 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
Navigating Semantic Drift in Task-Agnostic Class-Incremental Learning
Feb 11, 2025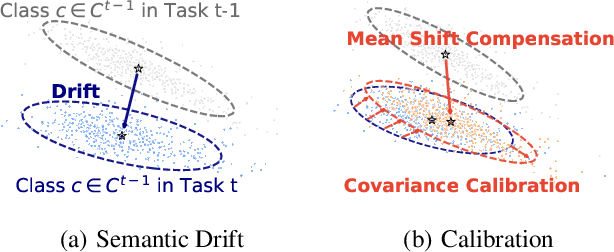
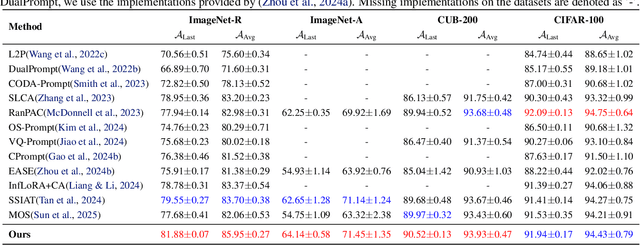
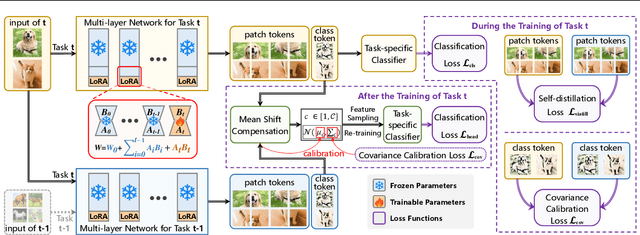
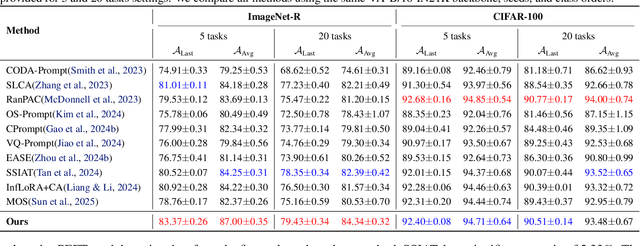
Class-incremental learning (CIL) seeks to enable a model to sequentially learn new classes while retaining knowledge of previously learned ones. Balancing flexibility and stability remains a significant challenge, particularly when the task ID is unknown. To address this, our study reveals that the gap in feature distribution between novel and existing tasks is primarily driven by differences in mean and covariance moments. Building on this insight, we propose a novel semantic drift calibration method that incorporates mean shift compensation and covariance calibration. Specifically, we calculate each class's mean by averaging its sample embeddings and estimate task shifts using weighted embedding changes based on their proximity to the previous mean, effectively capturing mean shifts for all learned classes with each new task. We also apply Mahalanobis distance constraint for covariance calibration, aligning class-specific embedding covariances between old and current networks to mitigate the covariance shift. Additionally, we integrate a feature-level self-distillation approach to enhance generalization. Comprehensive experiments on commonly used datasets demonstrate the effectiveness of our approach. The source code is available at \href{https://github.com/fwu11/MACIL.git}{https://github.com/fwu11/MACIL.git}.
Masked Collaborative Contrast for Weakly Supervised Semantic Segmentation
May 19, 2023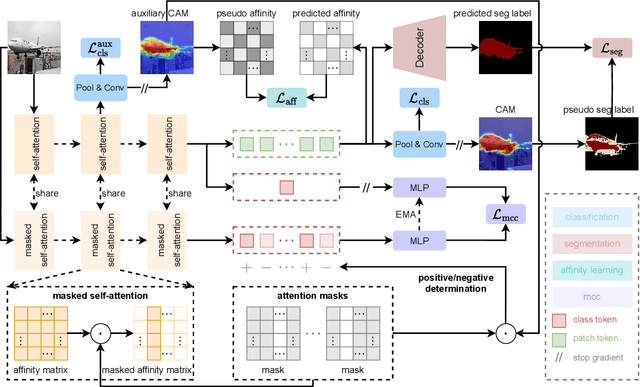
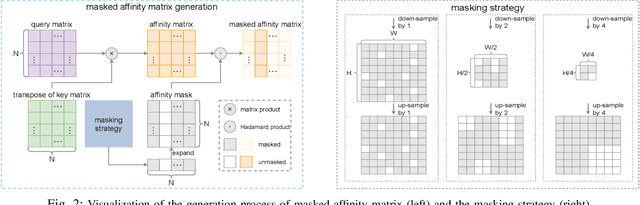
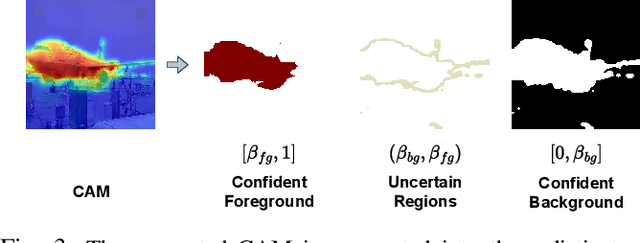
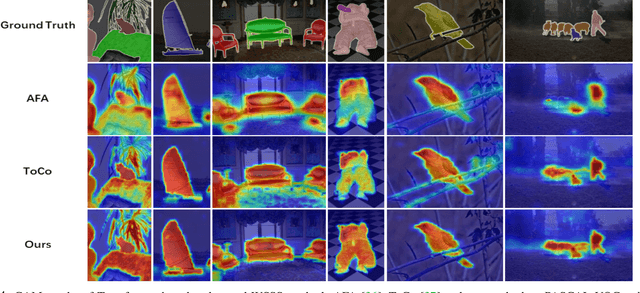
This study introduces an efficacious approach, Masked Collaborative Contrast (MCC), to emphasize semantic regions in weakly supervised semantic segmentation. MCC adroitly incorporates concepts from masked image modeling and contrastive learning to devise Transformer blocks that induce keys to contract towards semantically pertinent regions. Unlike prevalent techniques that directly eradicate patch regions in the input image when generating masks, we scrutinize the neighborhood relations of patch tokens by exploring masks considering keys on the affinity matrix. Moreover, we generate positive and negative samples in contrastive learning by utilizing the masked local output and contrasting it with the global output. Elaborate experiments on commonly employed datasets evidences that the proposed MCC mechanism effectively aligns global and local perspectives within the image, attaining impressive performance. The source code is available at \url{https://github.com/fwu11/MCC}.