 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-SRAM Radiant Foam Rendering on a Graph Processor
Jan 07, 2026Many emerging many-core accelerators replace a single large device memory with hundreds to thousands of lightweight cores, each owning only a small local SRAM and exchanging data via explicit on-chip communication. This organization offers high aggregate bandwidth, but it breaks a key assumption behind many volumetric rendering techniques: that rays can randomly access a large, unified scene representation. Rendering efficiently on such hardware therefore requires distributing both data and computation, keeping ray traversal mostly local, and structuring communication into predictable routes. We present a fully in-SRAM, distributed renderer for the \emph{Radiant Foam} Voronoi-cell volumetric representation on the Graphcore Mk2 IPU, a many-core accelerator with tile-local SRAM and explicit inter-tile communication. Our system shards the scene across tiles and forwards rays between shards through a hierarchical routing overlay, enabling ray marching entirely from on-chip SRAM with predictable communication. On Mip-NeRF~360 scenes, the system attains near-interactive throughput (\(\approx\)1\,fps at \mbox{$640\times480$}) with image and depth quality close to the original GPU-based Radiant Foam implementation, while keeping all scene data and ray state in on-chip SRAM. Beyond demonstrating feasibility, we analyze routing, memory, and scheduling bottlenecks that inform how future distributed-memory accelerators can better support irregular, data-movement-heavy rendering workloads.
KV-Tracker: Real-Time Pose Tracking with Transformers
Dec 27, 2025Multi-view 3D geometry networks offer a powerful prior but are prohibitively slow for real-time applications. We propose a novel way to adapt them for online use, enabling real-time 6-DoF pose tracking and online reconstruction of objects and scenes from monocular RGB videos. Our method rapidly selects and manages a set of images as keyframes to map a scene or object via $π^3$ with full bidirectional attention. We then cache the global self-attention block's key-value (KV) pairs and use them as the sole scene representation for online tracking. This allows for up to $15\times$ speedup during inference without the fear of drift or catastrophic forgetting. Our caching strategy is model-agnostic and can be applied to other off-the-shelf multi-view networks without retraining. We demonstrate KV-Tracker on both scene-level tracking and the more challenging task of on-the-fly object tracking and reconstruction without depth measurements or object priors. Experiments on the TUM RGB-D, 7-Scenes, Arctic and OnePose datasets show the strong performance of our system while maintaining high frame-rates up to ${\sim}27$ FPS.
ACE-SLAM: Scene Coordinate Regression for Neural Implicit Real-Time SLAM
Dec 16, 2025We present a novel neural RGB-D Simultaneous Localization And Mapping (SLAM) system that learns an implicit map of the scene in real time. For the first time, we explore the use of Scene Coordinate Regression (SCR) as the core implicit map representation in a neural SLAM pipeline, a paradigm that trains a lightweight network to directly map 2D image features to 3D global coordinates. SCR networks provide efficient, low-memory 3D map representations, enable extremely fast relocalization, and inherently preserve privacy, making them particularly suitable for neural implicit SLAM. Our system is the first one to achieve strict real-time in neural implicit RGB-D SLAM by relying on a SCR-based representation. We introduce a novel SCR architecture specifically tailored for this purpose and detail the critical design choices required to integrate SCR into a live SLAM pipeline. The resulting framework is simple yet flexible, seamlessly supporting both sparse and dense features, and operates reliably in dynamic environments without special adaptation. We evaluate our approach on established synthetic and real-world benchmarks, demonstrating competitive performance against the state of the art. Project Page: https://github.com/ialzugaray/ace-slam
LiDAR Loop Closure Detection using Semantic Graphs with Graph Attention Networks
Jan 31, 2025In this paper, we propose a novel loop closure detection algorithm that uses graph attention neural networks to encode semantic graphs to perform place recognition and then use semantic registration to estimate the 6 DoF relative pose constraint. Our place recognition algorithm has two key modules, namely, a semantic graph encoder module and a graph comparison module. The semantic graph encoder employs graph attention networks to efficiently encode spatial, semantic and geometric information from the semantic graph of the input point cloud. We then use self-attention mechanism in both node-embedding and graph-embedding steps to create distinctive graph vectors. The graph vectors of the current scan and a keyframe scan are then compared in the graph comparison module to identify a possible loop closure. Specifically, employing the difference of the two graph vectors showed a significant improvement in performance, as shown in ablation studies. Lastly, we implemented a semantic registration algorithm that takes in loop closure candidate scans and estimates the relative 6 DoF pose constraint for the LiDAR SLAM system. Extensive evaluation on public datasets shows that our model is more accurate and robust, achieving 13% improvement in maximum F1 score on the SemanticKITTI dataset, when compared to the baseline semantic graph algorithm. For the benefit of the community, we open-source the complete implementation of our proposed algorithm and custom implementation of semantic registration at https://github.com/crepuscularlight/SemanticLoopClosure
Hyperion -- A fast, versatile symbolic Gaussian Belief Propagation framework for Continuous-Time SLAM
Jul 09, 2024
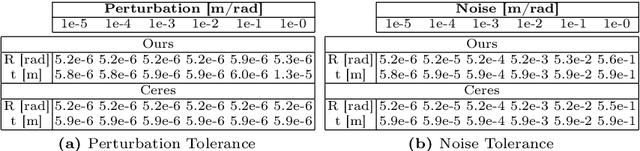
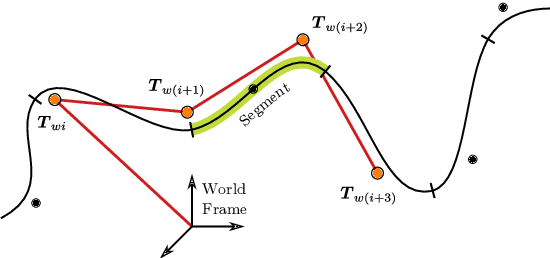
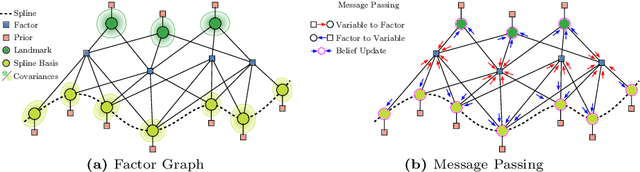
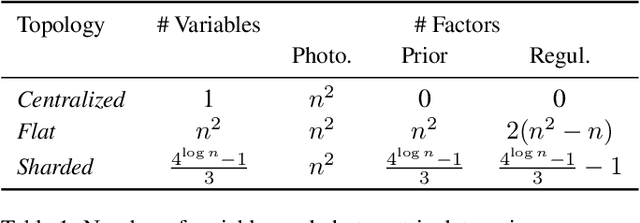
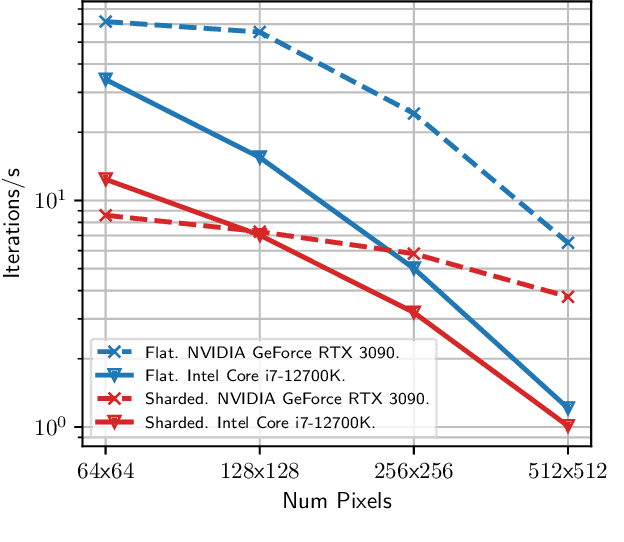
Continuous-Time Simultaneous Localization And Mapping (CTSLAM) has become a promising approach for fusing asynchronous and multi-modal sensor suites. Unlike discrete-time SLAM, which estimates poses discretely, CTSLAM uses continuous-time motion parametrizations, facilitating the integration of a variety of sensors such as rolling-shutter cameras, event cameras and Inertial Measurement Units (IMUs). However, CTSLAM approaches remain computationally demanding and are conventionally posed as centralized Non-Linear Least Squares (NLLS) optimizations. Targeting these limitations, we not only present the fastest SymForce-based [Martiros et al., RSS 2022] B- and Z-Spline implementations achieving speedups between 2.43x and 110.31x over Sommer et al. [CVPR 2020] but also implement a novel continuous-time Gaussian Belief Propagation (GBP) framework, coined Hyperion, which targets decentralized probabilistic inference across agents. We demonstrate the efficacy of our method in motion tracking and localization settings, complemented by empirical ablation studies.
PixRO: Pixel-Distributed Rotational Odometry with Gaussian Belief Propagation
Jun 14, 2024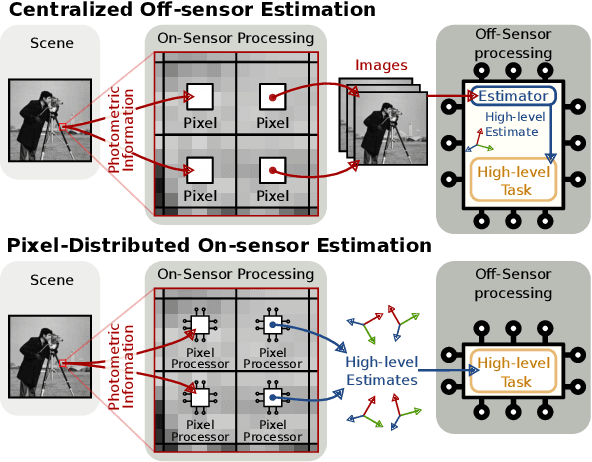
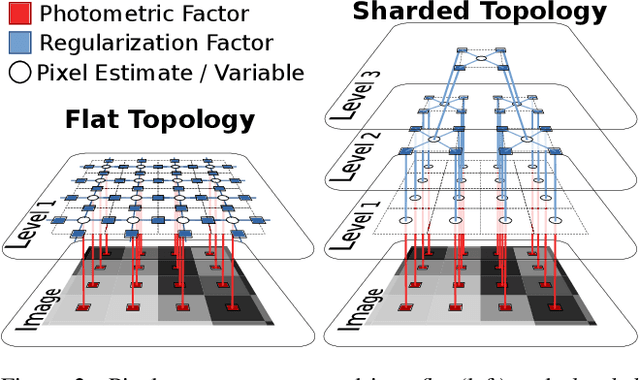
Visual sensors are not only becoming better at capturing high-quality images but also they have steadily increased their capabilities in processing data on their own on-chip. Yet the majority of VO pipelines rely on the transmission and processing of full images in a centralized unit (e.g. CPU or GPU), which often contain much redundant and low-quality information for the task. In this paper, we address the task of frame-to-frame rotational estimation but, instead of reasoning about relative motion between frames using the full images, distribute the estimation at pixel-level. In this paradigm, each pixel produces an estimate of the global motion by only relying on local information and local message-passing with neighbouring pixels. The resulting per-pixel estimates can then be communicated to downstream tasks, yielding higher-level, informative cues instead of the original raw pixel-readings. We evaluate the proposed approach on real public datasets, where we offer detailed insights about this novel technique and open-source our implementation for the future benefit of the community.
Distributed Simultaneous Localisation and Auto-Calibration using Gaussian Belief Propagation
Jan 26, 2024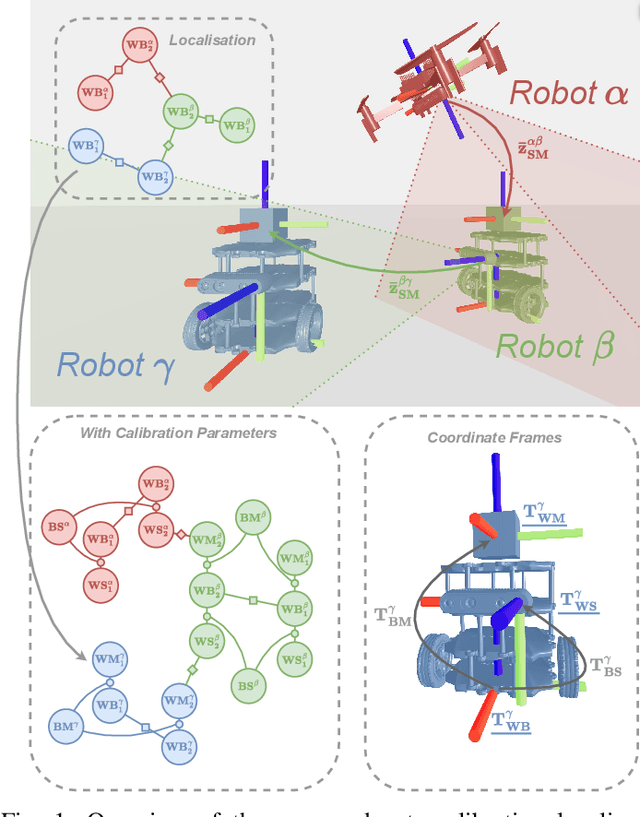
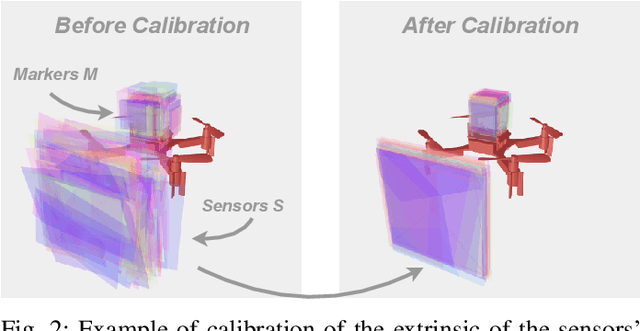
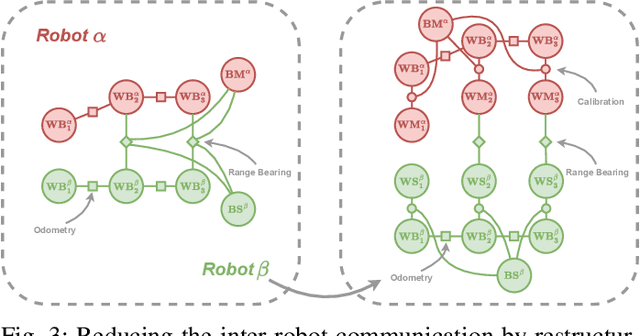
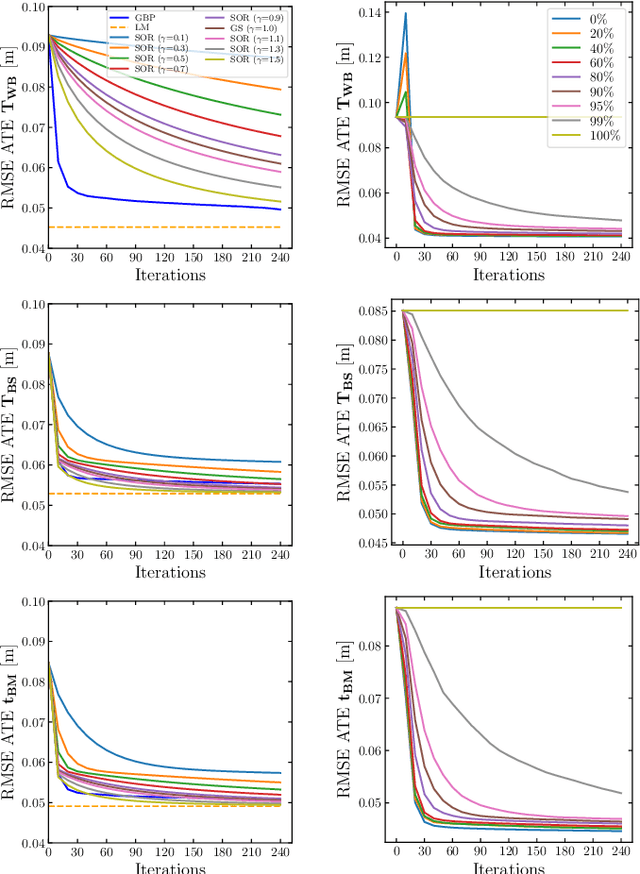
We present a novel scalable, fully distributed, and online method for simultaneous localisation and extrinsic calibration for multi-robot setups. Individual a priori unknown robot poses are probabilistically inferred as robots sense each other while simultaneously calibrating their sensors and markers extrinsic using Gaussian Belief Propagation. In the presented experiments, we show how our method not only yields accurate robot localisation and auto-calibration but also is able to perform under challenging circumstances such as highly noisy measurements, significant communication failures or limited communication range.
* Published in IEEE Robotics and Automation Letters (RA-L) 2024
Fit-NGP: Fitting Object Models to Neural Graphics Primitives
Jan 04, 2024



Accurate 3D object pose estimation is key to enabling many robotic applications that involve challenging object interactions. In this work, we show that the density field created by a state-of-the-art efficient radiance field reconstruction method is suitable for highly accurate and robust pose estimation for objects with known 3D models, even when they are very small and with challenging reflective surfaces. We present a fully automatic object pose estimation system based on a robot arm with a single wrist-mounted camera, which can scan a scene from scratch, detect and estimate the 6-Degrees of Freedom (DoF) poses of multiple objects within a couple of minutes of operation. Small objects such as bolts and nuts are estimated with accuracy on order of 1mm.
Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Dec 07, 2023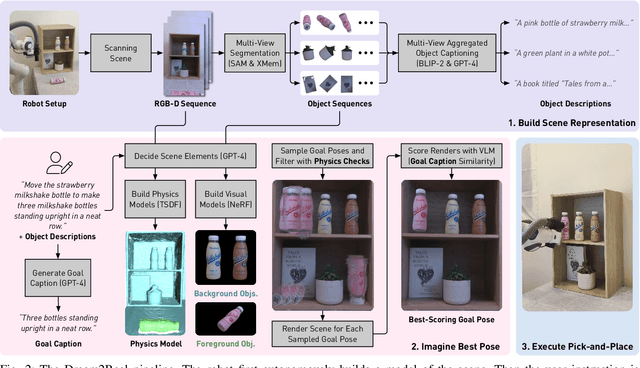

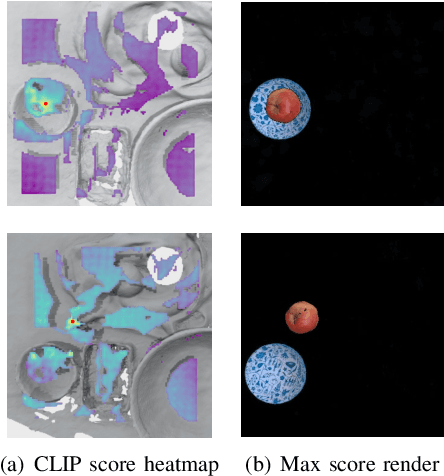

We introduce Dream2Real, a robotics framework which integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline. This is achieved by the robot autonomously constructing a 3D representation of the scene, where objects can be rearranged virtually and an image of the resulting arrangement rendered. These renders are evaluated by a VLM, so that the arrangement which best satisfies the user instruction is selected and recreated in the real world with pick-and-place. This enables language-conditioned rearrangement to be performed zero-shot, without needing to collect a training dataset of example arrangements. Results on a series of real-world tasks show that this framework is robust to distractors, controllable by language, capable of understanding complex multi-object relations, and readily applicable to both tabletop and 6-DoF rearrangement tasks.
Continuous-Time Gaussian Process Motion-Compensation for Event-vision Pattern Tracking with Distance Fields
Mar 05, 2023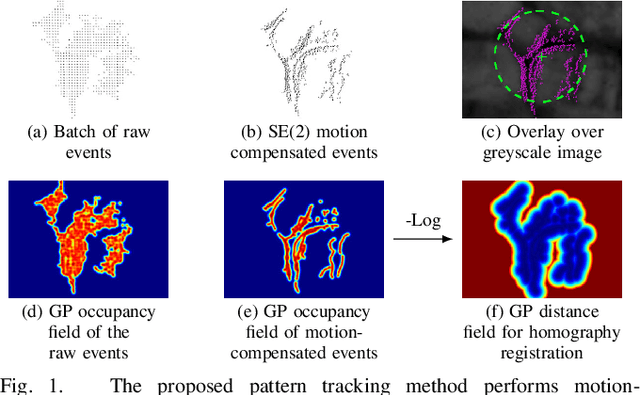



This work addresses the issue of motion compensation and pattern tracking in event camera data. An event camera generates asynchronous streams of events triggered independently by each of the pixels upon changes in the observed intensity. Providing great advantages in low-light and rapid-motion scenarios, such unconventional data present significant research challenges as traditional vision algorithms are not directly applicable to this sensing modality. The proposed method decomposes the tracking problem into a local SE(2) motion-compensation step followed by a homography registration of small motion-compensated event batches. The first component relies on Gaussian Process (GP) theory to model the continuous occupancy field of the events in the image plane and embed the camera trajectory in the covariance kernel function. In doing so, estimating the trajectory is done similarly to GP hyperparameter learning by maximising the log marginal likelihood of the data. The continuous occupancy fields are turned into distance fields and used as templates for homography-based registration. By benchmarking the proposed method against other state-of-the-art techniques, we show that our open-source implementation performs high-accuracy motion compensation and produces high-quality tracks in real-world scenarios.