 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reddit to Generative AI: Evaluating Large Language Models for Anxiety Support Fine-tuned on Social Media Data
May 24, 2025The growing demand for accessible mental health support, compounded by workforce shortages and logistical barriers, has led to increased interest in utilizing Large Language Models (LLMs) for scalable and real-time assistance. However, their use in sensitive domains such as anxiety support remains underexamined. This study presents a systematic evaluation of LLMs (GPT and Llama) for their potential utility in anxiety support by using real user-generated posts from the r/Anxiety subreddit for both prompting and fine-tuning. Our approach utilizes a mixed-method evaluation framework incorporating three main categories of criteria: (i) linguistic quality, (ii) safety and trustworthiness, and (iii) supportiveness. Results show that fine-tuning LLMs with naturalistic anxiety-related data enhanced linguistic quality but increased toxicity and bias, and diminished emotional responsiveness. While LLMs exhibited limited empathy, GPT was evaluated as more supportive overall. Our findings highlight the risks of fine-tuning LLMs on unprocessed social media content without mitigation strategies.
Trustful LLMs: Customizing and Grounding Text Generation with Knowledge Bases and Dual Decoders
Nov 13, 2024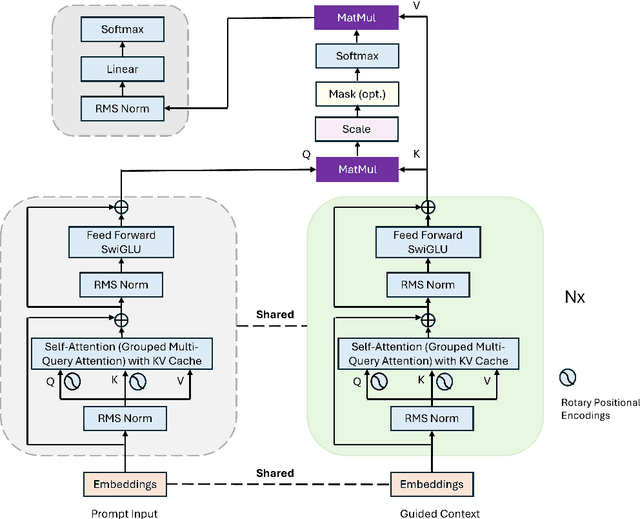
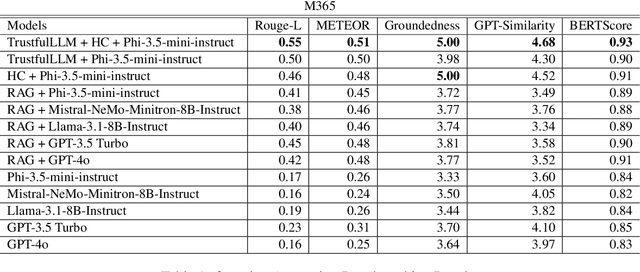
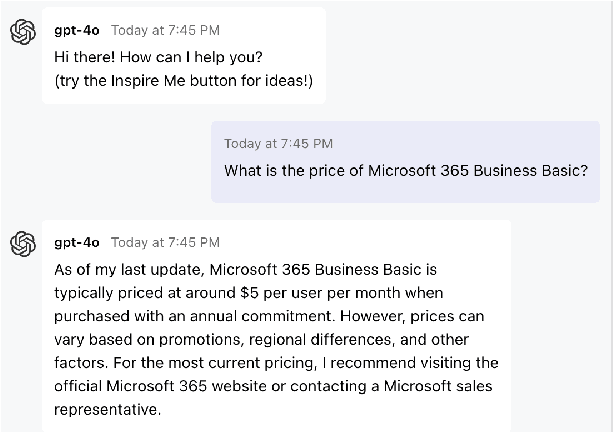
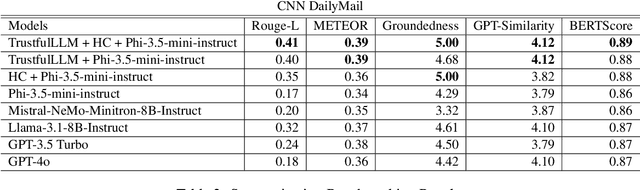
Although people are impressed by the content generation skills of large language models, the use of LLMs, such as ChatGPT, is limited by the domain grounding of the content. The correctness and groundedness of the generated content need to be based on a verified context, such as results from Retrieval-Augmented Generation (RAG). One important issue when adapting LLMs to a customized domain is that the generated responses are often incomplete, or the additions are not verified and may even be hallucinated. Prior studies on hallucination detection have focused on evaluation metrics, which are not easily adaptable to dynamic domains and can be vulnerable to attacks like jail-breaking. In this work, we propose 1) a post-processing algorithm that leverages knowledge triplets in RAG context to correct hallucinations and 2) a dual-decoder model that fuses RAG context to guide the generation process.
Deep Active Learning Using Barlow Twins
Dec 30, 2022



The generalisation performance of a convolutional neural networks (CNN) is majorly predisposed by the quantity, quality, and diversity of the training images. All the training data needs to be annotated in-hand before, in many real-world applications data is easy to acquire but expensive and time-consuming to label. The goal of the Active learning for the task is to draw most informative samples from the unlabeled pool which can used for training after annotation. With total different objective, self-supervised learning which have been gaining meteoric popularity by closing the gap in performance with supervised methods on large computer vision benchmarks. self-supervised learning (SSL) these days have shown to produce low-level representations that are invariant to distortions of the input sample and can encode invariance to artificially created distortions, e.g. rotation, solarization, cropping etc. self-supervised learning (SSL) approaches rely on simpler and more scalable frameworks for learning. In this paper, we unify these two families of approaches from the angle of active learning using self-supervised learning mainfold and propose Deep Active Learning using BarlowTwins(DALBT), an active learning method for all the datasets using combination of classifier trained along with self-supervised loss framework of Barlow Twins to a setting where the model can encode the invariance of artificially created distortions, e.g. rotation, solarization, cropping etc.
Real-time Interface Control with Motion Gesture Recognition based on Non-contact Capacitive Sensing
Jan 05, 2022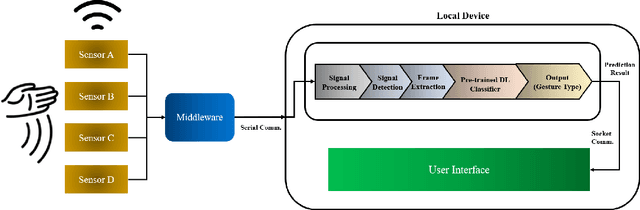
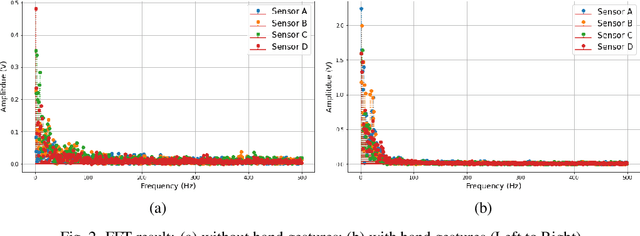
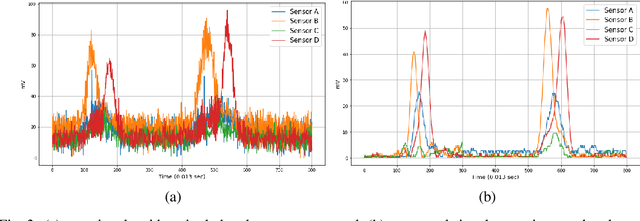
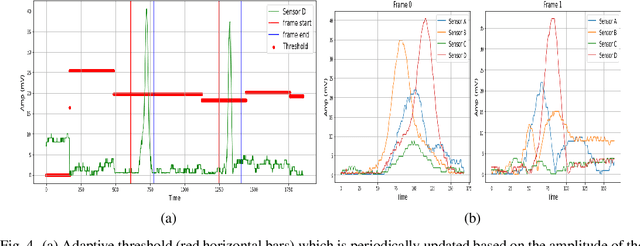
Capacitive sensing is a prominent technology that is cost-effective and low power consuming with fast recognition speed compared to existing sensing systems. On account of these advantages, Capacitive sensing has been widely studied and commercialized in the domains of touch sensing, localization, existence detection, and contact sensing interface application such as human-computer interaction. However, as a non-contact proximity sensing scheme is easily affected by the disturbance of peripheral objects or surroundings, it requires considerable sensitive data processing than contact sensing, limiting the use of its further utilization. In this paper, we propose a real-time interface control framework based on non-contact hand motion gesture recognition through processing the raw signals, detecting the electric field disturbance triggered by the hand gesture movements near the capacitive sensor using adaptive threshold, and extracting the significant signal frame, covering the authentic signal intervals with 98.8% detection rate and 98.4% frame correction rate. Through the GRU model trained with the extracted signal frame, we classify the 10 hand motion gesture types with 98.79% accuracy. The framework transmits the classification result and maneuvers the interface of the foreground process depending on the input. This study suggests the feasibility of intuitive interface technology, which accommodates the flexible interaction between human to machine similar to Natural User Interface, and uplifts the possibility of commercialization based on measuring the electric field disturbance through non-contact proximity sensing which is state-of-the-art sensing technology.
Domain Agnostic Few-Shot Learning For Document Intelligence
Oct 29, 2021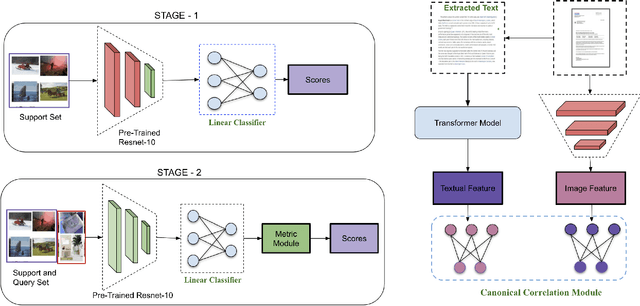
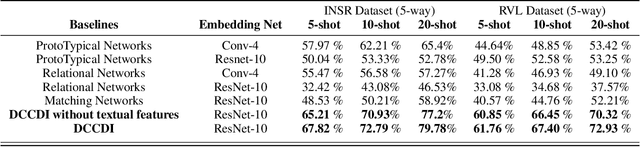

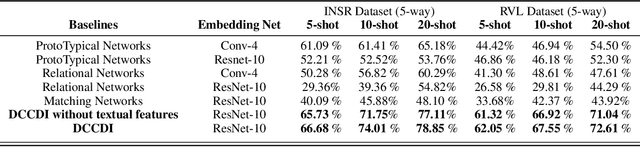
Few-shot learning aims to generalize to novel classes with only a few samples with class labels. Research in few-shot learning has borrowed techniques from transfer learning, metric learning, meta-learning, and Bayesian methods. These methods also aim to train models from limited training samples, and while encouraging performance has been achieved, they often fail to generalize to novel domains. Many of the existing meta-learning methods rely on training data for which the base classes are sampled from the same domain as the novel classes used for meta-testing. However, in many applications in the industry, such as document classification, collecting large samples of data for meta-learning is infeasible or impossible. While research in the field of the cross-domain few-shot learning exists, it is mostly limited to computer vision. To our knowledge, no work yet exists that examines the use of few-shot learning for classification of semi-structured documents (scans of paper documents) generated as part of a business workflow (forms, letters, bills, etc.). Here the domain shift is significant, going from natural images to the semi-structured documents of interest. In this work, we address the problem of few-shot document image classification under domain shift. We evaluate our work by extensive comparisons with existing methods. Experimental results demonstrate that the proposed method shows consistent improvements on the few-shot classification performance under domain shift.
Efficient Document Image Classification Using Region-Based Graph Neural Network
Jun 25, 2021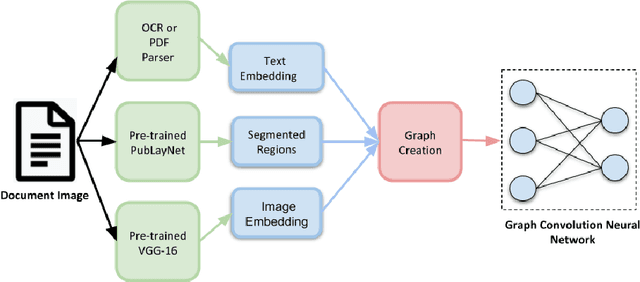
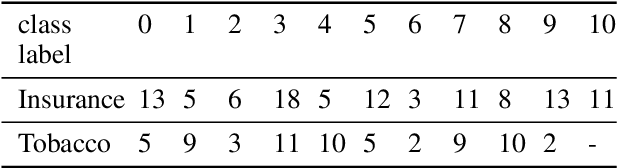

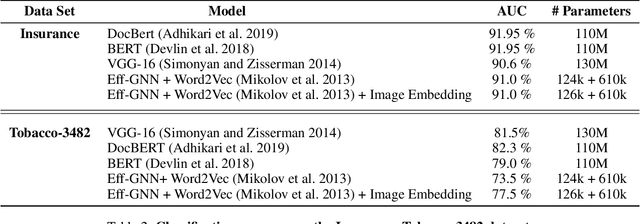
Document image classification remains a popular research area because it can be commercialized in many enterprise applications across different industries. Recent advancements in large pre-trained computer vision and language models and graph neural networks has lent document image classification many tools. However using large pre-trained models usually requires substantial computing resources which could defeat the cost-saving advantages of automatic document image classification. In the paper we propose an efficient document image classification framework that uses graph convolution neural networks and incorporates textual, visual and layout information of the document. We have rigorously benchmarked our proposed algorithm against several state-of-art vision and language models on both publicly available dataset and a real-life insurance document classification dataset. Empirical results on both publicly available and real-world data show that our methods achieve near SOTA performance yet require much less computing resources and time for model training and inference. This results in solutions than offer better cost advantages, especially in scalable deployment for enterprise applications. The results showed that our algorithm can achieve classification performance quite close to SOTA. We also provide comprehensive comparisons of computing resources, model sizes, train and inference time between our proposed methods and baselines. In addition we delineate the cost per image using our method and other baselines.
Continual Learning with Deep Artificial Neurons
Nov 13, 2020
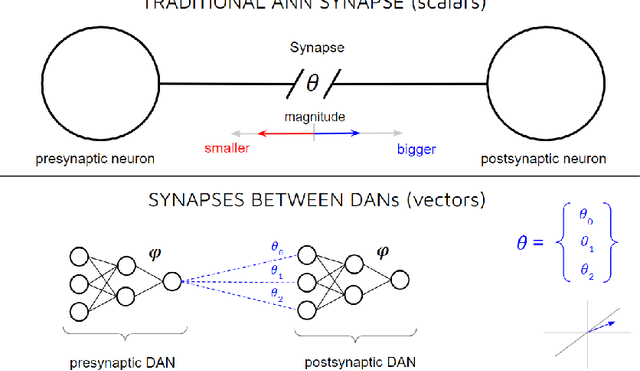
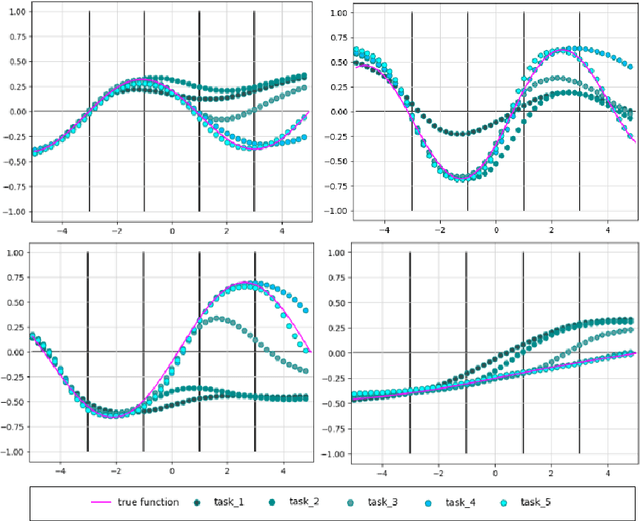
Neurons in real brains are enormously complex computational units. Among other things, they're responsible for transforming inbound electro-chemical vectors into outbound action potentials, updating the strengths of intermediate synapses, regulating their own internal states, and modulating the behavior of other nearby neurons. One could argue that these cells are the only things exhibiting any semblance of real intelligence. It is odd, therefore, that the machine learning community has, for so long, relied upon the assumption that this complexity can be reduced to a simple sum and fire operation. We ask, might there be some benefit to substantially increasing the computational power of individual neurons in artificial systems? To answer this question, we introduce Deep Artificial Neurons (DANs), which are themselves realized as deep neural networks. Conceptually, we embed DANs inside each node of a traditional neural network, and we connect these neurons at multiple synaptic sites, thereby vectorizing the connections between pairs of cells. We demonstrate that it is possible to meta-learn a single parameter vector, which we dub a neuronal phenotype, shared by all DANs in the network, which facilitates a meta-objective during deployment. Here, we isolate continual learning as our meta-objective, and we show that a suitable neuronal phenotype can endow a single network with an innate ability to update its synapses with minimal forgetting, using standard backpropagation, without experience replay, nor separate wake/sleep phases. We demonstrate this ability on sequential non-linear regression tasks.
Deep Active Learning via Open Set Recognition
Jul 14, 2020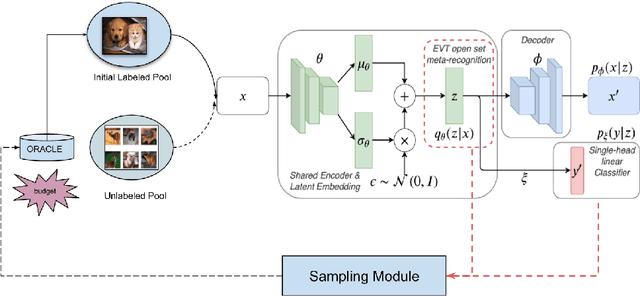
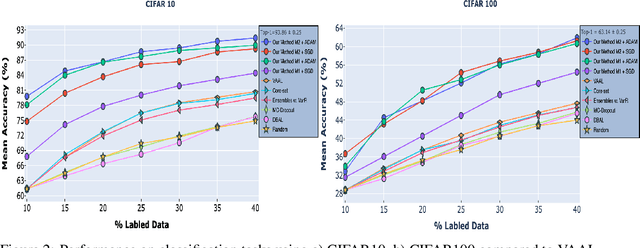
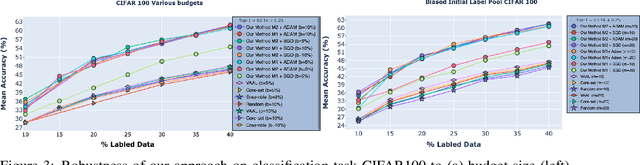
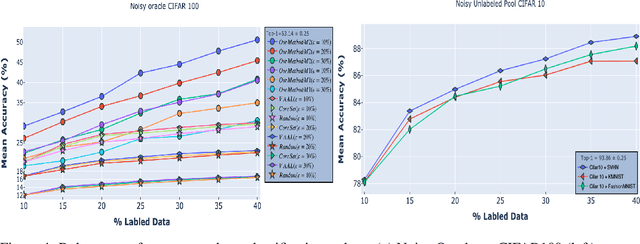
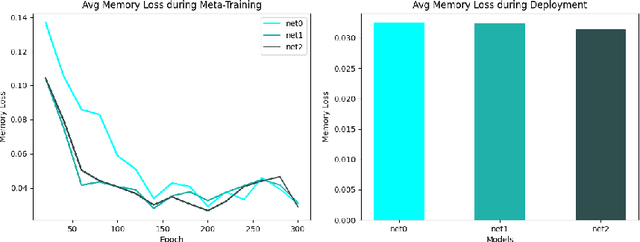
In many applications, data is easy to acquire but expensive and time consuming to label prominent examples include medical imaging and NLP. This disparity has only grown in recent years as our ability to collect data improves. Under these constraints, it makes sense to select only the most informative instances from the unlabeled pool and request an oracle (e.g a human expert) to provide labels for those samples. The goal of active learning is to infer the informativeness of unlabeled samples so as to minimize the number of requests to the oracle. Here, we formulate active learning as an open-set recognition problem. In this latter paradigm, only some of the inputs belong to known classes; the classifier must identify the rest as unknown.More specifically, we leverage variational neuralnetworks (VNNs), which produce high-confidence (i.e., low-entropy) predictions only for inputs that closely resemble the training data. We use the inverse of this confidence measure to select the samples that the oracle should label. Intuitively, unlabeled samples that the VNN is uncertain about are more informative for future training. We carried out an extensive evaluation of our novel, probabilistic formulation of active learning, achieving state-of-the-art results on CIFAR-10 andCIFAR-100. In addition, unlike current active learning methods, our algorithm can learn tasks with non i.i.d distribution, without the need for task labels. As our experiments show, when the unlabeled pool consists of a mixture of samples from multiple tasks, our approach can automatically distinguish between samples from seen vs. unseen tasks.
A Scalable Approach to Multi-Context Continual Learning via Lifelong Skill Encoding
May 25, 2018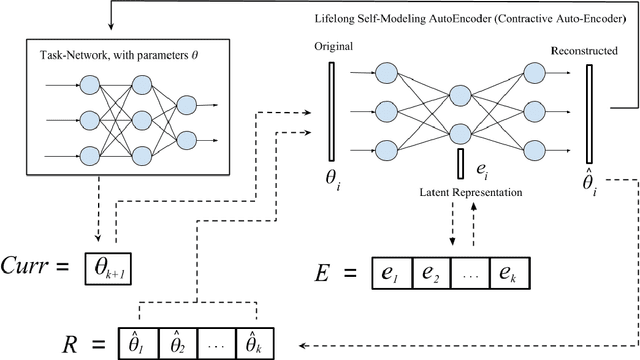
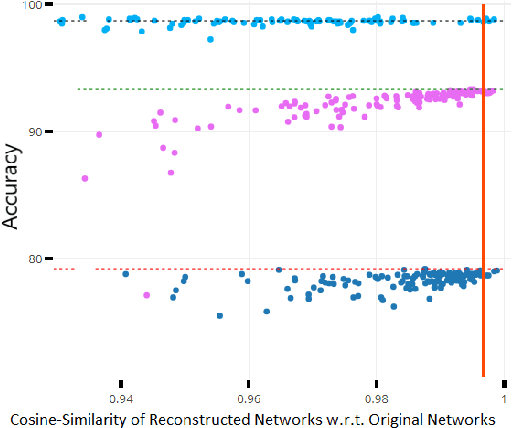
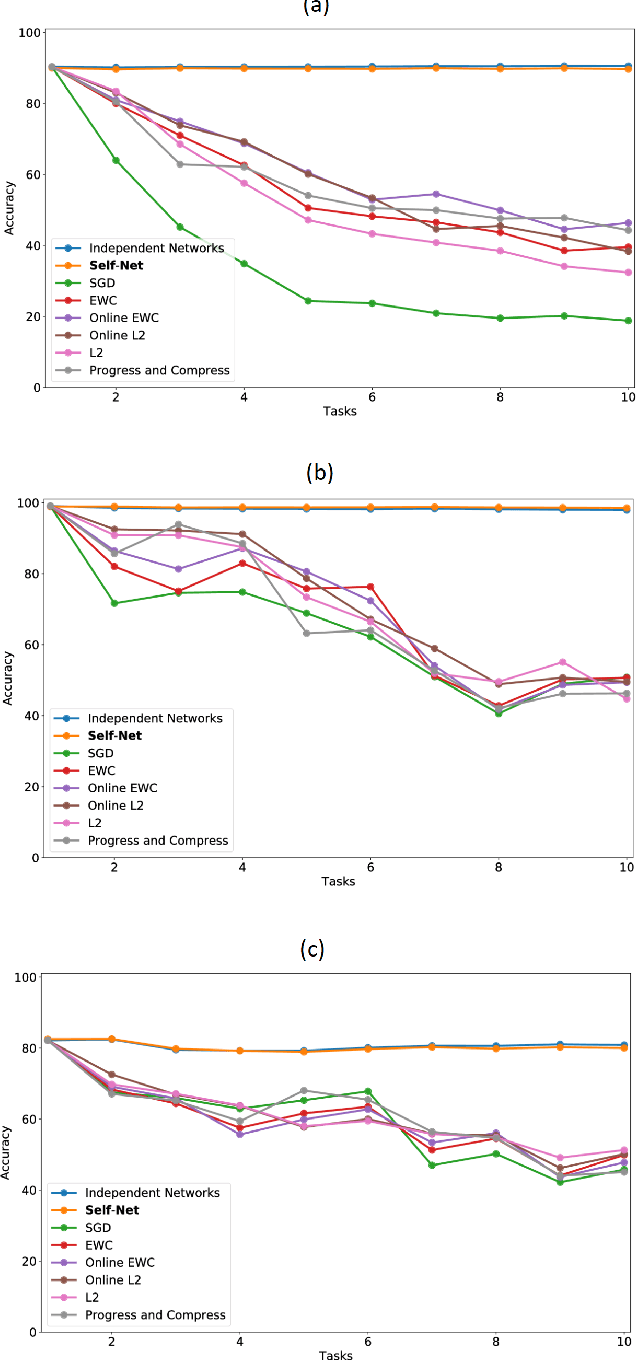
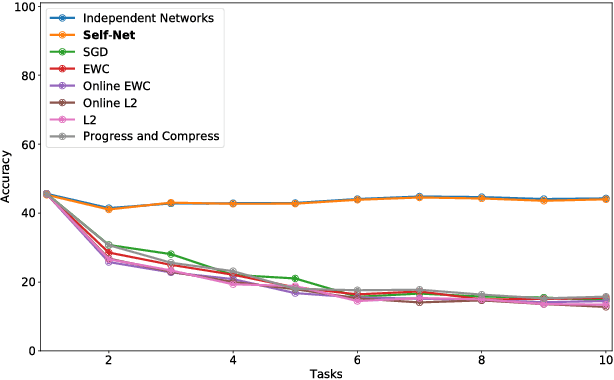
Continual or lifelong learning (CL) is one of the most challenging problems in machine learning. In this paradigm, a system must learn new tasks, contexts, or data without forgetting previously learned information. We present a scalable approach to multi-context continual learning (MCCL) in which we decouple how a system learns to solve new tasks (i.e., acquires skills) from how it stores them. Our approach leverages two types of artificial networks: (1) a set of reusable, \textit{task-specific networks} (TN) that can be trained as needed to learn new skills, and (2) a lifelong, \textit{autoencoder network} (EN) that stores all learned skills in a compact, latent space. To learn a new skill, we first train a TN using conventional backpropagation, thus placing no restrictions on the system's ability to encode the new task. We then incorporate the newly learned skill into the latent space by first recalling previously learned skills using our EN and then retraining it on both the new and recalled skills. Our approach can efficiently store an arbitrary number of skills without compromising previously learned information because each skill is stored as a separate latent vector. Whenever a particular skill is needed, we recall the necessary weights using our EN and then load them into the corresponding TN. Experiments on the MNIST and CIFAR datasets show that we can continually learn new skills without compromising the performance of existing skills. To the best of our knowledge, we are the first to demonstrate the feasibility of encoding entire networks in order to facilitate efficient continual learning.