 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Document Image Classification Using Region-Based Graph Neural Network
Paper and Code
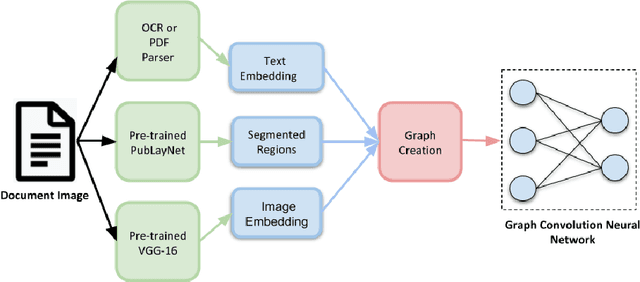
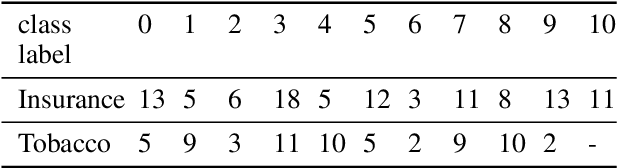

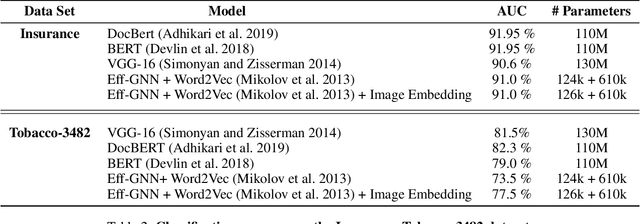
Document image classification remains a popular research area because it can be commercialized in many enterprise applications across different industries. Recent advancements in large pre-trained computer vision and language models and graph neural networks has lent document image classification many tools. However using large pre-trained models usually requires substantial computing resources which could defeat the cost-saving advantages of automatic document image classification. In the paper we propose an efficient document image classification framework that uses graph convolution neural networks and incorporates textual, visual and layout information of the document. We have rigorously benchmarked our proposed algorithm against several state-of-art vision and language models on both publicly available dataset and a real-life insurance document classification dataset. Empirical results on both publicly available and real-world data show that our methods achieve near SOTA performance yet require much less computing resources and time for model training and inference. This results in solutions than offer better cost advantages, especially in scalable deployment for enterprise applications. The results showed that our algorithm can achieve classification performance quite close to SOTA. We also provide comprehensive comparisons of computing resources, model sizes, train and inference time between our proposed methods and baselines. In addition we delineate the cost per image using our method and other baselines.