 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV-Tracker: Real-Time Pose Tracking with Transformers
Dec 27, 2025Multi-view 3D geometry networks offer a powerful prior but are prohibitively slow for real-time applications. We propose a novel way to adapt them for online use, enabling real-time 6-DoF pose tracking and online reconstruction of objects and scenes from monocular RGB videos. Our method rapidly selects and manages a set of images as keyframes to map a scene or object via $π^3$ with full bidirectional attention. We then cache the global self-attention block's key-value (KV) pairs and use them as the sole scene representation for online tracking. This allows for up to $15\times$ speedup during inference without the fear of drift or catastrophic forgetting. Our caching strategy is model-agnostic and can be applied to other off-the-shelf multi-view networks without retraining. We demonstrate KV-Tracker on both scene-level tracking and the more challenging task of on-the-fly object tracking and reconstruction without depth measurements or object priors. Experiments on the TUM RGB-D, 7-Scenes, Arctic and OnePose datasets show the strong performance of our system while maintaining high frame-rates up to ${\sim}27$ FPS.
4D Primitive-Mâché: Glueing Primitives for Persistent 4D Scene Reconstruction
Dec 18, 2025We present a dynamic reconstruction system that receives a casual monocular RGB video as input, and outputs a complete and persistent reconstruction of the scene. In other words, we reconstruct not only the the currently visible parts of the scene, but also all previously viewed parts, which enables replaying the complete reconstruction across all timesteps. Our method decomposes the scene into a set of rigid 3D primitives, which are assumed to be moving throughout the scene. Using estimated dense 2D correspondences, we jointly infer the rigid motion of these primitives through an optimisation pipeline, yielding a 4D reconstruction of the scene, i.e. providing 3D geometry dynamically moving through time. To achieve this, we also introduce a mechanism to extrapolate motion for objects that become invisible, employing motion-grouping techniques to maintain continuity. The resulting system enables 4D spatio-temporal awareness, offering capabilities such as replayable 3D reconstructions of articulated objects through time, multi-object scanning, and object permanence. On object scanning and multi-object datasets, our system significantly outperforms existing methods both quantitatively and qualitatively.
ACE-SLAM: Scene Coordinate Regression for Neural Implicit Real-Time SLAM
Dec 16, 2025We present a novel neural RGB-D Simultaneous Localization And Mapping (SLAM) system that learns an implicit map of the scene in real time. For the first time, we explore the use of Scene Coordinate Regression (SCR) as the core implicit map representation in a neural SLAM pipeline, a paradigm that trains a lightweight network to directly map 2D image features to 3D global coordinates. SCR networks provide efficient, low-memory 3D map representations, enable extremely fast relocalization, and inherently preserve privacy, making them particularly suitable for neural implicit SLAM. Our system is the first one to achieve strict real-time in neural implicit RGB-D SLAM by relying on a SCR-based representation. We introduce a novel SCR architecture specifically tailored for this purpose and detail the critical design choices required to integrate SCR into a live SLAM pipeline. The resulting framework is simple yet flexible, seamlessly supporting both sparse and dense features, and operates reliably in dynamic environments without special adaptation. We evaluate our approach on established synthetic and real-world benchmarks, demonstrating competitive performance against the state of the art. Project Page: https://github.com/ialzugaray/ace-slam
EscherNet: A Generative Model for Scalable View Synthesis
Feb 06, 2024We introduce EscherNet, a multi-view conditioned diffusion model for view synthesis. EscherNet learns implicit and generative 3D representations coupled with a specialised camera positional encoding, allowing precise and continuous relative control of the camera transformation between an arbitrary number of reference and target views. EscherNet offers exceptional generality, flexibility, and scalability in view synthesis -- it can generate more than 100 consistent target views simultaneously on a single consumer-grade GPU, despite being trained with a fixed number of 3 reference views to 3 target views. As a result, EscherNet not only addresses zero-shot novel view synthesis, but also naturally unifies single- and multi-image 3D reconstruction, combining these diverse tasks into a single, cohesive framework. Our extensive experiments demonstrate that EscherNet achieves state-of-the-art performance in multiple benchmarks, even when compared to methods specifically tailored for each individual problem. This remarkable versatility opens up new directions for designing scalable neural architectures for 3D vision. Project page: \url{https://kxhit.github.io/EscherNet}.
Fit-NGP: Fitting Object Models to Neural Graphics Primitives
Jan 04, 2024



Accurate 3D object pose estimation is key to enabling many robotic applications that involve challenging object interactions. In this work, we show that the density field created by a state-of-the-art efficient radiance field reconstruction method is suitable for highly accurate and robust pose estimation for objects with known 3D models, even when they are very small and with challenging reflective surfaces. We present a fully automatic object pose estimation system based on a robot arm with a single wrist-mounted camera, which can scan a scene from scratch, detect and estimate the 6-Degrees of Freedom (DoF) poses of multiple objects within a couple of minutes of operation. Small objects such as bolts and nuts are estimated with accuracy on order of 1mm.
vMAP: Vectorised Object Mapping for Neural Field SLAM
Feb 03, 2023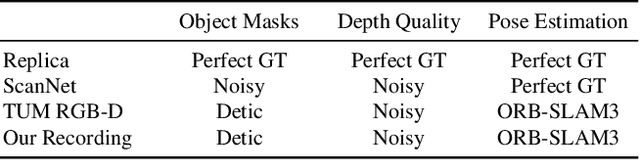
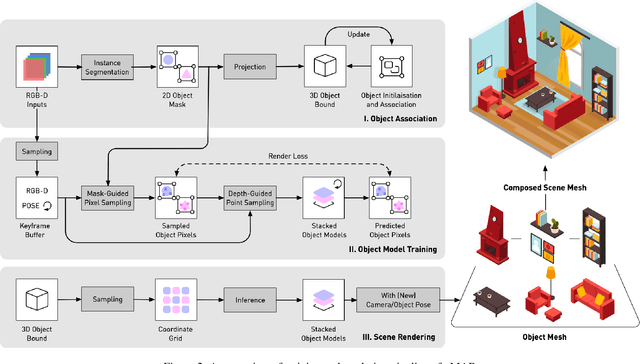


We present vMAP, an object-level dense SLAM system using neural field representations. Each object is represented by a small MLP, enabling efficient, watertight object modelling without the need for 3D priors. As an RGB-D camera browses a scene with no prior information, vMAP detects object instances on-the-fly, and dynamically adds them to its map. Specifically, thanks to the power of vectorised training, vMAP can optimise as many as 50 individual objects in a single scene, with an extremely efficient training speed of 5Hz map update. We experimentally demonstrate significantly improved scene-level and object-level reconstruction quality compared to prior neural field SLAM systems.