distrust the current observation and take a small step; if the observed gradient is close to the prediction, we trust it and take a large step. We validate AdaBelief in extensive experiments, showing that it outperforms other methods with fast convergence and high accuracy on image classification and language modeling. Specifically, on ImageNet, AdaBelief achieves comparable accuracy to SGD. Furthermore, in the training of a GAN on Cifar10, AdaBelief demonstrates high stability and improves the quality of generated samples compared to a well-tuned Adam optimizer. Code is available at https://github.com/juntang-zhuang/Adabelief-Optimizer
Adaptive Checkpoint Adjoint Method for Gradient Estimation in Neural ODE
Jun 03, 2020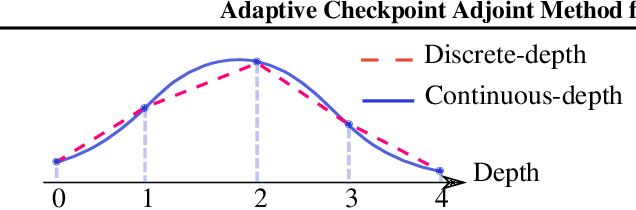
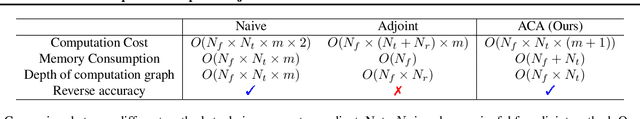


Neural ordinary differential equations (NODEs) have recently attracted increasing attention; however, their empirical performance on benchmark tasks (e.g. image classification) are significantly inferior to discrete-layer models. We demonstrate an explanation for their poorer performance is the inaccuracy of existing gradient estimation methods: the adjoint method has numerical errors in reverse-mode integration; the naive method directly back-propagates through ODE solvers, but suffers from a redundantly deep computation graph when searching for the optimal stepsize. We propose the Adaptive Checkpoint Adjoint (ACA) method: in automatic differentiation, ACA applies a trajectory checkpoint strategy which records the forward-mode trajectory as the reverse-mode trajectory to guarantee accuracy; ACA deletes redundant components for shallow computation graphs; and ACA supports adaptive solvers. On image classification tasks, compared with the adjoint and naive method, ACA achieves half the error rate in half the training time; NODE trained with ACA outperforms ResNet in both accuracy and test-retest reliability. On time-series modeling, ACA outperforms competing methods. Finally, in an example of the three-body problem, we show NODE with ACA can incorporate physical knowledge to achieve better accuracy. We provide the PyTorch implementation of ACA: \url{https://github.com/juntang-zhuang/torch-ACA}.
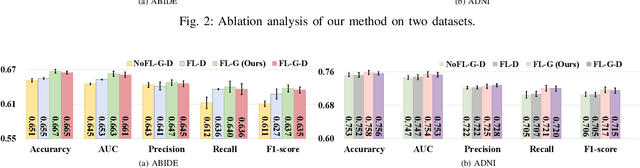
Multi-site fMRI Analysis Using Privacy-preserving Federated Learning and Domain Adaptation: ABIDE Results
Jan 16, 2020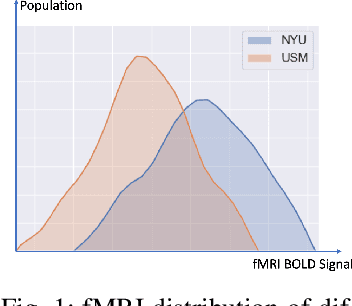
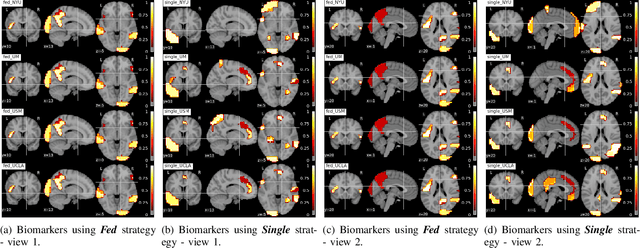
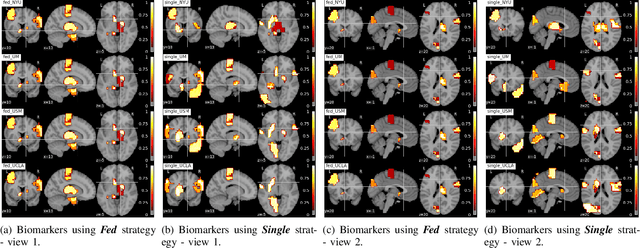
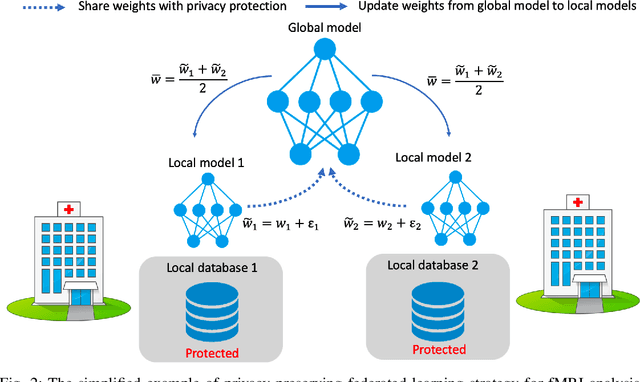
Deep learning models have shown their advantage in many different tasks, including neuroimage analysis. However, to effectively train a high-quality deep learning model, the aggregation of a significant amount of patient information is required. The time and cost for acquisition and annotation in assembling, for example, large fMRI datasets make it difficult to acquire large numbers at a single site. However, due to the need to protect the privacy of patient data, it is hard to assemble a central database from multiple institutions. Federated learning allows for population-level models to be trained without centralizing entities' data by transmitting the global model to local entities, training the model locally, and then averaging the gradients or weights in the global model. However, some studies suggest that private information can be recovered from the model gradients or weights. In this work, we address the problem of multi-site fMRI classification with a privacy-preserving strategy. To solve the problem, we propose a federated learning approach, where a decentralized iterative optimization algorithm is implemented and shared local model weights are altered by a randomization mechanism. Considering the systemic differences of fMRI distributions from different sites, we further propose two domain adaptation methods in this federated learning formulation. We investigate various practical aspects of federated model optimization and compare federated learning with alternative training strategies. Overall, our results demonstrate that it is promising to utilize multi-site data without data sharing to boost neuroimage analysis performance and find reliable disease-related biomarkers. Our proposed pipeline can be generalized to other privacy-sensitive medical data analysis problems.