 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated Artery-Vein ratio and vascular tortuosity measurement in retinal fundus images
Jan 04, 2023Accurate measurements of abnormalities like Artery-Vein ratio and tortuosity in fundus images is an actively researched task. Most of the research seems to compute such features independently. However, in this work, we have devised a fully automated technique to measure any vascular abnormalities. This paper is a follow-up paper on vessel topology estimation and extraction, we use the extracted topology to perform A-V state-of-the-art Artery-Vein classification, AV ratio calculation, and vessel tortuosity measurement, all fully automated. Existing techniques tend to only work on the partial region, but we extract the complete vascular structure. We have shown the usability of this topology by extracting two of the most important vascular features; Artery-Vein ratio, and vessel tortuosity.
Deep Active Learning Using Barlow Twins
Dec 30, 2022



The generalisation performance of a convolutional neural networks (CNN) is majorly predisposed by the quantity, quality, and diversity of the training images. All the training data needs to be annotated in-hand before, in many real-world applications data is easy to acquire but expensive and time-consuming to label. The goal of the Active learning for the task is to draw most informative samples from the unlabeled pool which can used for training after annotation. With total different objective, self-supervised learning which have been gaining meteoric popularity by closing the gap in performance with supervised methods on large computer vision benchmarks. self-supervised learning (SSL) these days have shown to produce low-level representations that are invariant to distortions of the input sample and can encode invariance to artificially created distortions, e.g. rotation, solarization, cropping etc. self-supervised learning (SSL) approaches rely on simpler and more scalable frameworks for learning. In this paper, we unify these two families of approaches from the angle of active learning using self-supervised learning mainfold and propose Deep Active Learning using BarlowTwins(DALBT), an active learning method for all the datasets using combination of classifier trained along with self-supervised loss framework of Barlow Twins to a setting where the model can encode the invariance of artificially created distortions, e.g. rotation, solarization, cropping etc.
Fully Automated Tree Topology Estimation and Artery-Vein Classification
Feb 04, 2022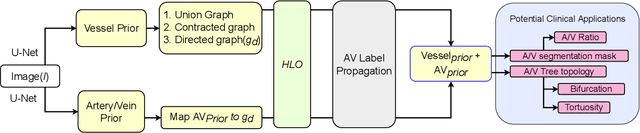

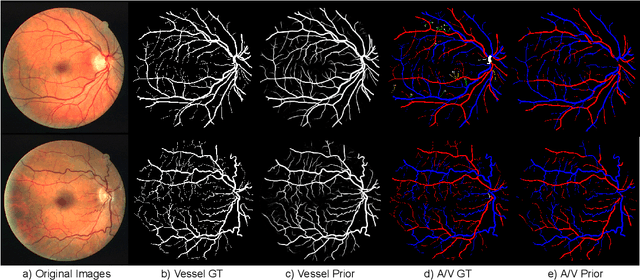
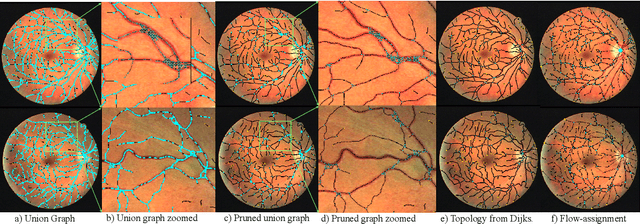
We present a fully automatic technique for extracting the retinal vascular topology, i.e., how the different vessels are connected to each other, given a single color fundus image. Determining this connectivity is very challenging because vessels cross each other in a 2D image, obscuring their true paths. We validated the usefulness of our extraction method by using it to achieve state-of-the-art results in retinal artery-vein classification. Our proposed approach works as follows. We first segment the retinal vessels using our previously developed state-of-the-art segmentation method. Then, we estimate an initial graph from the extracted vessels and assign the most likely blood flow to each edge. We then use a handful of high-level operations (HLOs) to fix errors in the graph. These HLOs include detaching neighboring nodes, shifting the endpoints of an edge, and reversing the estimated blood flow direction for a branch. We use a novel cost function to find the optimal set of HLO operations for a given graph. Finally, we show that our extracted vascular structure is correct by propagating artery/vein labels along the branches. As our experiments show, our topology-based artery-vein labeling achieved state-of-the-art results on multiple datasets. We also performed several ablation studies to verify the importance of the different components of our proposed method.
Optic Disc Segmentation using Disk-Centered Patch Augmentation
Oct 01, 2021
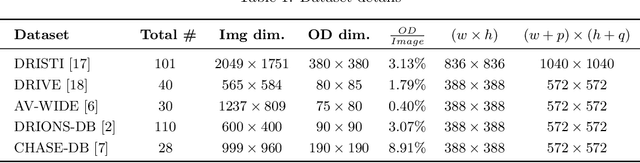
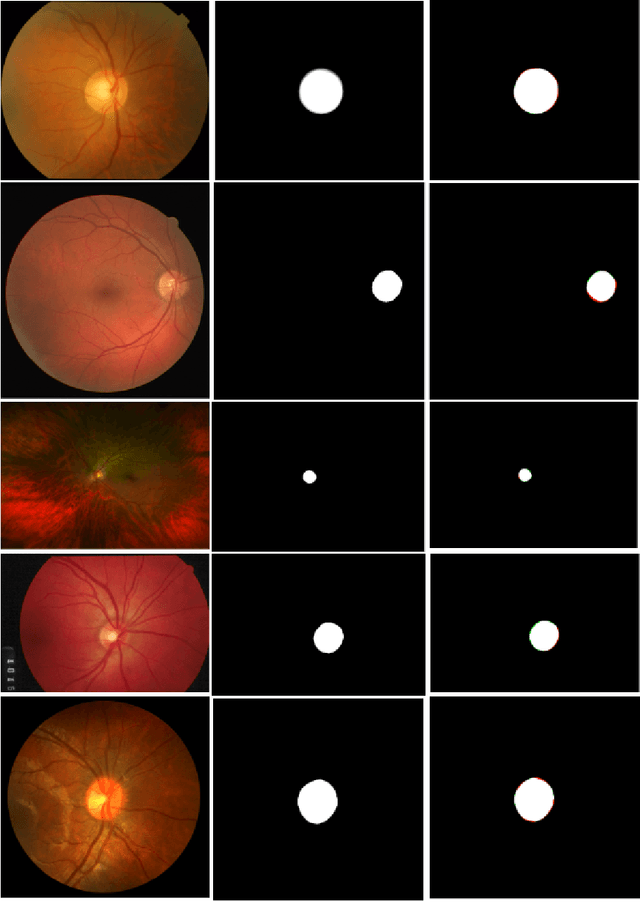
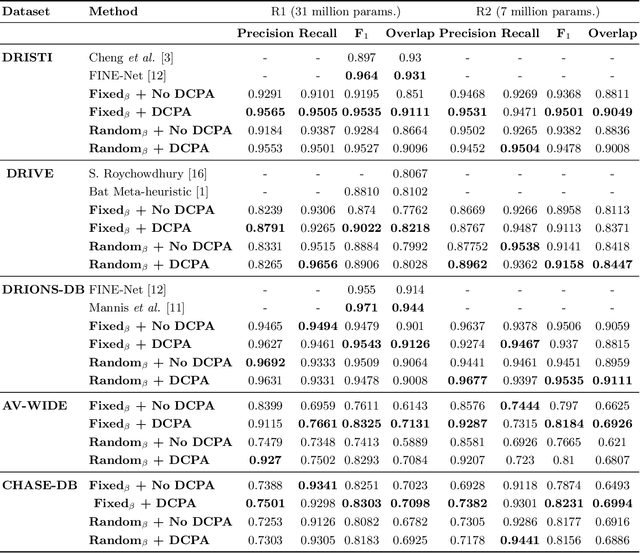
The optic disc is a crucial diagnostic feature in the eye since changes to its physiognomy is correlated with the severity of various ocular and cardiovascular diseases. While identifying the bulk of the optic disc in a color fundus image is straightforward, accurately segmenting its boundary at the pixel level is very challenging. In this work, we propose disc-centered patch augmentation (DCPA) -- a simple, yet novel training scheme for deep neural networks -- to address this problem. DCPA achieves state-of-the-art results on full-size images even when using small neural networks, specifically a U-Net with only 7 million parameters as opposed to the original 31 million. In DCPA, we restrict the training data to patches that fully contain the optic nerve. In addition, we also train the network using dynamic cost functions to increase its robustness. We tested DCPA-trained networks on five retinal datasets: DRISTI, DRIONS-DB, DRIVE, AV-WIDE, and CHASE-DB. The first two had available optic disc ground truth, and we manually estimated the ground truth for the latter three. Our approach achieved state-of-the-art F1 and IOU results on four datasets (95 % F1, 91 % IOU on DRISTI; 92 % F1, 84 % IOU on DRIVE; 83 % F1, 71 % IOU on AV-WIDE; 83 % F1, 71 % IOU on CHASEDB) and competitive results on the fifth (95 % F1, 91 % IOU on DRIONS-DB), confirming its generality. Our open-source code and ground-truth annotations are available at: https://github.com/saeidmotevali/fundusdisk
SuperCaustics: Real-time, open-source simulation of transparent objects for deep learning applications
Jul 23, 2021
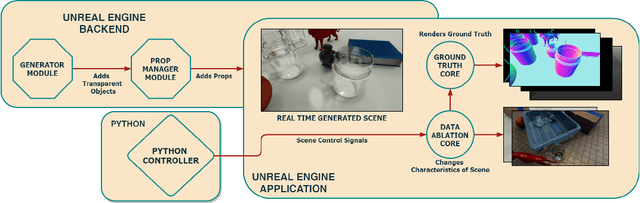


Transparent objects are a very challenging problem in computer vision. They are hard to segment or classify due to their lack of precise boundaries, and there is limited data available for training deep neural networks. As such, current solutions for this problem employ rigid synthetic datasets, which lack flexibility and lead to severe performance degradation when deployed on real-world scenarios. In particular, these synthetic datasets omit features such as refraction, dispersion and caustics due to limitations in the rendering pipeline. To address this issue, we present SuperCaustics, a real-time, open-source simulation of transparent objects designed for deep learning applications. SuperCaustics features extensive modules for stochastic environment creation; uses hardware ray-tracing to support caustics, dispersion, and refraction; and enables generating massive datasets with multi-modal, pixel-perfect ground truth annotations. To validate our proposed system, we trained a deep neural network from scratch to segment transparent objects in difficult lighting scenarios. Our neural network achieved performance comparable to the state-of-the-art on a real-world dataset using only 10% of the training data and in a fraction of the training time. Further experiments show that a model trained with SuperCaustics can segment different types of caustics, even in images with multiple overlapping transparent objects. To the best of our knowledge, this is the first such result for a model trained on synthetic data. Both our open-source code and experimental data are freely available online.
Continual Learning with Deep Artificial Neurons
Nov 13, 2020
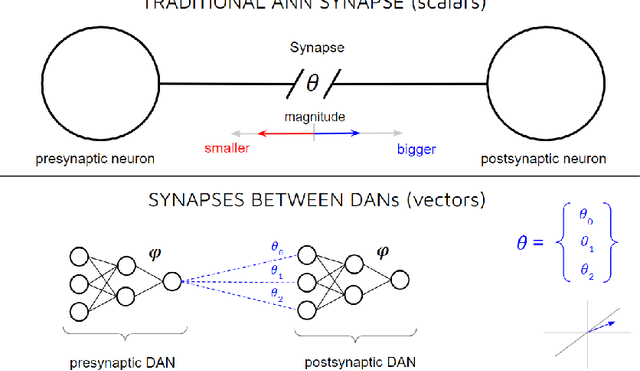
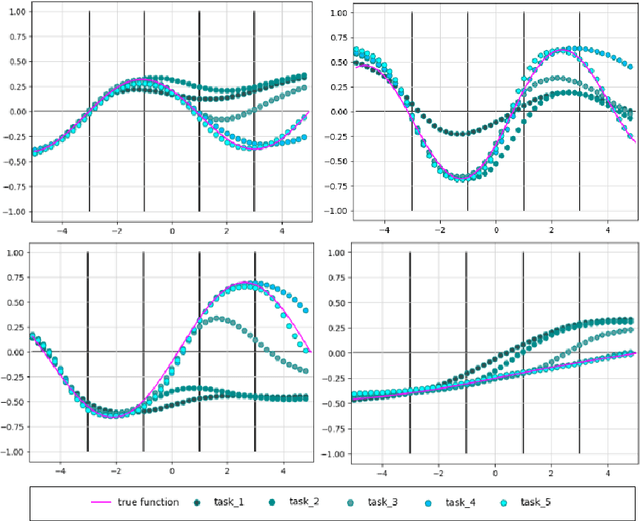
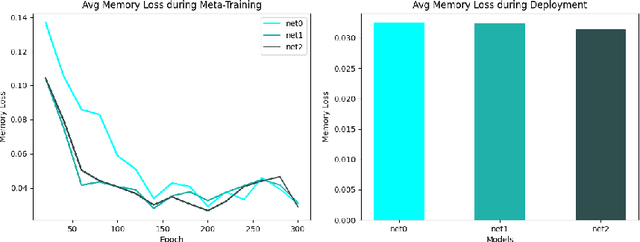
Neurons in real brains are enormously complex computational units. Among other things, they're responsible for transforming inbound electro-chemical vectors into outbound action potentials, updating the strengths of intermediate synapses, regulating their own internal states, and modulating the behavior of other nearby neurons. One could argue that these cells are the only things exhibiting any semblance of real intelligence. It is odd, therefore, that the machine learning community has, for so long, relied upon the assumption that this complexity can be reduced to a simple sum and fire operation. We ask, might there be some benefit to substantially increasing the computational power of individual neurons in artificial systems? To answer this question, we introduce Deep Artificial Neurons (DANs), which are themselves realized as deep neural networks. Conceptually, we embed DANs inside each node of a traditional neural network, and we connect these neurons at multiple synaptic sites, thereby vectorizing the connections between pairs of cells. We demonstrate that it is possible to meta-learn a single parameter vector, which we dub a neuronal phenotype, shared by all DANs in the network, which facilitates a meta-objective during deployment. Here, we isolate continual learning as our meta-objective, and we show that a suitable neuronal phenotype can endow a single network with an innate ability to update its synapses with minimal forgetting, using standard backpropagation, without experience replay, nor separate wake/sleep phases. We demonstrate this ability on sequential non-linear regression tasks.
Deep Active Learning via Open Set Recognition
Jul 14, 2020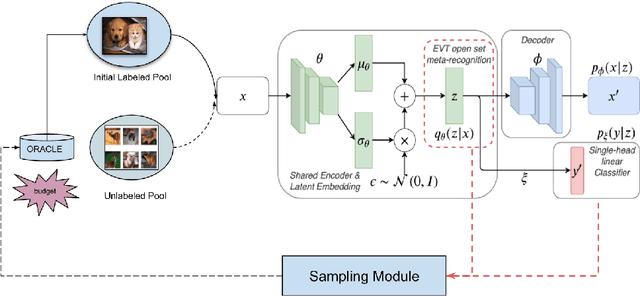
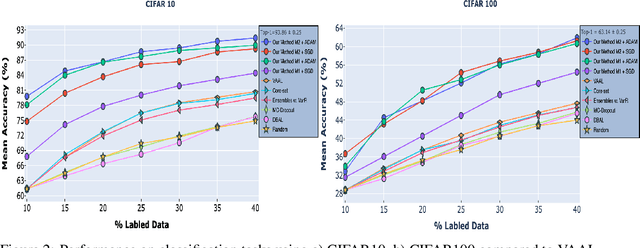
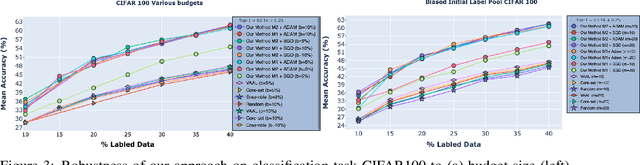
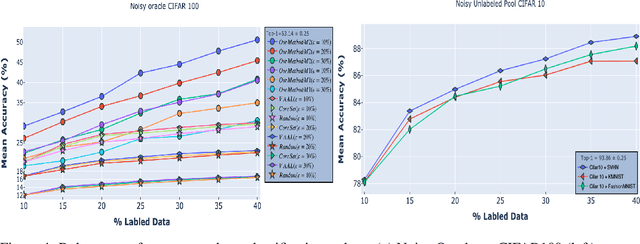
In many applications, data is easy to acquire but expensive and time consuming to label prominent examples include medical imaging and NLP. This disparity has only grown in recent years as our ability to collect data improves. Under these constraints, it makes sense to select only the most informative instances from the unlabeled pool and request an oracle (e.g a human expert) to provide labels for those samples. The goal of active learning is to infer the informativeness of unlabeled samples so as to minimize the number of requests to the oracle. Here, we formulate active learning as an open-set recognition problem. In this latter paradigm, only some of the inputs belong to known classes; the classifier must identify the rest as unknown.More specifically, we leverage variational neuralnetworks (VNNs), which produce high-confidence (i.e., low-entropy) predictions only for inputs that closely resemble the training data. We use the inverse of this confidence measure to select the samples that the oracle should label. Intuitively, unlabeled samples that the VNN is uncertain about are more informative for future training. We carried out an extensive evaluation of our novel, probabilistic formulation of active learning, achieving state-of-the-art results on CIFAR-10 andCIFAR-100. In addition, unlike current active learning methods, our algorithm can learn tasks with non i.i.d distribution, without the need for task labels. As our experiments show, when the unlabeled pool consists of a mixture of samples from multiple tasks, our approach can automatically distinguish between samples from seen vs. unseen tasks.
AI Playground: Unreal Engine-based Data Ablation Tool for Deep Learning
Jul 13, 2020
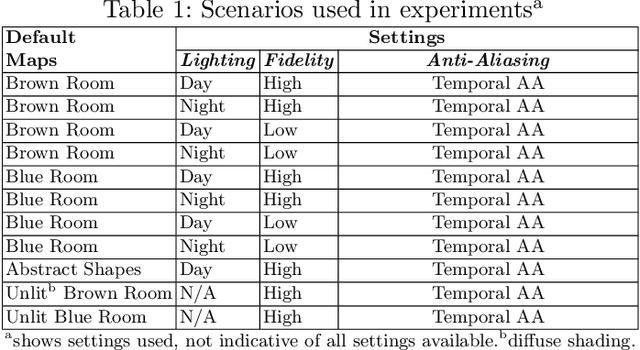
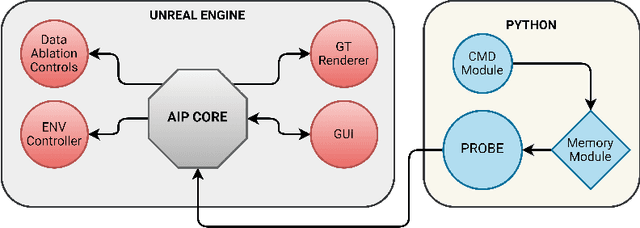

Machine learning requires data, but acquiring and labeling real-world data is challenging, expensive, and time-consuming. More importantly, it is nearly impossible to alter real data post-acquisition (e.g., change the illumination of a room), making it very difficult to measure how specific properties of the data affect performance. In this paper, we present AI Playground (AIP), an open-source, Unreal Engine-based tool for generating and labeling virtual image data. With AIP, it is trivial to capture the same image under different conditions (e.g., fidelity, lighting, etc.) and with different ground truths (e.g., depth or surface normal values). AIP is easily extendable and can be used with or without code. To validate our proposed tool, we generated eight datasets of otherwise identical but varying lighting and fidelity conditions. We then trained deep neural networks to predict (1) depth values, (2) surface normals, or (3) object labels and assessed each network's intra- and cross-dataset performance. Among other insights, we verified that sensitivity to different settings is problem-dependent. We confirmed the findings of other studies that segmentation models are very sensitive to fidelity, but we also found that they are just as sensitive to lighting. In contrast, depth and normal estimation models seem to be less sensitive to fidelity or lighting and more sensitive to the structure of the image. Finally, we tested our trained depth-estimation networks on two real-world datasets and obtained results comparable to training on real data alone, confirming that our virtual environments are realistic enough for real-world tasks.
Dynamic Deep Networks for Retinal Vessel Segmentation
Mar 27, 2019
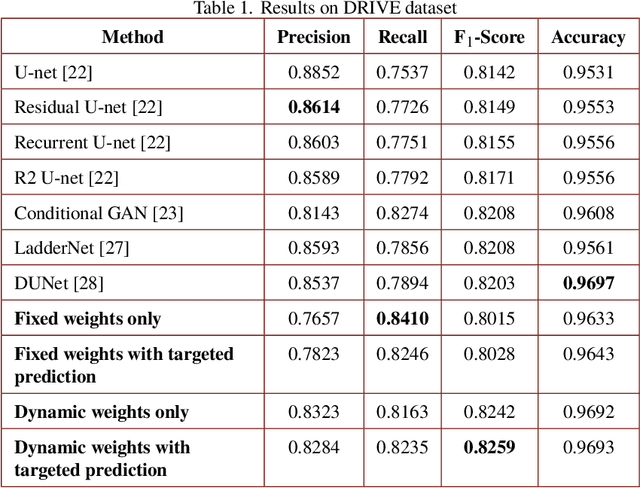
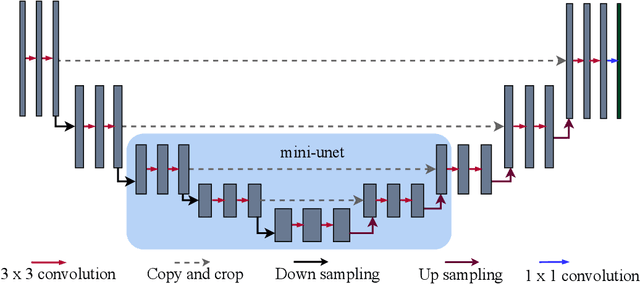
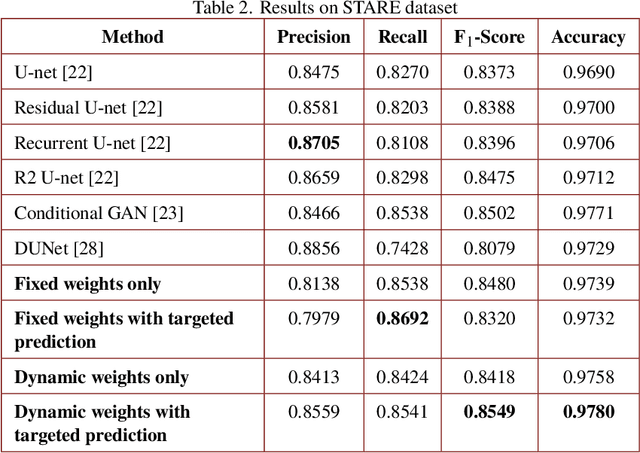
Segmenting the retinal vasculature entails a trade-off between how much of the overall vascular structure we identify vs. how precisely we segment individual vessels. In particular, state-of-the-art methods tend to under-segment faint vessels, as well as pixels that lie on the edges of thicker vessels. Thus, they underestimate the width of individual vessels, as well as the ratio of large to small vessels. More generally, many crucial bio-markers---including the artery-vein (AV) ratio, branching angles, number of bifurcation, fractal dimension, tortuosity, vascular length-to-diameter ratio and wall-to-lumen length---require precise measurements of individual vessels. To address this limitation, we propose a novel, stochastic training scheme for deep neural networks that better classifies the faint, ambiguous regions of the image. Our approach relies on two key innovations. First, we train our deep networks with dynamic weights that fluctuate during each training iteration. This stochastic approach forces the network to learn a mapping that robustly balances precision and recall. Second, we decouple the segmentation process into two steps. In the first half of our pipeline, we estimate the likelihood of every pixel and then use these likelihoods to segment pixels that are clearly vessel or background. In the latter part of our pipeline, we use a second network to classify the ambiguous regions in the image. Our proposed method obtained state-of-the-art results on five retinal datasets---DRIVE, STARE, CHASE-DB, AV-WIDE, and VEVIO---by learning a robust balance between false positive and false negative rates. In addition, we are the first to report segmentation results on the AV-WIDE dataset, and we have made the ground-truth annotations for this dataset publicly available.
A Scalable Approach to Multi-Context Continual Learning via Lifelong Skill Encoding
May 25, 2018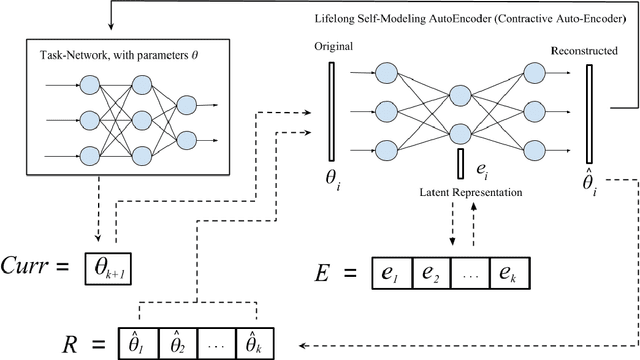
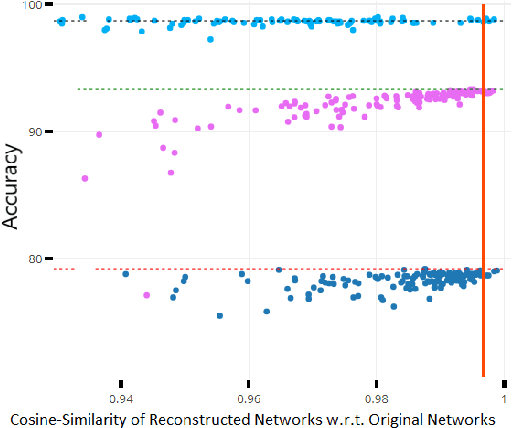
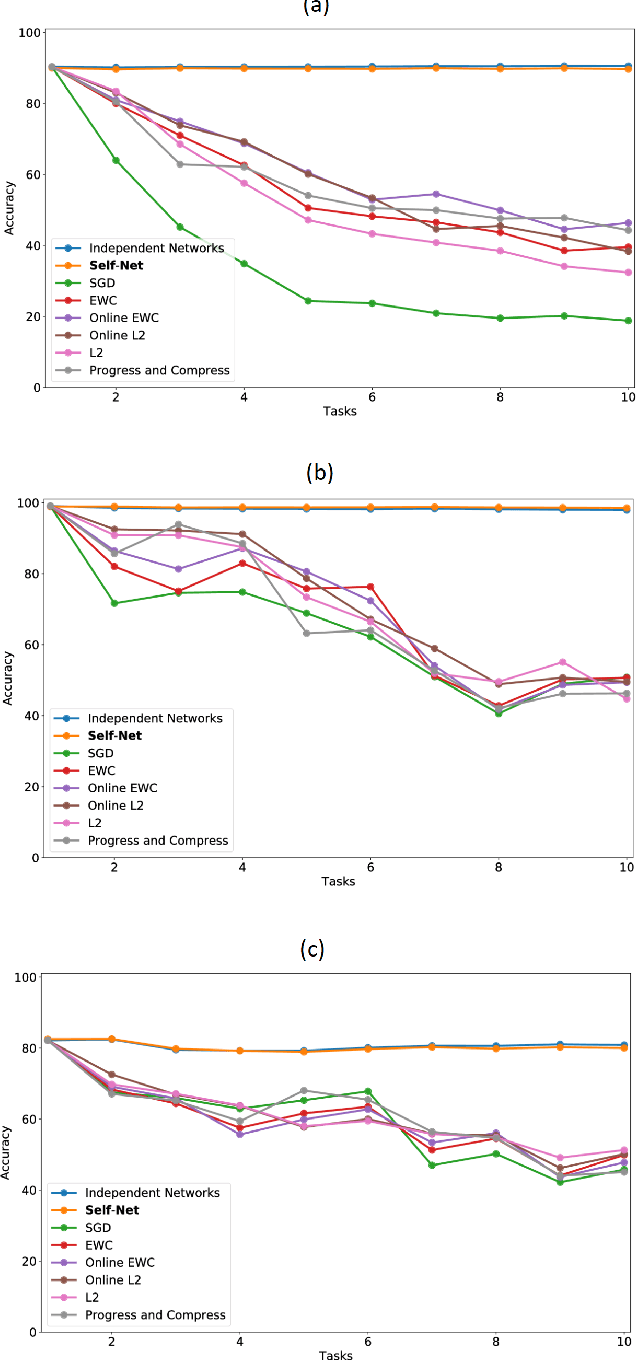
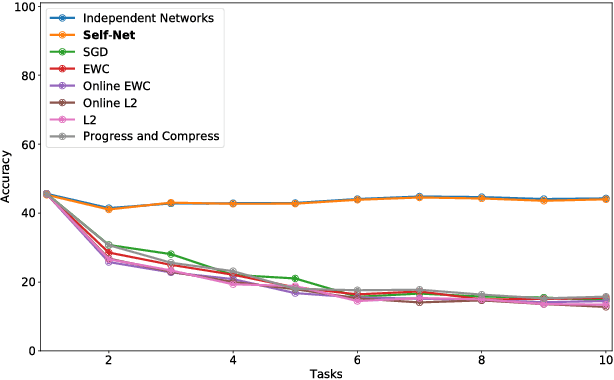
Continual or lifelong learning (CL) is one of the most challenging problems in machine learning. In this paradigm, a system must learn new tasks, contexts, or data without forgetting previously learned information. We present a scalable approach to multi-context continual learning (MCCL) in which we decouple how a system learns to solve new tasks (i.e., acquires skills) from how it stores them. Our approach leverages two types of artificial networks: (1) a set of reusable, \textit{task-specific networks} (TN) that can be trained as needed to learn new skills, and (2) a lifelong, \textit{autoencoder network} (EN) that stores all learned skills in a compact, latent space. To learn a new skill, we first train a TN using conventional backpropagation, thus placing no restrictions on the system's ability to encode the new task. We then incorporate the newly learned skill into the latent space by first recalling previously learned skills using our EN and then retraining it on both the new and recalled skills. Our approach can efficiently store an arbitrary number of skills without compromising previously learned information because each skill is stored as a separate latent vector. Whenever a particular skill is needed, we recall the necessary weights using our EN and then load them into the corresponding TN. Experiments on the MNIST and CIFAR datasets show that we can continually learn new skills without compromising the performance of existing skills. To the best of our knowledge, we are the first to demonstrate the feasibility of encoding entire networks in order to facilitate efficient continual learning.