 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Approach to Multi-Context Continual Learning via Lifelong Skill Encoding
Paper and Code
May 25, 2018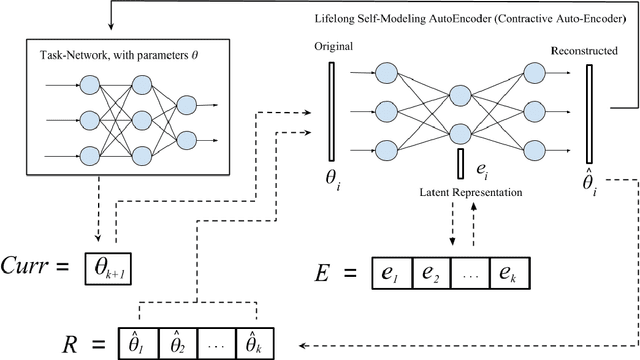
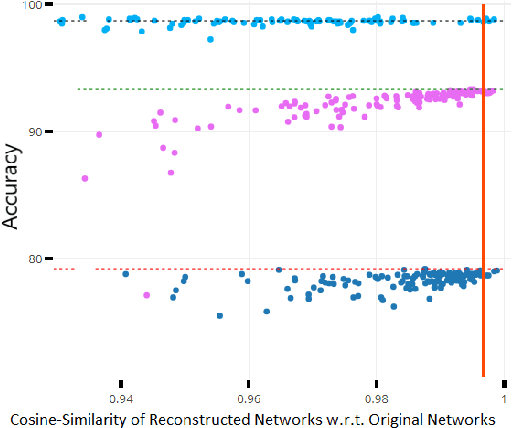
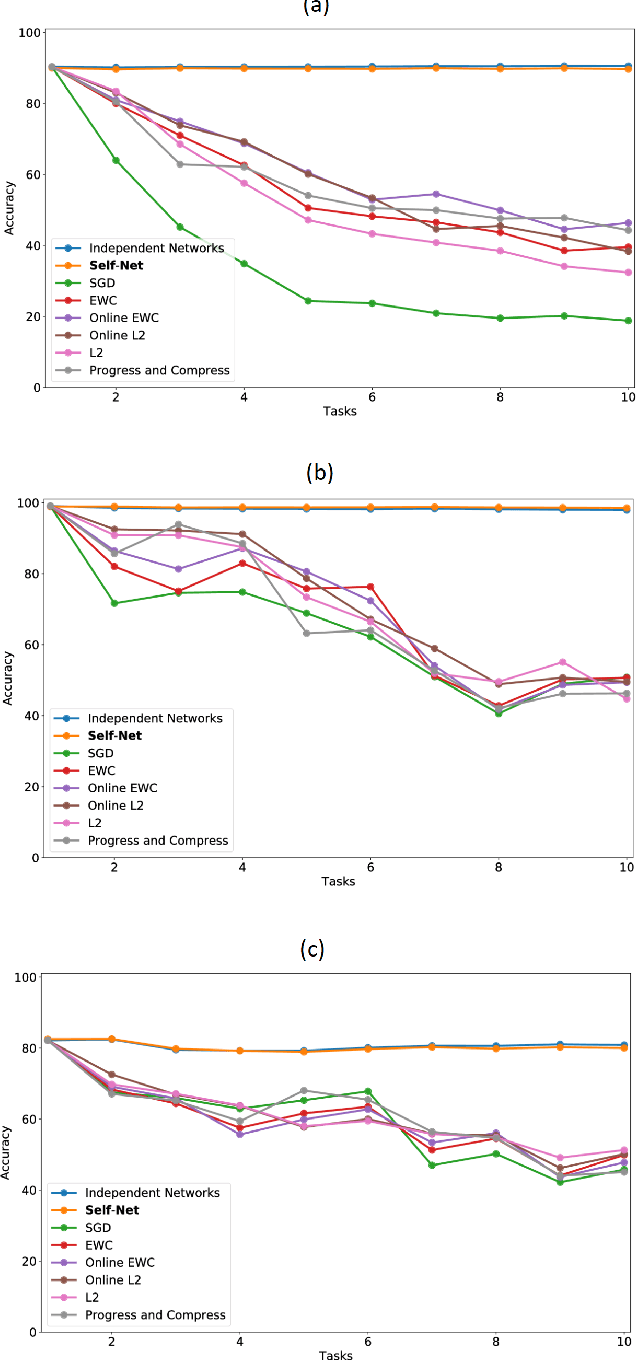
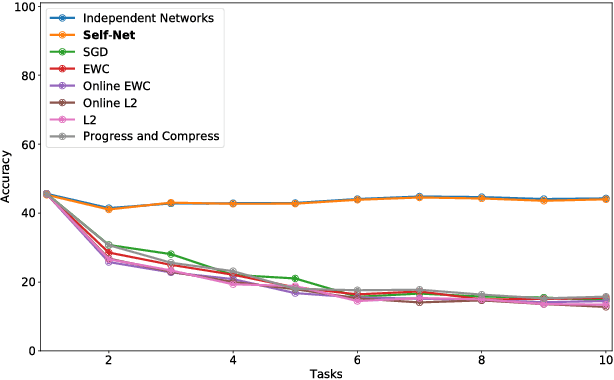
Continual or lifelong learning (CL) is one of the most challenging problems in machine learning. In this paradigm, a system must learn new tasks, contexts, or data without forgetting previously learned information. We present a scalable approach to multi-context continual learning (MCCL) in which we decouple how a system learns to solve new tasks (i.e., acquires skills) from how it stores them. Our approach leverages two types of artificial networks: (1) a set of reusable, \textit{task-specific networks} (TN) that can be trained as needed to learn new skills, and (2) a lifelong, \textit{autoencoder network} (EN) that stores all learned skills in a compact, latent space. To learn a new skill, we first train a TN using conventional backpropagation, thus placing no restrictions on the system's ability to encode the new task. We then incorporate the newly learned skill into the latent space by first recalling previously learned skills using our EN and then retraining it on both the new and recalled skills. Our approach can efficiently store an arbitrary number of skills without compromising previously learned information because each skill is stored as a separate latent vector. Whenever a particular skill is needed, we recall the necessary weights using our EN and then load them into the corresponding TN. Experiments on the MNIST and CIFAR datasets show that we can continually learn new skills without compromising the performance of existing skills. To the best of our knowledge, we are the first to demonstrate the feasibility of encoding entire networks in order to facilitate efficient continual learning.