 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeGround: Know When to Trust GUI Grounding Models via Uncertainty Calibration
Feb 03, 2026Graphical User Interface (GUI) grounding aims to translate natural language instructions into executable screen coordinates, enabling automated GUI interaction. Nevertheless, incorrect grounding can result in costly, hard-to-reverse actions (e.g., erroneous payment approvals), raising concerns about model reliability. In this paper, we introduce SafeGround, an uncertainty-aware framework for GUI grounding models that enables risk-aware predictions through calibrations before testing. SafeGround leverages a distribution-aware uncertainty quantification method to capture the spatial dispersion of stochastic samples from outputs of any given model. Then, through the calibration process, SafeGround derives a test-time decision threshold with statistically guaranteed false discovery rate (FDR) control. We apply SafeGround on multiple GUI grounding models for the challenging ScreenSpot-Pro benchmark. Experimental results show that our uncertainty measure consistently outperforms existing baselines in distinguishing correct from incorrect predictions, while the calibrated threshold reliably enables rigorous risk control and potentials of substantial system-level accuracy improvements. Across multiple GUI grounding models, SafeGround improves system-level accuracy by up to 5.38% percentage points over Gemini-only inference.
SConU: Selective Conformal Uncertainty in Large Language Models
Apr 19, 2025As large language models are increasingly utilized in real-world applications, guarantees of task-specific metrics are essential for their reliable deployment. Previous studies have introduced various criteria of conformal uncertainty grounded in split conformal prediction, which offer user-specified correctness coverage. However, existing frameworks often fail to identify uncertainty data outliers that violate the exchangeability assumption, leading to unbounded miscoverage rates and unactionable prediction sets. In this paper, we propose a novel approach termed Selective Conformal Uncertainty (SConU), which, for the first time, implements significance tests, by developing two conformal p-values that are instrumental in determining whether a given sample deviates from the uncertainty distribution of the calibration set at a specific manageable risk level. Our approach not only facilitates rigorous management of miscoverage rates across both single-domain and interdisciplinary contexts, but also enhances the efficiency of predictions. Furthermore, we comprehensively analyze the components of the conformal procedures, aiming to approximate conditional coverage, particularly in high-stakes question-answering tasks.
LongVALE: Vision-Audio-Language-Event Benchmark Towards Time-Aware Omni-Modal Perception of Long Videos
Nov 29, 2024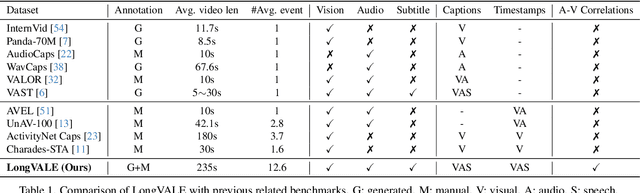
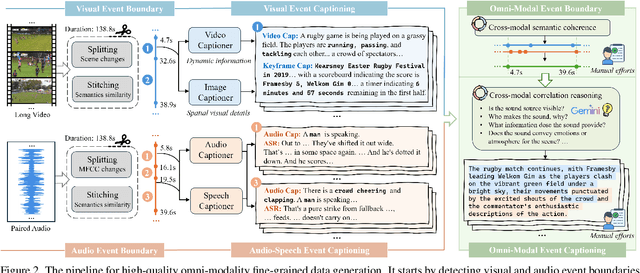
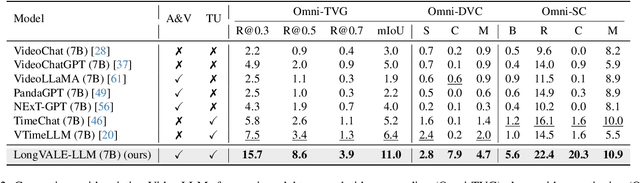
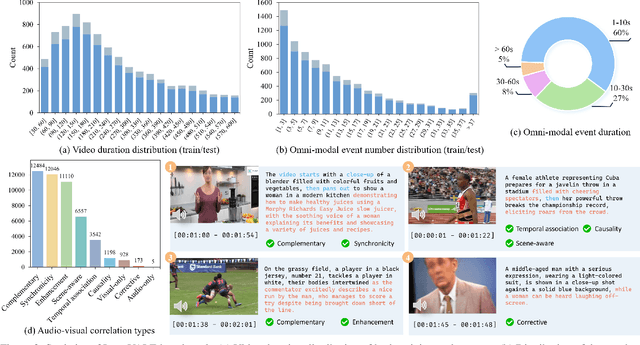
Despite impressive advancements in video understanding, most efforts remain limited to coarse-grained or visual-only video tasks. However, real-world videos encompass omni-modal information (vision, audio, and speech) with a series of events forming a cohesive storyline. The lack of multi-modal video data with fine-grained event annotations and the high cost of manual labeling are major obstacles to comprehensive omni-modality video perception. To address this gap, we propose an automatic pipeline consisting of high-quality multi-modal video filtering, semantically coherent omni-modal event boundary detection, and cross-modal correlation-aware event captioning. In this way, we present LongVALE, the first-ever Vision-Audio-Language Event understanding benchmark comprising 105K omni-modal events with precise temporal boundaries and detailed relation-aware captions within 8.4K high-quality long videos. Further, we build a baseline that leverages LongVALE to enable video large language models (LLMs) for omni-modality fine-grained temporal video understanding for the first time. Extensive experiments demonstrate the effectiveness and great potential of LongVALE in advancing comprehensive multi-modal video understanding.
Sample then Identify: A General Framework for Risk Control and Assessment in Multimodal Large Language Models
Oct 10, 2024



Multimodal Large Language Models (MLLMs) exhibit promising advancements across various tasks, yet they still encounter significant trustworthiness issues. Prior studies apply Split Conformal Prediction (SCP) in language modeling to construct prediction sets with statistical guarantees. However, these methods typically rely on internal model logits or are restricted to multiple-choice settings, which hampers their generalizability and adaptability in dynamic, open-ended environments. In this paper, we introduce TRON, a two-step framework for risk control and assessment, applicable to any MLLM that supports sampling in both open-ended and closed-ended scenarios. TRON comprises two main components: (1) a novel conformal score to sample response sets of minimum size, and (2) a nonconformity score to identify high-quality responses based on self-consistency theory, controlling the error rates by two specific risk levels. Furthermore, we investigate semantic redundancy in prediction sets within open-ended contexts for the first time, leading to a promising evaluation metric for MLLMs based on average set size. Our comprehensive experiments across four Video Question-Answering (VideoQA) datasets utilizing eight MLLMs show that TRON achieves desired error rates bounded by two user-specified risk levels. Additionally, deduplicated prediction sets maintain adaptiveness while being more efficient and stable for risk assessment under different risk levels.
ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
Jun 29, 2024



Uncertainty quantification (UQ) in natural language generation (NLG) tasks remains an open challenge, exacerbated by the intricate nature of the recent large language models (LLMs). This study investigates adapting conformal prediction (CP), which can convert any heuristic measure of uncertainty into rigorous theoretical guarantees by constructing prediction sets, for black-box LLMs in open-ended NLG tasks. We propose a sampling-based uncertainty measure leveraging self-consistency and develop a conformal uncertainty criterion by integrating the uncertainty condition aligned with correctness into the design of the CP algorithm. Experimental results indicate that our uncertainty measure generally surpasses prior state-of-the-art methods. Furthermore, we calibrate the prediction sets within the model's unfixed answer distribution and achieve strict control over the correctness coverage rate across 6 LLMs on 4 free-form NLG datasets, spanning general-purpose and medical domains, while the small average set size further highlights the efficiency of our method in providing trustworthy guarantees for practical open-ended NLG applications.