 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperCaustics: Real-time, open-source simulation of transparent objects for deep learning applications
Jul 23, 2021
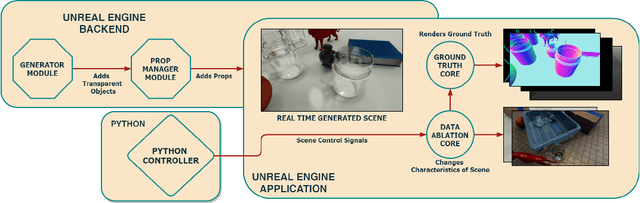


Transparent objects are a very challenging problem in computer vision. They are hard to segment or classify due to their lack of precise boundaries, and there is limited data available for training deep neural networks. As such, current solutions for this problem employ rigid synthetic datasets, which lack flexibility and lead to severe performance degradation when deployed on real-world scenarios. In particular, these synthetic datasets omit features such as refraction, dispersion and caustics due to limitations in the rendering pipeline. To address this issue, we present SuperCaustics, a real-time, open-source simulation of transparent objects designed for deep learning applications. SuperCaustics features extensive modules for stochastic environment creation; uses hardware ray-tracing to support caustics, dispersion, and refraction; and enables generating massive datasets with multi-modal, pixel-perfect ground truth annotations. To validate our proposed system, we trained a deep neural network from scratch to segment transparent objects in difficult lighting scenarios. Our neural network achieved performance comparable to the state-of-the-art on a real-world dataset using only 10% of the training data and in a fraction of the training time. Further experiments show that a model trained with SuperCaustics can segment different types of caustics, even in images with multiple overlapping transparent objects. To the best of our knowledge, this is the first such result for a model trained on synthetic data. Both our open-source code and experimental data are freely available online.
AI Playground: Unreal Engine-based Data Ablation Tool for Deep Learning
Jul 13, 2020
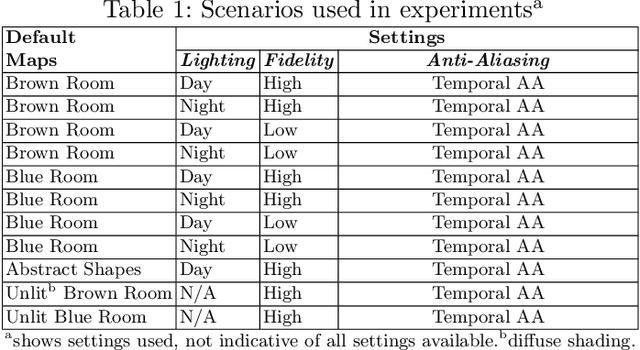
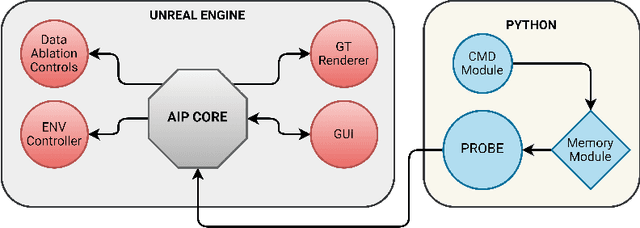

Machine learning requires data, but acquiring and labeling real-world data is challenging, expensive, and time-consuming. More importantly, it is nearly impossible to alter real data post-acquisition (e.g., change the illumination of a room), making it very difficult to measure how specific properties of the data affect performance. In this paper, we present AI Playground (AIP), an open-source, Unreal Engine-based tool for generating and labeling virtual image data. With AIP, it is trivial to capture the same image under different conditions (e.g., fidelity, lighting, etc.) and with different ground truths (e.g., depth or surface normal values). AIP is easily extendable and can be used with or without code. To validate our proposed tool, we generated eight datasets of otherwise identical but varying lighting and fidelity conditions. We then trained deep neural networks to predict (1) depth values, (2) surface normals, or (3) object labels and assessed each network's intra- and cross-dataset performance. Among other insights, we verified that sensitivity to different settings is problem-dependent. We confirmed the findings of other studies that segmentation models are very sensitive to fidelity, but we also found that they are just as sensitive to lighting. In contrast, depth and normal estimation models seem to be less sensitive to fidelity or lighting and more sensitive to the structure of the image. Finally, we tested our trained depth-estimation networks on two real-world datasets and obtained results comparable to training on real data alone, confirming that our virtual environments are realistic enough for real-world tasks.