 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning via Open Set Recognition
Paper and Code
Jul 14, 2020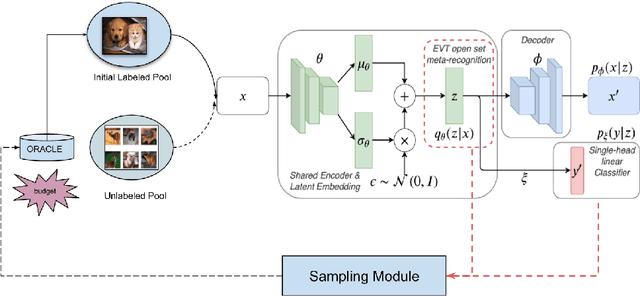
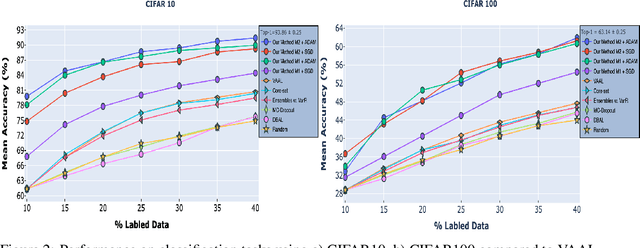
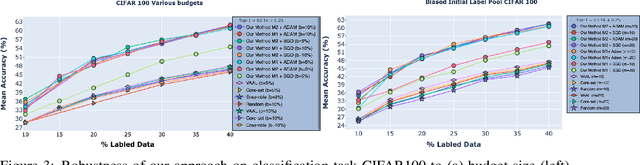
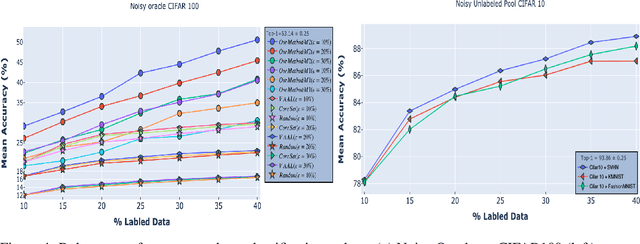
In many applications, data is easy to acquire but expensive and time consuming to label prominent examples include medical imaging and NLP. This disparity has only grown in recent years as our ability to collect data improves. Under these constraints, it makes sense to select only the most informative instances from the unlabeled pool and request an oracle (e.g a human expert) to provide labels for those samples. The goal of active learning is to infer the informativeness of unlabeled samples so as to minimize the number of requests to the oracle. Here, we formulate active learning as an open-set recognition problem. In this latter paradigm, only some of the inputs belong to known classes; the classifier must identify the rest as unknown.More specifically, we leverage variational neuralnetworks (VNNs), which produce high-confidence (i.e., low-entropy) predictions only for inputs that closely resemble the training data. We use the inverse of this confidence measure to select the samples that the oracle should label. Intuitively, unlabeled samples that the VNN is uncertain about are more informative for future training. We carried out an extensive evaluation of our novel, probabilistic formulation of active learning, achieving state-of-the-art results on CIFAR-10 andCIFAR-100. In addition, unlike current active learning methods, our algorithm can learn tasks with non i.i.d distribution, without the need for task labels. As our experiments show, when the unlabeled pool consists of a mixture of samples from multiple tasks, our approach can automatically distinguish between samples from seen vs. unseen tasks.