 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Deep Artificial Neurons
Paper and Code
Nov 13, 2020
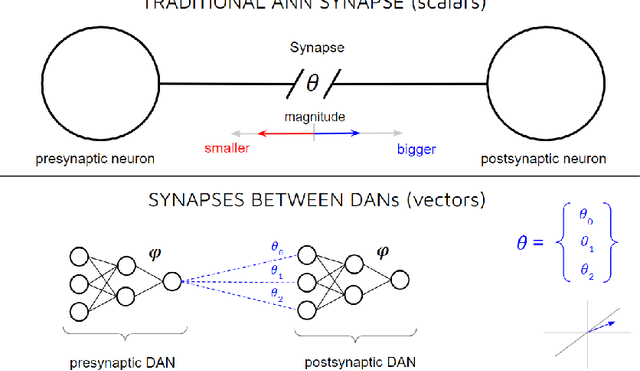
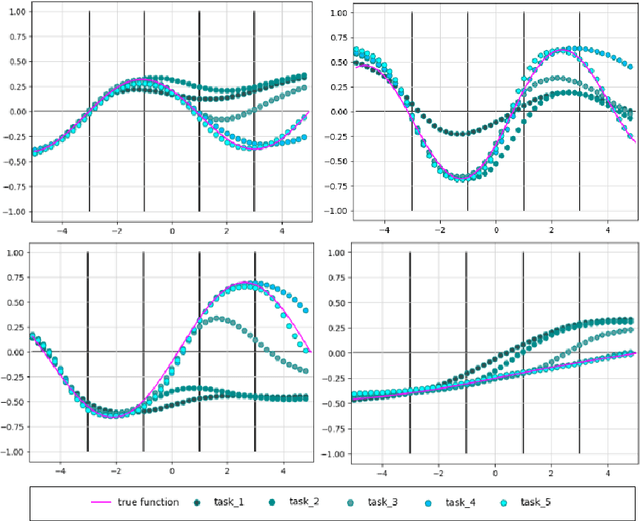
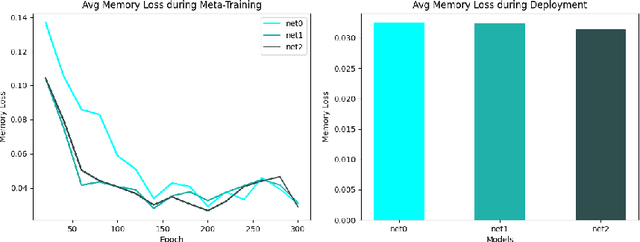
Neurons in real brains are enormously complex computational units. Among other things, they're responsible for transforming inbound electro-chemical vectors into outbound action potentials, updating the strengths of intermediate synapses, regulating their own internal states, and modulating the behavior of other nearby neurons. One could argue that these cells are the only things exhibiting any semblance of real intelligence. It is odd, therefore, that the machine learning community has, for so long, relied upon the assumption that this complexity can be reduced to a simple sum and fire operation. We ask, might there be some benefit to substantially increasing the computational power of individual neurons in artificial systems? To answer this question, we introduce Deep Artificial Neurons (DANs), which are themselves realized as deep neural networks. Conceptually, we embed DANs inside each node of a traditional neural network, and we connect these neurons at multiple synaptic sites, thereby vectorizing the connections between pairs of cells. We demonstrate that it is possible to meta-learn a single parameter vector, which we dub a neuronal phenotype, shared by all DANs in the network, which facilitates a meta-objective during deployment. Here, we isolate continual learning as our meta-objective, and we show that a suitable neuronal phenotype can endow a single network with an innate ability to update its synapses with minimal forgetting, using standard backpropagation, without experience replay, nor separate wake/sleep phases. We demonstrate this ability on sequential non-linear regression tasks.