 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning Just Enough: Lightweight Backdoor Attacks on Multi-Encoder Diffusion Models
Mar 04, 2026As text-to-image diffusion models become increasingly deployed in real-world applications, concerns about backdoor attacks have gained significant attention. Prior work on text-based backdoor attacks has largely focused on diffusion models conditioned on a single lightweight text encoder. However, more recent diffusion models that incorporate multiple large-scale text encoders remain underexplored in this context. Given the substantially increased number of trainable parameters introduced by multiple text encoders, an important question is whether backdoor attacks can remain both efficient and effective in such settings. In this work, we study Stable Diffusion 3, which uses three distinct text encoders and has not yet been systematically analyzed for text-encoder-based backdoor vulnerabilities. To understand the role of text encoders in backdoor attacks, we define four categories of attack targets and identify the minimal sets of encoders required to achieve effective performance for each attack objective. Based on this, we further propose Multi-Encoder Lightweight aTtacks (MELT), which trains only low-rank adapters while keeping the pretrained text encoder weight frozen. We demonstrate that tuning fewer than 0.2% of the total encoder parameters is sufficient for successful backdoor attacks on Stable Diffusion 3, revealing previously underexplored vulnerabilities in practical attack scenarios in multi-encoder settings.
GUI-ARP: Enhancing Grounding with Adaptive Region Perception for GUI Agents
Sep 19, 2025Existing GUI grounding methods often struggle with fine-grained localization in high-resolution screenshots. To address this, we propose GUI-ARP, a novel framework that enables adaptive multi-stage inference. Equipped with the proposed Adaptive Region Perception (ARP) and Adaptive Stage Controlling (ASC), GUI-ARP dynamically exploits visual attention for cropping task-relevant regions and adapts its inference strategy, performing a single-stage inference for simple cases and a multi-stage analysis for more complex scenarios. This is achieved through a two-phase training pipeline that integrates supervised fine-tuning with reinforcement fine-tuning based on Group Relative Policy Optimization (GRPO). Extensive experiments demonstrate that the proposed GUI-ARP achieves state-of-the-art performance on challenging GUI grounding benchmarks, with a 7B model reaching 60.8% accuracy on ScreenSpot-Pro and 30.9% on UI-Vision benchmark. Notably, GUI-ARP-7B demonstrates strong competitiveness against open-source 72B models (UI-TARS-72B at 38.1%) and proprietary models.
TGPO: Tree-Guided Preference Optimization for Robust Web Agent Reinforcement Learning
Sep 19, 2025With the rapid advancement of large language models and vision-language models, employing large models as Web Agents has become essential for automated web interaction. However, training Web Agents with reinforcement learning faces critical challenges including credit assignment misallocation, prohibitively high annotation costs, and reward sparsity. To address these issues, we propose Tree-Guided Preference Optimization (TGPO), an offline reinforcement learning framework that proposes a tree-structured trajectory representation merging semantically identical states across trajectories to eliminate label conflicts. Our framework incorporates a Process Reward Model that automatically generates fine-grained rewards through subgoal progress, redundancy detection, and action verification. Additionally, a dynamic weighting mechanism prioritizes high-impact decision points during training. Experiments on Online-Mind2Web and our self-constructed C-WebShop datasets demonstrate that TGPO significantly outperforms existing methods, achieving higher success rates with fewer redundant steps.
Spend Wisely: Maximizing Post-Training Gains in Iterative Synthetic Data Boostrapping
Jan 31, 2025



Modern foundation models often undergo iterative ``bootstrapping'' in their post-training phase: a model generates synthetic data, an external verifier filters out low-quality samples, and the high-quality subset is used for further fine-tuning. Over multiple iterations, the model's performance improves--raising a crucial question: how should the total budget on generation and training be allocated across iterations to maximize final performance? In this work, we develop a theoretical framework to analyze budget allocation strategies. Specifically, we show that constant policies fail to converge with high probability, while increasing policies--particularly exponential growth policies--exhibit significant theoretical advantages. Experiments on image denoising with diffusion probabilistic models and math reasoning with large language models show that both exponential and polynomial growth policies consistently outperform constant policies, with exponential policies often providing more stable performance.
Matrix Completion via Residual Spectral Matching
Dec 13, 2024



Noisy matrix completion has attracted significant attention due to its applications in recommendation systems, signal processing and image restoration. Most existing works rely on (weighted) least squares methods under various low-rank constraints. However, minimizing the sum of squared residuals is not always efficient, as it may ignore the potential structural information in the residuals.In this study, we propose a novel residual spectral matching criterion that incorporates not only the numerical but also locational information of residuals. This criterion is the first in noisy matrix completion to adopt the perspective of low-rank perturbation of random matrices and exploit the spectral properties of sparse random matrices. We derive optimal statistical properties by analyzing the spectral properties of sparse random matrices and bounding the effects of low-rank perturbations and partial observations. Additionally, we propose algorithms that efficiently approximate solutions by constructing easily computable pseudo-gradients. The iterative process of the proposed algorithms ensures convergence at a rate consistent with the optimal statistical error bound. Our method and algorithms demonstrate improved numerical performance in both simulated and real data examples, particularly in environments with high noise levels.
SeMOPO: Learning High-quality Model and Policy from Low-quality Offline Visual Datasets
Jun 13, 2024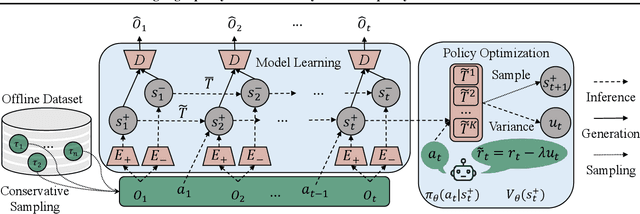
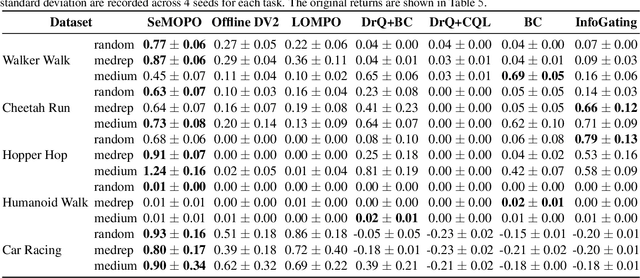
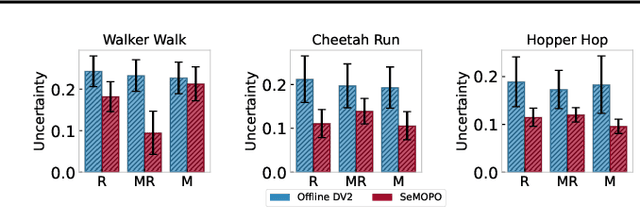
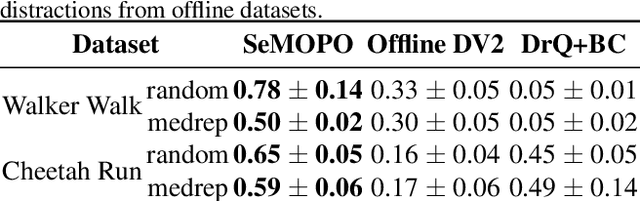
Model-based offline reinforcement Learning (RL) is a promising approach that leverages existing data effectively in many real-world applications, especially those involving high-dimensional inputs like images and videos. To alleviate the distribution shift issue in offline RL, existing model-based methods heavily rely on the uncertainty of learned dynamics. However, the model uncertainty estimation becomes significantly biased when observations contain complex distractors with non-trivial dynamics. To address this challenge, we propose a new approach - \emph{Separated Model-based Offline Policy Optimization} (SeMOPO) - decomposing latent states into endogenous and exogenous parts via conservative sampling and estimating model uncertainty on the endogenous states only. We provide a theoretical guarantee of model uncertainty and performance bound of SeMOPO. To assess the efficacy, we construct the Low-Quality Vision Deep Data-Driven Datasets for RL (LQV-D4RL), where the data are collected by non-expert policy and the observations include moving distractors. Experimental results show that our method substantially outperforms all baseline methods, and further analytical experiments validate the critical designs in our method. The project website is \href{https://sites.google.com/view/semopo}{https://sites.google.com/view/semopo}.