 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
May 11, 2026In industrial procurement, an LLM answer is useful only if it survives a standards check: recommended material must match operating condition, every parameter must respect a regulated threshold, and no procedure may contradict a safety clause. Partial correctness can mask safety-critical contradictions that aggregate LLM benchmarks rarely capture. We introduce IndustryBench, a 2,049-item benchmark for industrial procurement QA in Chinese, grounded in Chinese national standards (GB/T) and structured industrial product records, organized by seven capability dimensions, ten industry categories, and panel-derived difficulty tiers, with item-aligned English, Russian, and Vietnamese renderings. Our construction pipeline rejects 70.3% of LLM-generated candidates at a search-based external-verification stage, calibrating how unreliable industrial QA remains after LLM-only filtering.Our evaluation decouples raw correctness, scored by a Qwen3-Max judge validated at $κ_w = 0.798$ against a domain expert, from a separate safety-violation (SV) check against source texts. Across 17 models in Chinese and an 8-model intersection over four languages, we find: (i) the best system reaches only 2.083 on the 0--3 rubric, leaving substantial headroom; (ii) Standards & Terminology is the most persistent capability weakness and survives item-aligned translation; (iii) extended reasoning lowers safety-adjusted scores for 12 of 13 models, primarily by introducing unsupported safety-critical details into longer final answers; and (iv) safety-violation rates reshuffle the leaderboard -- GPT-5.4 climbs from rank 6 to rank 3 after SV adjustment, while Kimi-k2.5-1T-A32B drops seven positions.Industrial LLM evaluation therefore requires source-grounded, safety-aware diagnosis rather than aggregate accuracy. We release IndustryBench with all prompts, scoring scripts, and dataset documentation.
FlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
Apr 08, 2026Multimodal generation has long been dominated by text-driven pipelines where language dictates vision but cannot reason or create within it. We challenge this paradigm by asking whether all modalities, including textual descriptions, spatial layouts, and editing instructions, can be unified into a single visual representation. We present FlowInOne, a framework that reformulates multimodal generation as a purely visual flow, converting all inputs into visual prompts and enabling a clean image-in, image-out pipeline governed by a single flow matching model. This vision-centric formulation naturally eliminates cross-modal alignment bottlenecks, noise scheduling, and task-specific architectural branches, unifying text-to-image generation, layout-guided editing, and visual instruction following under one coherent paradigm. To support this, we introduce VisPrompt-5M, a large-scale dataset of 5 million visual prompt pairs spanning diverse tasks including physics-aware force dynamics and trajectory prediction, alongside VP-Bench, a rigorously curated benchmark assessing instruction faithfulness, spatial precision, visual realism, and content consistency. Extensive experiments demonstrate that FlowInOne achieves state-of-the-art performance across all unified generation tasks, surpassing both open-source models and competitive commercial systems, establishing a new foundation for fully vision-centric generative modeling where perception and creation coexist within a single continuous visual space.
Graph Smoothing for Enhanced Local Geometry Learning in Point Cloud Analysis
Jan 16, 2026Graph-based methods have proven to be effective in capturing relationships among points for 3D point cloud analysis. However, these methods often suffer from suboptimal graph structures, particularly due to sparse connections at boundary points and noisy connections in junction areas. To address these challenges, we propose a novel method that integrates a graph smoothing module with an enhanced local geometry learning module. Specifically, we identify the limitations of conventional graph structures, particularly in handling boundary points and junction areas. In response, we introduce a graph smoothing module designed to optimize the graph structure and minimize the negative impact of unreliable sparse and noisy connections. Based on the optimized graph structure, we improve the feature extract function with local geometry information. These include shape features derived from adaptive geometric descriptors based on eigenvectors and distribution features obtained through cylindrical coordinate transformation. Experimental results on real-world datasets validate the effectiveness of our method in various point cloud learning tasks, i.e., classification, part segmentation, and semantic segmentation.
Global-Graph Guided and Local-Graph Weighted Contrastive Learning for Unified Clustering on Incomplete and Noise Multi-View Data
Dec 25, 2025Recently, contrastive learning (CL) plays an important role in exploring complementary information for multi-view clustering (MVC) and has attracted increasing attention. Nevertheless, real-world multi-view data suffer from data incompleteness or noise, resulting in rare-paired samples or mis-paired samples which significantly challenges the effectiveness of CL-based MVC. That is, rare-paired issue prevents MVC from extracting sufficient multi-view complementary information, and mis-paired issue causes contrastive learning to optimize the model in the wrong direction. To address these issues, we propose a unified CL-based MVC framework for enhancing clustering effectiveness on incomplete and noise multi-view data. First, to overcome the rare-paired issue, we design a global-graph guided contrastive learning, where all view samples construct a global-view affinity graph to form new sample pairs for fully exploring complementary information. Second, to mitigate the mis-paired issue, we propose a local-graph weighted contrastive learning, which leverages local neighbors to generate pair-wise weights to adaptively strength or weaken the pair-wise contrastive learning. Our method is imputation-free and can be integrated into a unified global-local graph-guided contrastive learning framework. Extensive experiments on both incomplete and noise settings of multi-view data demonstrate that our method achieves superior performance compared with state-of-the-art approaches.
Missing Pattern Tree based Decision Grouping and Ensemble for Deep Incomplete Multi-View Clustering
Dec 25, 2025Real-world multi-view data usually exhibits highly inconsistent missing patterns which challenges the effectiveness of incomplete multi-view clustering (IMVC). Although existing IMVC methods have made progress from both imputation-based and imputation-free routes, they have overlooked the pair under-utilization issue, i.e., inconsistent missing patterns make the incomplete but available multi-view pairs unable to be fully utilized, thereby limiting the model performance. To address this, we propose a novel missing-pattern tree based IMVC framework entitled TreeEIC. Specifically, to achieve full exploitation of available multi-view pairs, TreeEIC first defines the missing-pattern tree model to group data into multiple decision sets according to different missing patterns, and then performs multi-view clustering within each set. Furthermore, a multi-view decision ensemble module is proposed to aggregate clustering results from all decision sets, which infers uncertainty-based weights to suppress unreliable clustering decisions and produce robust decisions. Finally, an ensemble-to-individual knowledge distillation module transfers the ensemble knowledge to view-specific clustering models, which enables ensemble and individual modules to promote each other by optimizing cross-view consistency and inter-cluster discrimination losses. Extensive experiments on multiple benchmark datasets demonstrate that our TreeEIC achieves state-of-the-art IMVC performance and exhibits superior robustness under highly inconsistent missing patterns.
Cross-modal Prompting for Balanced Incomplete Multi-modal Emotion Recognition
Dec 12, 2025Incomplete multi-modal emotion recognition (IMER) aims at understanding human intentions and sentiments by comprehensively exploring the partially observed multi-source data. Although the multi-modal data is expected to provide more abundant information, the performance gap and modality under-optimization problem hinder effective multi-modal learning in practice, and are exacerbated in the confrontation of the missing data. To address this issue, we devise a novel Cross-modal Prompting (ComP) method, which emphasizes coherent information by enhancing modality-specific features and improves the overall recognition accuracy by boosting each modality's performance. Specifically, a progressive prompt generation module with a dynamic gradient modulator is proposed to produce concise and consistent modality semantic cues. Meanwhile, cross-modal knowledge propagation selectively amplifies the consistent information in modality features with the delivered prompts to enhance the discrimination of the modality-specific output. Additionally, a coordinator is designed to dynamically re-weight the modality outputs as a complement to the balance strategy to improve the model's efficacy. Extensive experiments on 4 datasets with 7 SOTA methods under different missing rates validate the effectiveness of our proposed method.
Agentic Meta-Orchestrator for Multi-task Copilots
Oct 26, 2025Microsoft Copilot suites serve as the universal entry point for various agents skilled in handling important tasks, ranging from assisting a customer with product purchases to detecting vulnerabilities in corporate programming code. Each agent can be powered by language models, software engineering operations, such as database retrieval, and internal \& external knowledge. The repertoire of a copilot can expand dynamically with new agents. This requires a robust orchestrator that can distribute tasks from user prompts to the right agents. In this work, we propose an Agentic Meta-orchestrator (AMO) for handling multiple tasks and scalable agents in copilot services, which can provide both natural language and action responses. We will also demonstrate the planning that leverages meta-learning, i.e., a trained decision tree model for deciding the best inference strategy among various agents/models. We showcase the effectiveness of our AMO through two production use cases: Microsoft 365 (M365) E-Commerce Copilot and code compliance copilot. M365 E-Commerce Copilot advertises Microsoft products to external customers to promote sales success. The M365 E-Commerce Copilot provides up-to-date product information and connects to multiple agents, such as relational databases and human customer support. The code compliance copilot scans the internal DevOps code to detect known and new compliance issues in pull requests (PR).
LRR-Bench: Left, Right or Rotate? Vision-Language models Still Struggle With Spatial Understanding Tasks
Jul 27, 2025Real-world applications, such as autonomous driving and humanoid robot manipulation, require precise spatial perception. However, it remains underexplored how Vision-Language Models (VLMs) recognize spatial relationships and perceive spatial movement. In this work, we introduce a spatial evaluation pipeline and construct a corresponding benchmark. Specifically, we categorize spatial understanding into two main types: absolute spatial understanding, which involves querying the absolute spatial position (e.g., left, right) of an object within an image, and 3D spatial understanding, which includes movement and rotation. Notably, our dataset is entirely synthetic, enabling the generation of test samples at a low cost while also preventing dataset contamination. We conduct experiments on multiple state-of-the-art VLMs and observe that there is significant room for improvement in their spatial understanding abilities. Explicitly, in our experiments, humans achieve near-perfect performance on all tasks, whereas current VLMs attain human-level performance only on the two simplest tasks. For the remaining tasks, the performance of VLMs is distinctly lower than that of humans. In fact, the best-performing Vision-Language Models even achieve near-zero scores on multiple tasks. The dataset and code are available on https://github.com/kong13661/LRR-Bench.
Rethinking Range-View LiDAR Segmentation in Adverse Weather
Jun 10, 2025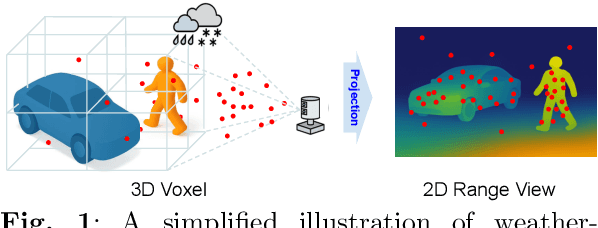
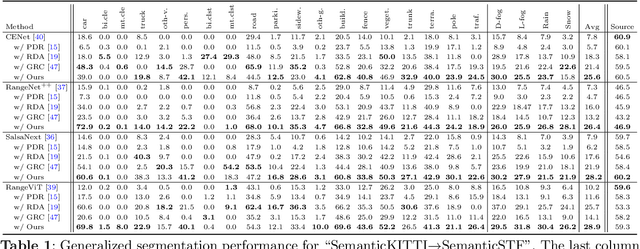
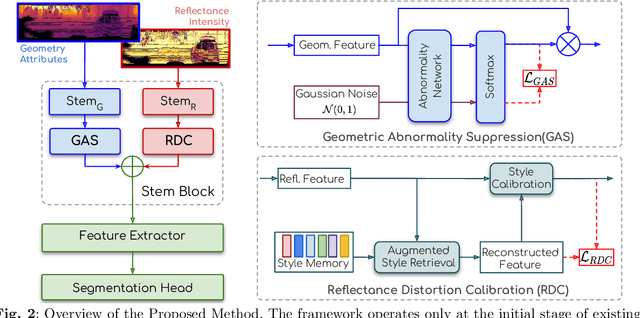
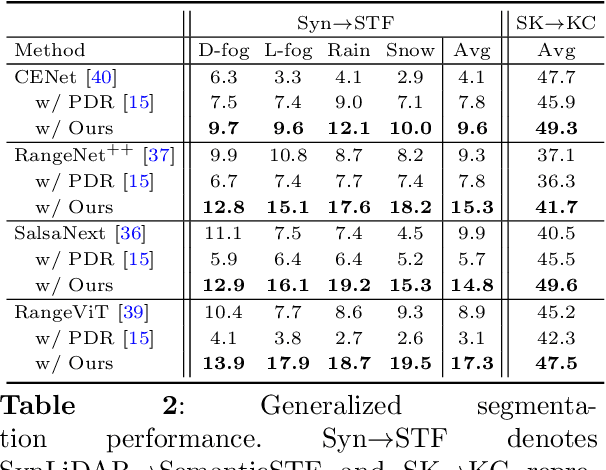
LiDAR segmentation has emerged as an important task to enrich multimedia experiences and analysis. Range-view-based methods have gained popularity due to their high computational efficiency and compatibility with real-time deployment. However, their generalized performance under adverse weather conditions remains underexplored, limiting their reliability in real-world environments. In this work, we identify and analyze the unique challenges that affect the generalization of range-view LiDAR segmentation in severe weather. To address these challenges, we propose a modular and lightweight framework that enhances robustness without altering the core architecture of existing models. Our method reformulates the initial stem block of standard range-view networks into two branches to process geometric attributes and reflectance intensity separately. Specifically, a Geometric Abnormality Suppression (GAS) module reduces the influence of weather-induced spatial noise, and a Reflectance Distortion Calibration (RDC) module corrects reflectance distortions through memory-guided adaptive instance normalization. The processed features are then fused and passed to the original segmentation pipeline. Extensive experiments on different benchmarks and baseline models demonstrate that our approach significantly improves generalization to adverse weather with minimal inference overhead, offering a practical and effective solution for real-world LiDAR segmentation.
The Final Layer Holds the Key: A Unified and Efficient GNN Calibration Framework
May 16, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable effectiveness on graph-based tasks. However, their predictive confidence is often miscalibrated, typically exhibiting under-confidence, which harms the reliability of their decisions. Existing calibration methods for GNNs normally introduce additional calibration components, which fail to capture the intrinsic relationship between the model and the prediction confidence, resulting in limited theoretical guarantees and increased computational overhead. To address this issue, we propose a simple yet efficient graph calibration method. We establish a unified theoretical framework revealing that model confidence is jointly governed by class-centroid-level and node-level calibration at the final layer. Based on this insight, we theoretically show that reducing the weight decay of the final-layer parameters alleviates GNN under-confidence by acting on the class-centroid level, while node-level calibration acts as a finer-grained complement to class-centroid level calibration, which encourages each test node to be closer to its predicted class centroid at the final-layer representations. Extensive experiments validate the superiority of our method.