 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Vision Encoder Grafting via LLM Surrogates
May 28, 2025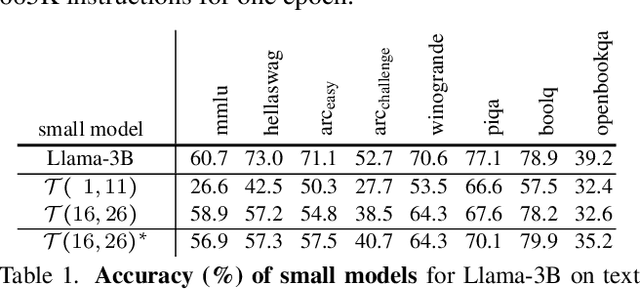
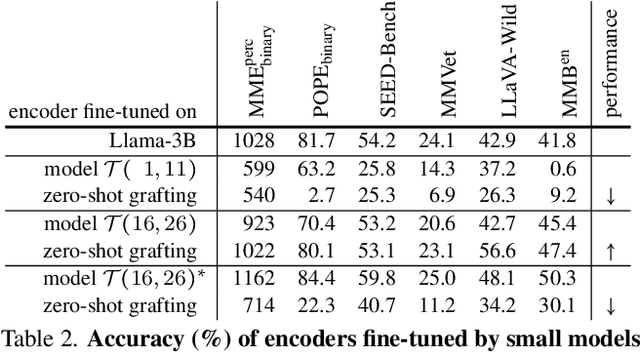
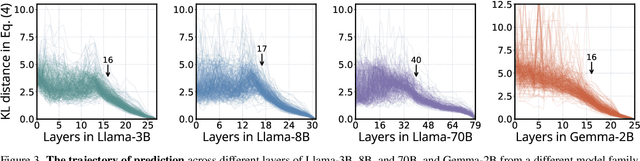

Vision language models (VLMs) typically pair a modestly sized vision encoder with a large language model (LLM), e.g., Llama-70B, making the decoder the primary computational burden during training. To reduce costs, a potential promising strategy is to first train the vision encoder using a small language model before transferring it to the large one. We construct small "surrogate models" that share the same embedding space and representation language as the large target LLM by directly inheriting its shallow layers. Vision encoders trained on the surrogate can then be directly transferred to the larger model, a process we call zero-shot grafting -- when plugged directly into the full-size target LLM, the grafted pair surpasses the encoder-surrogate pair and, on some benchmarks, even performs on par with full decoder training with the target LLM. Furthermore, our surrogate training approach reduces overall VLM training costs by ~45% when using Llama-70B as the decoder.
GenQA: Generating Millions of Instructions from a Handful of Prompts
Jun 14, 2024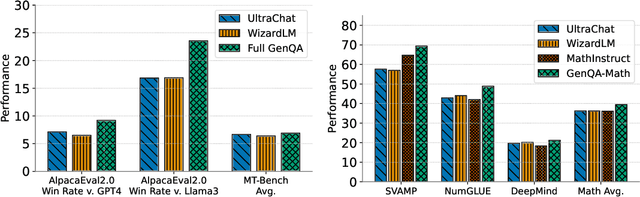
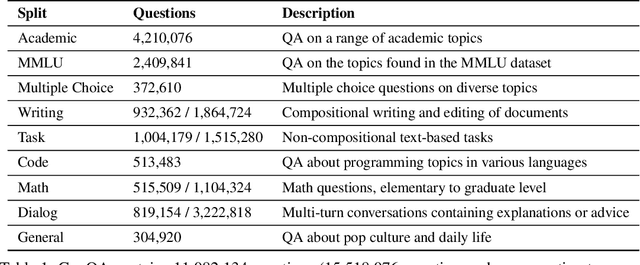
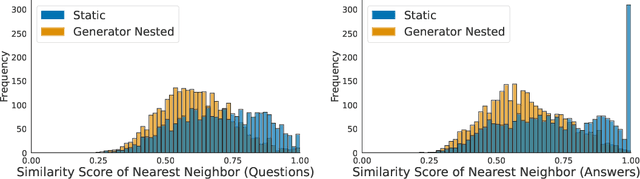
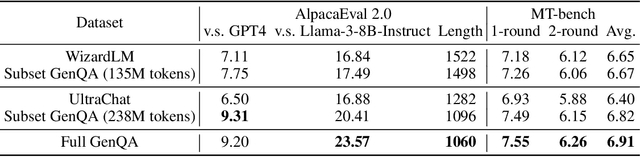
Most public instruction finetuning datasets are relatively small compared to the closed source datasets used to train industry models. To study questions about finetuning at scale, such as curricula and learning rate cooldown schedules, there is a need for industrial-scale datasets. However, this scale necessitates a data generation process that is almost entirely automated. In this work, we study methods for generating large instruction datasets from a single prompt. With little human oversight, we get LLMs to write diverse sets of instruction examples ranging from simple completion tasks to complex multi-turn dialogs across a variety of subject areas. When finetuning a Llama-3 8B base model, our dataset meets or exceeds both WizardLM and Ultrachat on both knowledge-intensive leaderboard tasks as well as conversational evaluations. We release our dataset, the "generator" prompts that created it, and our finetuned model checkpoints.