 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealMirror: A Comprehensive, Open-Source Vision-Language-Action Platform for Embodied AI
Sep 18, 2025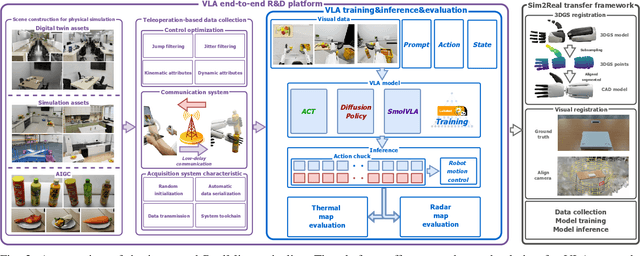
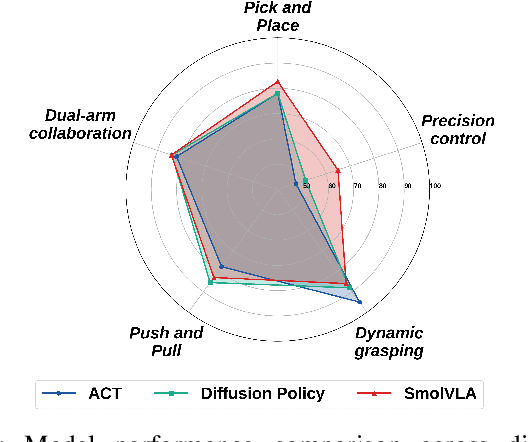
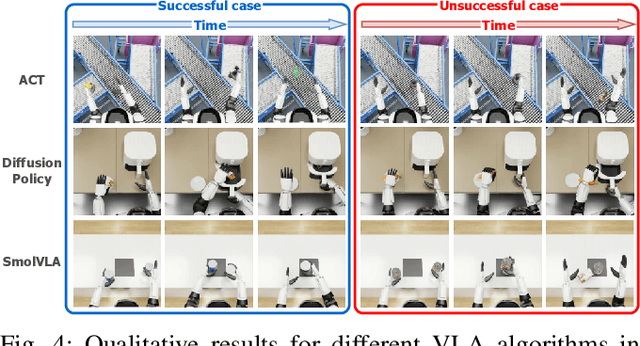

The emerging field of Vision-Language-Action (VLA) for humanoid robots faces several fundamental challenges, including the high cost of data acquisition, the lack of a standardized benchmark, and the significant gap between simulation and the real world. To overcome these obstacles, we propose RealMirror, a comprehensive, open-source embodied AI VLA platform. RealMirror builds an efficient, low-cost data collection, model training, and inference system that enables end-to-end VLA research without requiring a real robot. To facilitate model evolution and fair comparison, we also introduce a dedicated VLA benchmark for humanoid robots, featuring multiple scenarios, extensive trajectories, and various VLA models. Furthermore, by integrating generative models and 3D Gaussian Splatting to reconstruct realistic environments and robot models, we successfully demonstrate zero-shot Sim2Real transfer, where models trained exclusively on simulation data can perform tasks on a real robot seamlessly, without any fine-tuning. In conclusion, with the unification of these critical components, RealMirror provides a robust framework that significantly accelerates the development of VLA models for humanoid robots. Project page: https://terminators2025.github.io/RealMirror.github.io
SeMOPO: Learning High-quality Model and Policy from Low-quality Offline Visual Datasets
Jun 13, 2024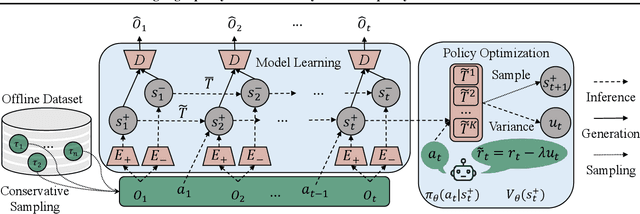
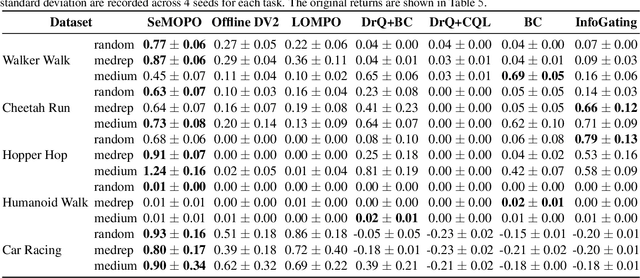
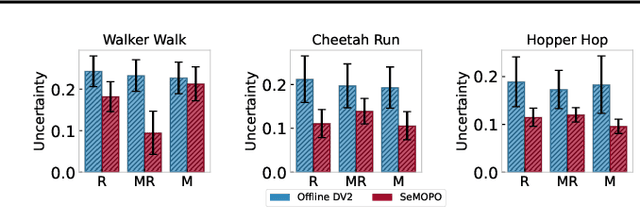
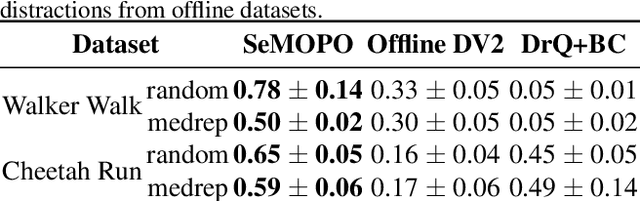
Model-based offline reinforcement Learning (RL) is a promising approach that leverages existing data effectively in many real-world applications, especially those involving high-dimensional inputs like images and videos. To alleviate the distribution shift issue in offline RL, existing model-based methods heavily rely on the uncertainty of learned dynamics. However, the model uncertainty estimation becomes significantly biased when observations contain complex distractors with non-trivial dynamics. To address this challenge, we propose a new approach - \emph{Separated Model-based Offline Policy Optimization} (SeMOPO) - decomposing latent states into endogenous and exogenous parts via conservative sampling and estimating model uncertainty on the endogenous states only. We provide a theoretical guarantee of model uncertainty and performance bound of SeMOPO. To assess the efficacy, we construct the Low-Quality Vision Deep Data-Driven Datasets for RL (LQV-D4RL), where the data are collected by non-expert policy and the observations include moving distractors. Experimental results show that our method substantially outperforms all baseline methods, and further analytical experiments validate the critical designs in our method. The project website is \href{https://sites.google.com/view/semopo}{https://sites.google.com/view/semopo}.
SENSOR: Imitate Third-Person Expert's Behaviors via Active Sensoring
Apr 04, 2024
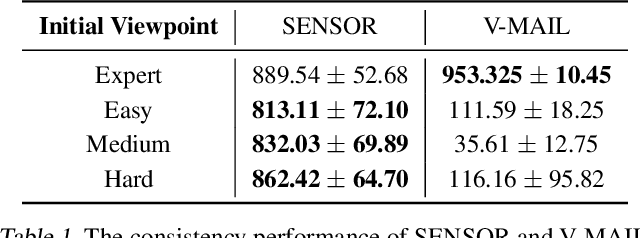


In many real-world visual Imitation Learning (IL) scenarios, there is a misalignment between the agent's and the expert's perspectives, which might lead to the failure of imitation. Previous methods have generally solved this problem by domain alignment, which incurs extra computation and storage costs, and these methods fail to handle the \textit{hard cases} where the viewpoint gap is too large. To alleviate the above problems, we introduce active sensoring in the visual IL setting and propose a model-based SENSory imitatOR (SENSOR) to automatically change the agent's perspective to match the expert's. SENSOR jointly learns a world model to capture the dynamics of latent states, a sensor policy to control the camera, and a motor policy to control the agent. Experiments on visual locomotion tasks show that SENSOR can efficiently simulate the expert's perspective and strategy, and outperforms most baseline methods.
DIDA: Denoised Imitation Learning based on Domain Adaptation
Apr 04, 2024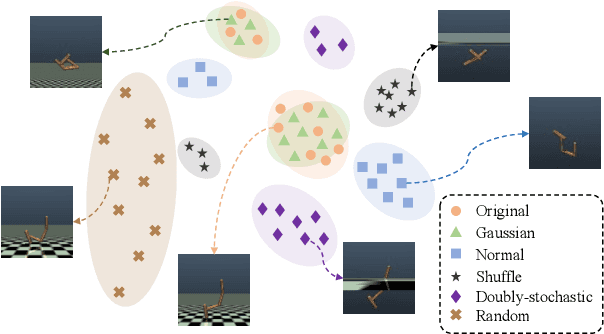
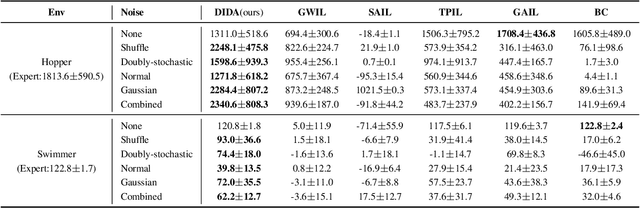
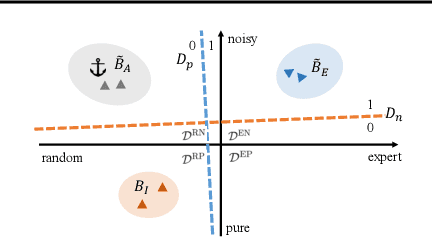

Imitating skills from low-quality datasets, such as sub-optimal demonstrations and observations with distractors, is common in real-world applications. In this work, we focus on the problem of Learning from Noisy Demonstrations (LND), where the imitator is required to learn from data with noise that often occurs during the processes of data collection or transmission. Previous IL methods improve the robustness of learned policies by injecting an adversarially learned Gaussian noise into pure expert data or utilizing additional ranking information, but they may fail in the LND setting. To alleviate the above problems, we propose Denoised Imitation learning based on Domain Adaptation (DIDA), which designs two discriminators to distinguish the noise level and expertise level of data, facilitating a feature encoder to learn task-related but domain-agnostic representations. Experiment results on MuJoCo demonstrate that DIDA can successfully handle challenging imitation tasks from demonstrations with various types of noise, outperforming most baseline methods.
AD3: Implicit Action is the Key for World Models to Distinguish the Diverse Visual Distractors
Mar 15, 2024Model-based methods have significantly contributed to distinguishing task-irrelevant distractors for visual control. However, prior research has primarily focused on heterogeneous distractors like noisy background videos, leaving homogeneous distractors that closely resemble controllable agents largely unexplored, which poses significant challenges to existing methods. To tackle this problem, we propose Implicit Action Generator (IAG) to learn the implicit actions of visual distractors, and present a new algorithm named implicit Action-informed Diverse visual Distractors Distinguisher (AD3), that leverages the action inferred by IAG to train separated world models. Implicit actions effectively capture the behavior of background distractors, aiding in distinguishing the task-irrelevant components, and the agent can optimize the policy within the task-relevant state space. Our method achieves superior performance on various visual control tasks featuring both heterogeneous and homogeneous distractors. The indispensable role of implicit actions learned by IAG is also empirically validated.
Quantized Consensus under Data-Rate Constraints and DoS Attacks: A Zooming-In and Holding Approach
Jul 18, 2022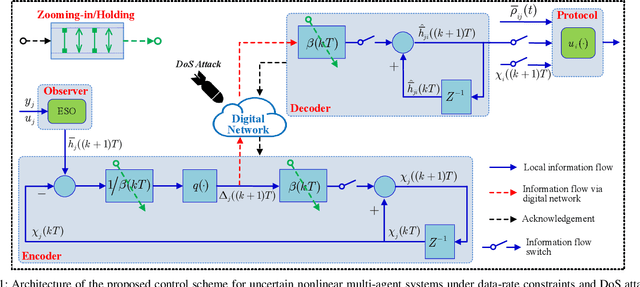
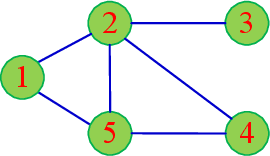
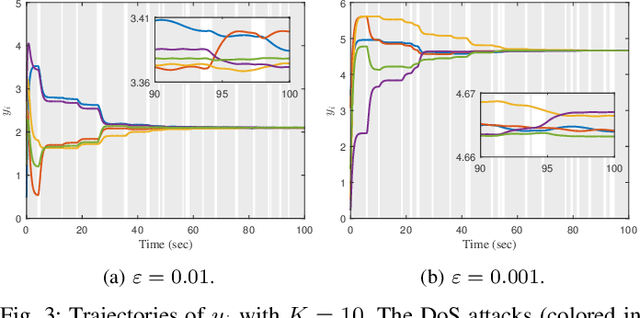
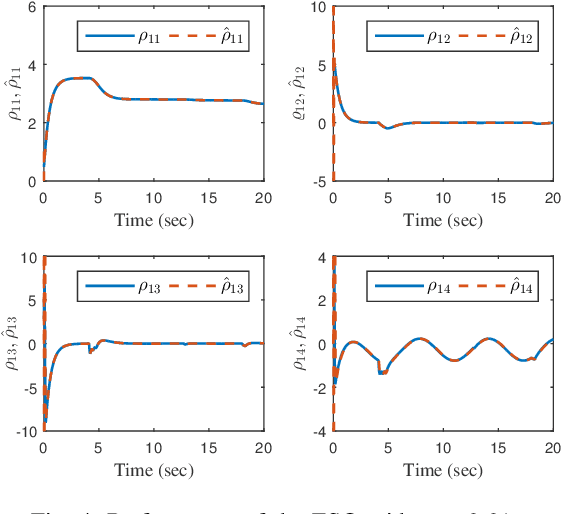
This paper is concerned with the quantized consensus problem for uncertain nonlinear multi-agent systems under data-rate constraints and Denial-of-Service (DoS) attacks. The agents are modeled in strict-feedback form with unknown nonlinear dynamics and external disturbance. Extended state observers (ESOs) are leveraged to estimate agents' total uncertainties along with their states. To mitigate the effects of DoS attacks, a novel dynamic quantization with zooming-in and holding capabilities is proposed. The idea is to zoom-in and hold the variable to be quantized if the system is in the absence and presence of DoS attacks, respectively. The control protocol is given in terms of the outputs of the ESOs and the dynamic-quantization-based encoders and decoders. We show that, for a connected undirected network, the developed control protocol is capable of handling any DoS attacks inducing bounded consecutive packet losses with merely 3-level quantization. The application of the zooming-in and holding approach to known linear multi-agent systems is also discussed.
READ: Aggregating Reconstruction Error into Out-of-distribution Detection
Jun 15, 2022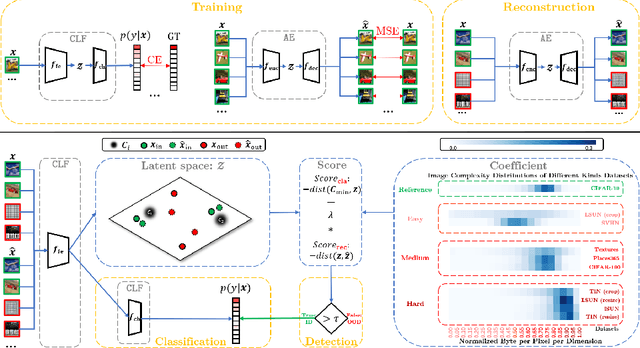
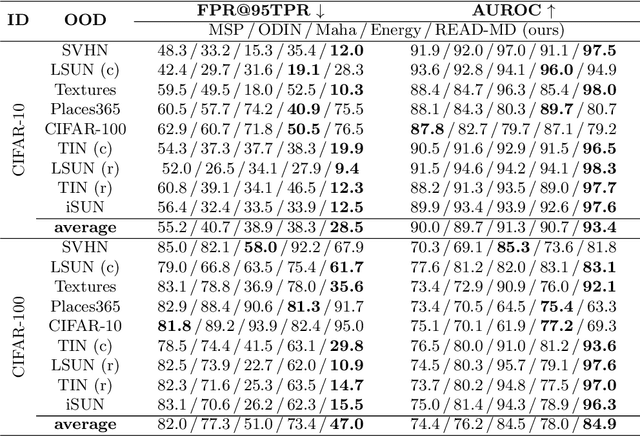
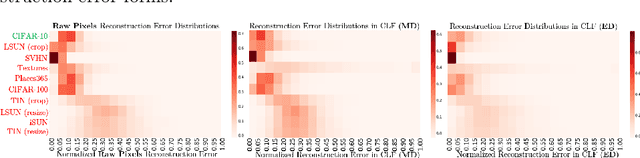
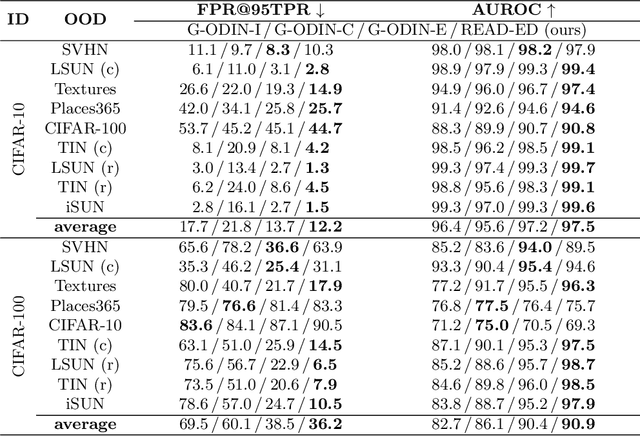
Detecting out-of-distribution (OOD) samples is crucial to the safe deployment of a classifier in the real world. However, deep neural networks are known to be overconfident for abnormal data. Existing works directly design score function by mining the inconsistency from classifier for in-distribution (ID) and OOD. In this paper, we further complement this inconsistency with reconstruction error, based on the assumption that an autoencoder trained on ID data can not reconstruct OOD as well as ID. We propose a novel method, READ (Reconstruction Error Aggregated Detector), to unify inconsistencies from classifier and autoencoder. Specifically, the reconstruction error of raw pixels is transformed to latent space of classifier. We show that the transformed reconstruction error bridges the semantic gap and inherits detection performance from the original. Moreover, we propose an adjustment strategy to alleviate the overconfidence problem of autoencoder according to a fine-grained characterization of OOD data. Under two scenarios of pre-training and retraining, we respectively present two variants of our method, namely READ-MD (Mahalanobis Distance) only based on pre-trained classifier and READ-ED (Euclidean Distance) which retrains the classifier. Our methods do not require access to test time OOD data for fine-tuning hyperparameters. Finally, we demonstrate the effectiveness of the proposed methods through extensive comparisons with state-of-the-art OOD detection algorithms. On a CIFAR-10 pre-trained WideResNet, our method reduces the average FPR@95TPR by up to 9.8% compared with previous state-of-the-art.