 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditCtrl: Disentangled Local and Global Control for Real-Time Generative Video Editing
Feb 16, 2026High-fidelity generative video editing has seen significant quality improvements by leveraging pre-trained video foundation models. However, their computational cost is a major bottleneck, as they are often designed to inefficiently process the full video context regardless of the inpainting mask's size, even for sparse, localized edits. In this paper, we introduce EditCtrl, an efficient video inpainting control framework that focuses computation only where it is needed. Our approach features a novel local video context module that operates solely on masked tokens, yielding a computational cost proportional to the edit size. This local-first generation is then guided by a lightweight temporal global context embedder that ensures video-wide context consistency with minimal overhead. Not only is EditCtrl 10 times more compute efficient than state-of-the-art generative editing methods, it even improves editing quality compared to methods designed with full-attention. Finally, we showcase how EditCtrl unlocks new capabilities, including multi-region editing with text prompts and autoregressive content propagation.
HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025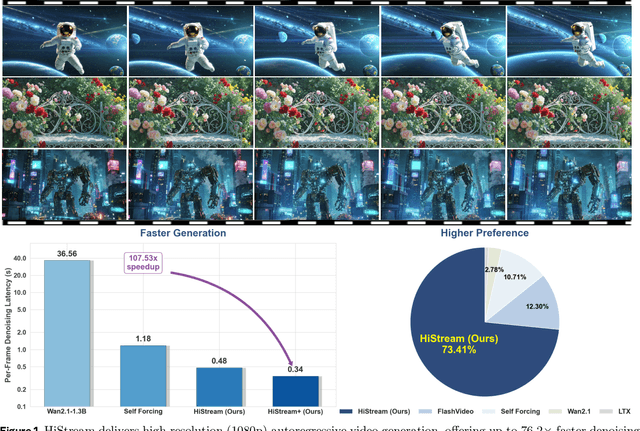
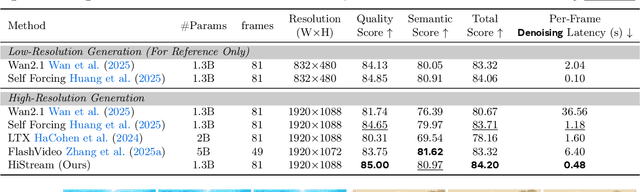
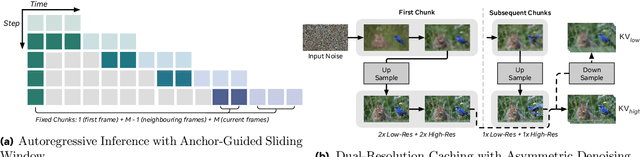
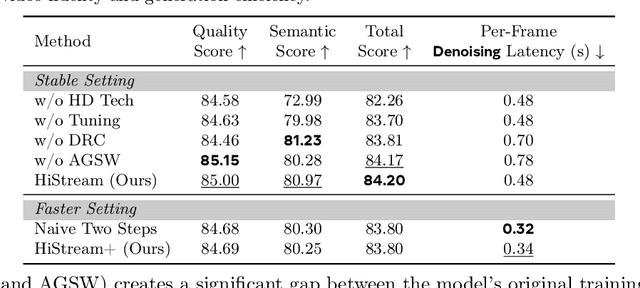
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
Graph-KV: Breaking Sequence via Injecting Structural Biases into Large Language Models
Jun 09, 2025Modern large language models (LLMs) are inherently auto-regressive, requiring input to be serialized into flat sequences regardless of their structural dependencies. This serialization hinders the model's ability to leverage structural inductive biases, especially in tasks such as retrieval-augmented generation (RAG) and reasoning on data with native graph structures, where inter-segment dependencies are crucial. We introduce Graph-KV with the potential to overcome this limitation. Graph-KV leverages the KV-cache of text segments as condensed representations and governs their interaction through structural inductive biases. In this framework, 'target' segments selectively attend only to the KV-caches of their designated 'source' segments, rather than all preceding segments in a serialized sequence. This approach induces a graph-structured block mask, sparsifying attention and enabling a message-passing-like step within the LLM. Furthermore, strategically allocated positional encodings for source and target segments reduce positional bias and context window consumption. We evaluate Graph-KV across three scenarios: (1) seven RAG benchmarks spanning direct inference, multi-hop reasoning, and long-document understanding; (2) Arxiv-QA, a novel academic paper QA task with full-text scientific papers structured as citation ego-graphs; and (3) paper topic classification within a citation network. By effectively reducing positional bias and harnessing structural inductive biases, Graph-KV substantially outperforms baselines, including standard costly sequential encoding, across various settings. Code and the Graph-KV data are publicly available.
Structural Alignment Improves Graph Test-Time Adaptation
Feb 25, 2025Graph-based learning has achieved remarkable success in domains ranging from recommendation to fraud detection and particle physics by effectively capturing underlying interaction patterns. However, it often struggles to generalize when distribution shifts occur, particularly those involving changes in network connectivity or interaction patterns. Existing approaches designed to mitigate such shifts typically require retraining with full access to source data, rendering them infeasible under strict computational or privacy constraints. To address this limitation, we propose a test-time structural alignment (TSA) algorithm for Graph Test-Time Adaptation (GTTA), a novel method that aligns graph structures during inference without revisiting the source domain. Built upon a theoretically grounded treatment of graph data distribution shifts, TSA integrates three key strategies: an uncertainty-aware neighborhood weighting that accommodates structure shifts, an adaptive balancing of self-node and neighborhood-aggregated representations driven by node representations' signal-to-noise ratio, and a decision boundary refinement that corrects remaining label and feature shifts. Extensive experiments on synthetic and real-world datasets demonstrate that TSA can consistently outperform both non-graph TTA methods and state-of-the-art GTTA baselines.
Model Generalization on Text Attribute Graphs: Principles with Large Language Models
Feb 17, 2025Large language models (LLMs) have recently been introduced to graph learning, aiming to extend their zero-shot generalization success to tasks where labeled graph data is scarce. Among these applications, inference over text-attributed graphs (TAGs) presents unique challenges: existing methods struggle with LLMs' limited context length for processing large node neighborhoods and the misalignment between node embeddings and the LLM token space. To address these issues, we establish two key principles for ensuring generalization and derive the framework LLM-BP accordingly: (1) Unifying the attribute space with task-adaptive embeddings, where we leverage LLM-based encoders and task-aware prompting to enhance generalization of the text attribute embeddings; (2) Developing a generalizable graph information aggregation mechanism, for which we adopt belief propagation with LLM-estimated parameters that adapt across graphs. Evaluations on 11 real-world TAG benchmarks demonstrate that LLM-BP significantly outperforms existing approaches, achieving 8.10% improvement with task-conditional embeddings and an additional 1.71% gain from adaptive aggregation.
Learning Flow Fields in Attention for Controllable Person Image Generation
Dec 12, 2024
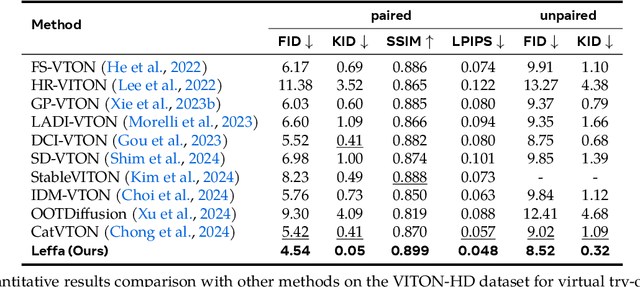
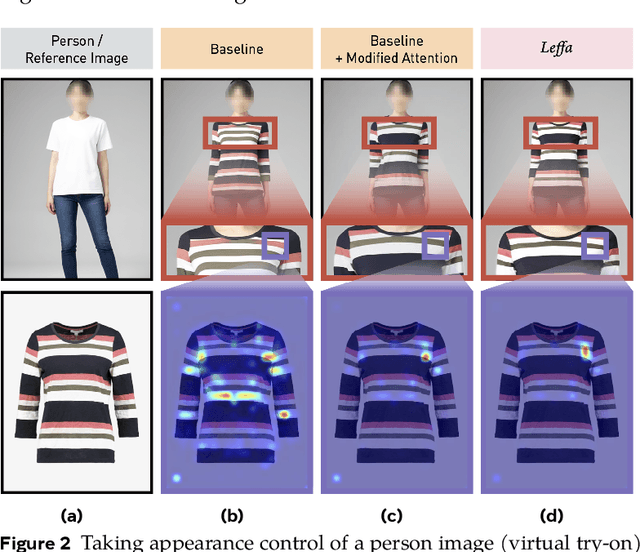
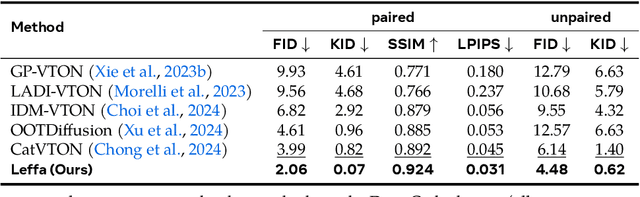
Controllable person image generation aims to generate a person image conditioned on reference images, allowing precise control over the person's appearance or pose. However, prior methods often distort fine-grained textural details from the reference image, despite achieving high overall image quality. We attribute these distortions to inadequate attention to corresponding regions in the reference image. To address this, we thereby propose learning flow fields in attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Specifically, it is realized via a regularization loss on top of the attention map within a diffusion-based baseline. Our extensive experiments show that Leffa achieves state-of-the-art performance in controlling appearance (virtual try-on) and pose (pose transfer), significantly reducing fine-grained detail distortion while maintaining high image quality. Additionally, we show that our loss is model-agnostic and can be used to improve the performance of other diffusion models.
MarDini: Masked Autoregressive Diffusion for Video Generation at Scale
Oct 26, 2024



We introduce MarDini, a new family of video diffusion models that integrate the advantages of masked auto-regression (MAR) into a unified diffusion model (DM) framework. Here, MAR handles temporal planning, while DM focuses on spatial generation in an asymmetric network design: i) a MAR-based planning model containing most of the parameters generates planning signals for each masked frame using low-resolution input; ii) a lightweight generation model uses these signals to produce high-resolution frames via diffusion de-noising. MarDini's MAR enables video generation conditioned on any number of masked frames at any frame positions: a single model can handle video interpolation (e.g., masking middle frames), image-to-video generation (e.g., masking from the second frame onward), and video expansion (e.g., masking half the frames). The efficient design allocates most of the computational resources to the low-resolution planning model, making computationally expensive but important spatio-temporal attention feasible at scale. MarDini sets a new state-of-the-art for video interpolation; meanwhile, within few inference steps, it efficiently generates videos on par with those of much more expensive advanced image-to-video models.
Pairwise Alignment Improves Graph Domain Adaptation
Mar 02, 2024



Graph-based methods, pivotal for label inference over interconnected objects in many real-world applications, often encounter generalization challenges, if the graph used for model training differs significantly from the graph used for testing. This work delves into Graph Domain Adaptation (GDA) to address the unique complexities of distribution shifts over graph data, where interconnected data points experience shifts in features, labels, and in particular, connecting patterns. We propose a novel, theoretically principled method, Pairwise Alignment (Pair-Align) to counter graph structure shift by mitigating conditional structure shift (CSS) and label shift (LS). Pair-Align uses edge weights to recalibrate the influence among neighboring nodes to handle CSS and adjusts the classification loss with label weights to handle LS. Our method demonstrates superior performance in real-world applications, including node classification with region shift in social networks, and the pileup mitigation task in particle colliding experiments. For the first application, we also curate the largest dataset by far for GDA studies. Our method shows strong performance in synthetic and other existing benchmark datasets.
EscherNet: A Generative Model for Scalable View Synthesis
Feb 06, 2024We introduce EscherNet, a multi-view conditioned diffusion model for view synthesis. EscherNet learns implicit and generative 3D representations coupled with a specialised camera positional encoding, allowing precise and continuous relative control of the camera transformation between an arbitrary number of reference and target views. EscherNet offers exceptional generality, flexibility, and scalability in view synthesis -- it can generate more than 100 consistent target views simultaneously on a single consumer-grade GPU, despite being trained with a fixed number of 3 reference views to 3 target views. As a result, EscherNet not only addresses zero-shot novel view synthesis, but also naturally unifies single- and multi-image 3D reconstruction, combining these diverse tasks into a single, cohesive framework. Our extensive experiments demonstrate that EscherNet achieves state-of-the-art performance in multiple benchmarks, even when compared to methods specifically tailored for each individual problem. This remarkable versatility opens up new directions for designing scalable neural architectures for 3D vision. Project page: \url{https://kxhit.github.io/EscherNet}.