 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
Dec 03, 2024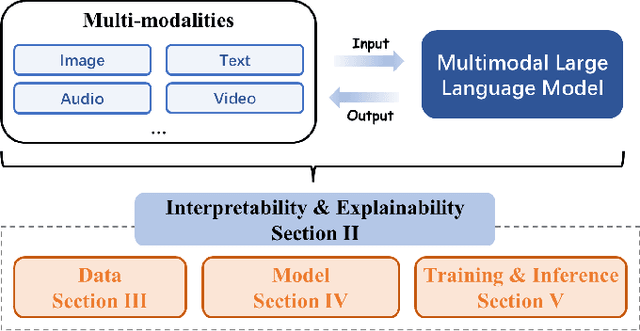
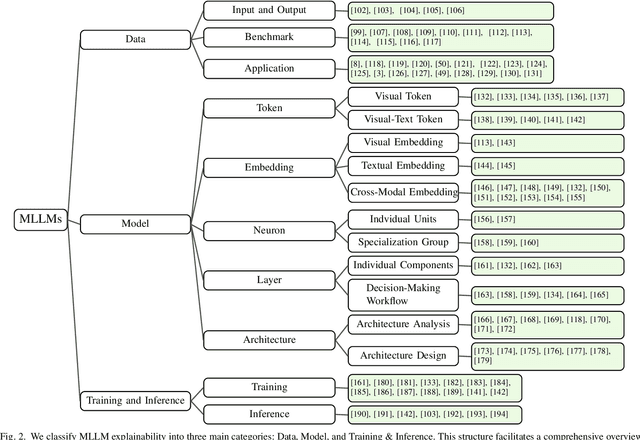
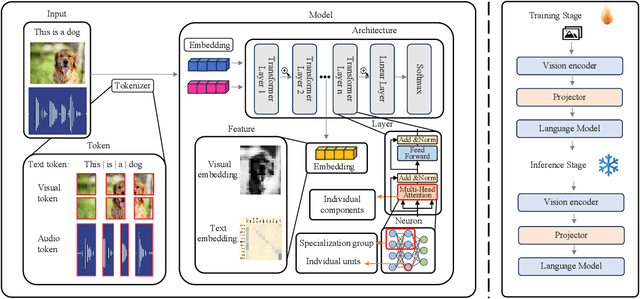
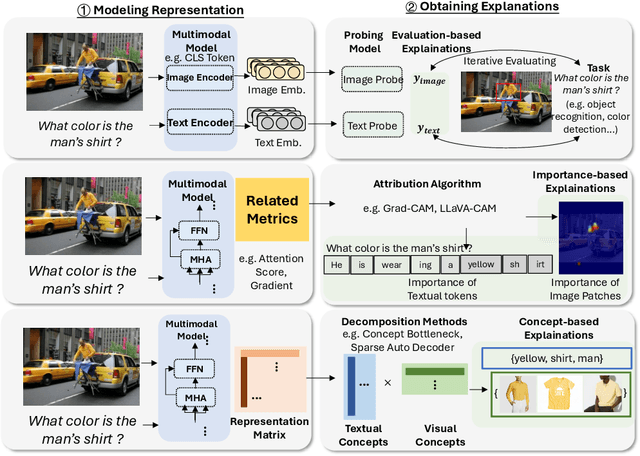
The rapid development of Artificial Intelligence (AI) has revolutionized numerous fields, with large language models (LLMs) and computer vision (CV) systems driving advancements in natural language understanding and visual processing, respectively. The convergence of these technologies has catalyzed the rise of multimodal AI, enabling richer, cross-modal understanding that spans text, vision, audio, and video modalities. Multimodal large language models (MLLMs), in particular, have emerged as a powerful framework, demonstrating impressive capabilities in tasks like image-text generation, visual question answering, and cross-modal retrieval. Despite these advancements, the complexity and scale of MLLMs introduce significant challenges in interpretability and explainability, essential for establishing transparency, trustworthiness, and reliability in high-stakes applications. This paper provides a comprehensive survey on the interpretability and explainability of MLLMs, proposing a novel framework that categorizes existing research across three perspectives: (I) Data, (II) Model, (III) Training \& Inference. We systematically analyze interpretability from token-level to embedding-level representations, assess approaches related to both architecture analysis and design, and explore training and inference strategies that enhance transparency. By comparing various methodologies, we identify their strengths and limitations and propose future research directions to address unresolved challenges in multimodal explainability. This survey offers a foundational resource for advancing interpretability and transparency in MLLMs, guiding researchers and practitioners toward developing more accountable and robust multimodal AI systems.
MINER: Mining the Underlying Pattern of Modality-Specific Neurons in Multimodal Large Language Models
Oct 07, 2024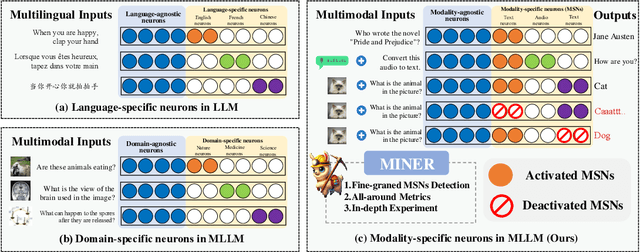
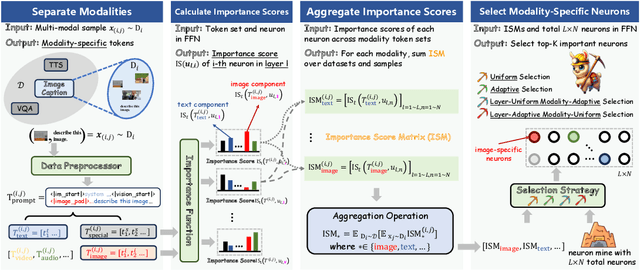
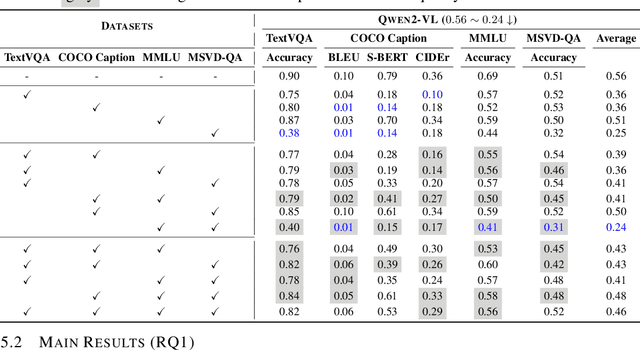

In recent years, multimodal large language models (MLLMs) have significantly advanced, integrating more modalities into diverse applications. However, the lack of explainability remains a major barrier to their use in scenarios requiring decision transparency. Current neuron-level explanation paradigms mainly focus on knowledge localization or language- and domain-specific analyses, leaving the exploration of multimodality largely unaddressed. To tackle these challenges, we propose MINER, a transferable framework for mining modality-specific neurons (MSNs) in MLLMs, which comprises four stages: (1) modality separation, (2) importance score calculation, (3) importance score aggregation, (4) modality-specific neuron selection. Extensive experiments across six benchmarks and two representative MLLMs show that (I) deactivating ONLY 2% of MSNs significantly reduces MLLMs performance (0.56 to 0.24 for Qwen2-VL, 0.69 to 0.31 for Qwen2-Audio), (II) different modalities mainly converge in the lower layers, (III) MSNs influence how key information from various modalities converges to the last token, (IV) two intriguing phenomena worth further investigation, i.e., semantic probing and semantic telomeres. The source code is available at this URL.
SENSOR: Imitate Third-Person Expert's Behaviors via Active Sensoring
Apr 04, 2024
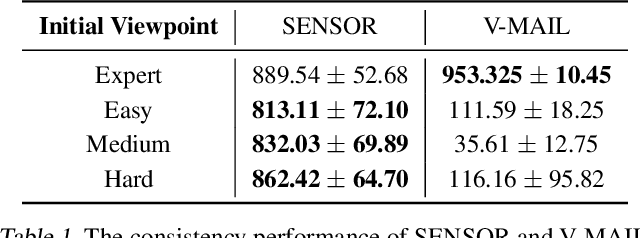


In many real-world visual Imitation Learning (IL) scenarios, there is a misalignment between the agent's and the expert's perspectives, which might lead to the failure of imitation. Previous methods have generally solved this problem by domain alignment, which incurs extra computation and storage costs, and these methods fail to handle the \textit{hard cases} where the viewpoint gap is too large. To alleviate the above problems, we introduce active sensoring in the visual IL setting and propose a model-based SENSory imitatOR (SENSOR) to automatically change the agent's perspective to match the expert's. SENSOR jointly learns a world model to capture the dynamics of latent states, a sensor policy to control the camera, and a motor policy to control the agent. Experiments on visual locomotion tasks show that SENSOR can efficiently simulate the expert's perspective and strategy, and outperforms most baseline methods.
DIDA: Denoised Imitation Learning based on Domain Adaptation
Apr 04, 2024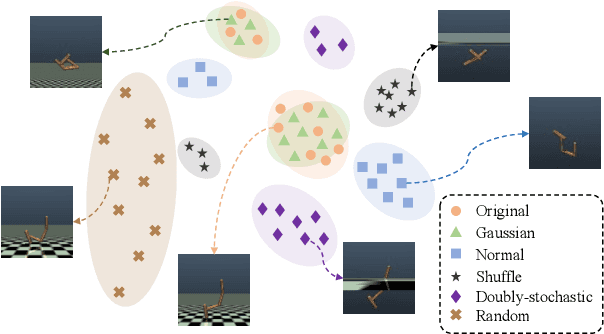
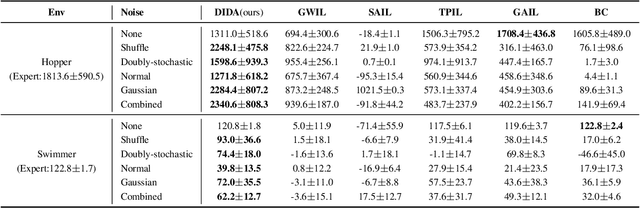
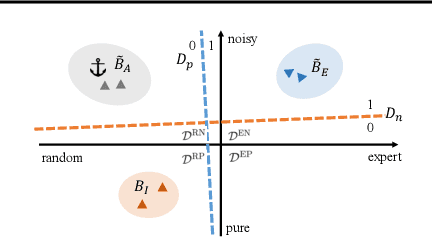

Imitating skills from low-quality datasets, such as sub-optimal demonstrations and observations with distractors, is common in real-world applications. In this work, we focus on the problem of Learning from Noisy Demonstrations (LND), where the imitator is required to learn from data with noise that often occurs during the processes of data collection or transmission. Previous IL methods improve the robustness of learned policies by injecting an adversarially learned Gaussian noise into pure expert data or utilizing additional ranking information, but they may fail in the LND setting. To alleviate the above problems, we propose Denoised Imitation learning based on Domain Adaptation (DIDA), which designs two discriminators to distinguish the noise level and expertise level of data, facilitating a feature encoder to learn task-related but domain-agnostic representations. Experiment results on MuJoCo demonstrate that DIDA can successfully handle challenging imitation tasks from demonstrations with various types of noise, outperforming most baseline methods.