 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Interpret and Leverage Structured Linguistic Representations? A Case Study with AMRs
Paper and Code
Apr 07, 2025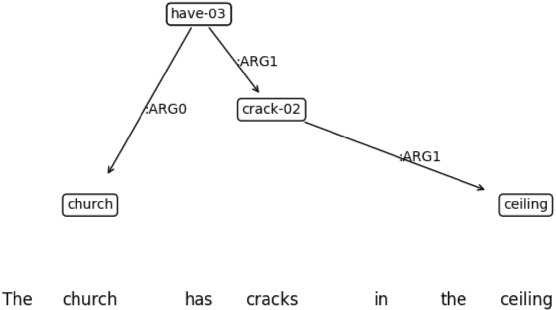
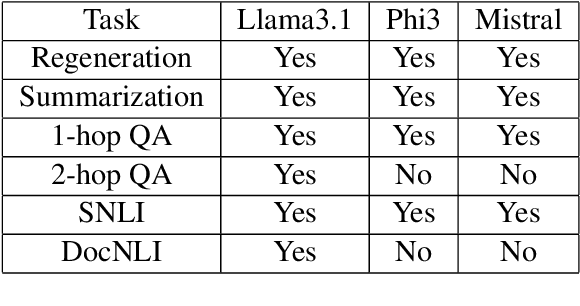
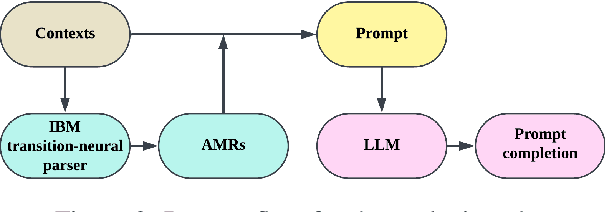
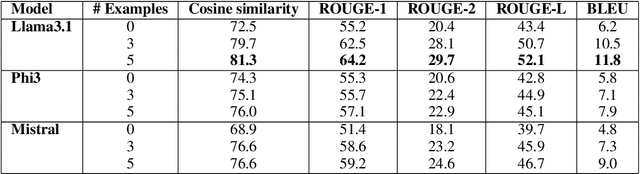
This paper evaluates the ability of Large Language Models (LLMs) to leverage contextual information in the form of structured linguistic representations. Specifically, we examine the impact of encoding both short and long contexts using Abstract Meaning Representation (AMR) structures across a diverse set of language tasks. We perform our analysis using 8-bit quantized and instruction-tuned versions of Llama 3.1 (8B), Phi-3, and Mistral 7B. Our results indicate that, for tasks involving short contexts, augmenting the prompt with the AMR of the original language context often degrades the performance of the underlying LLM. However, for tasks that involve long contexts, such as dialogue summarization in the SAMSum dataset, this enhancement improves LLM performance, for example, by increasing the zero-shot cosine similarity score of Llama 3.1 from 66.2% to 76%. This improvement is more evident in the newer and larger LLMs, but does not extend to the older or smaller ones. In addition, we observe that LLMs can effectively reconstruct the original text from a linearized AMR, achieving a cosine similarity of 81.3% in the best-case scenario.