 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD^2: Constrained Dataset Distillation for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) receives significant attention from the public to perform classification continuously with a few training samples, which suffers from the key catastrophic forgetting problem. Existing methods usually employ an external memory to store previous knowledge and treat it with incremental classes equally, which cannot properly preserve previous essential knowledge. To solve this problem and inspired by recent distillation works on knowledge transfer, we propose a framework termed \textbf{C}onstrained \textbf{D}ataset \textbf{D}istillation (\textbf{CD$^2$}) to facilitate FSCIL, which includes a dataset distillation module (\textbf{DDM}) and a distillation constraint module~(\textbf{DCM}). Specifically, the DDM synthesizes highly condensed samples guided by the classifier, forcing the model to learn compacted essential class-related clues from a few incremental samples. The DCM introduces a designed loss to constrain the previously learned class distribution, which can preserve distilled knowledge more sufficiently. Extensive experiments on three public datasets show the superiority of our method against other state-of-the-art competitors.
Guided Path Sampling: Steering Diffusion Models Back on Track with Principled Path Guidance
Dec 28, 2025Iterative refinement methods based on a denoising-inversion cycle are powerful tools for enhancing the quality and control of diffusion models. However, their effectiveness is critically limited when combined with standard Classifier-Free Guidance (CFG). We identify a fundamental limitation: CFG's extrapolative nature systematically pushes the sampling path off the data manifold, causing the approximation error to diverge and undermining the refinement process. To address this, we propose Guided Path Sampling (GPS), a new paradigm for iterative refinement. GPS replaces unstable extrapolation with a principled, manifold-constrained interpolation, ensuring the sampling path remains on the data manifold. We theoretically prove that this correction transforms the error series from unbounded amplification to strictly bounded, guaranteeing stability. Furthermore, we devise an optimal scheduling strategy that dynamically adjusts guidance strength, aligning semantic injection with the model's natural coarse-to-fine generation process. Extensive experiments on modern backbones like SDXL and Hunyuan-DiT show that GPS outperforms existing methods in both perceptual quality and complex prompt adherence. For instance, GPS achieves a superior ImageReward of 0.79 and HPS v2 of 0.2995 on SDXL, while improving overall semantic alignment accuracy on GenEval to 57.45%. Our work establishes that path stability is a prerequisite for effective iterative refinement, and GPS provides a robust framework to achieve it.
ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
Oct 09, 2025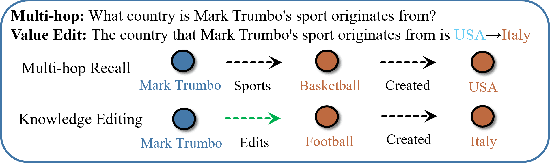

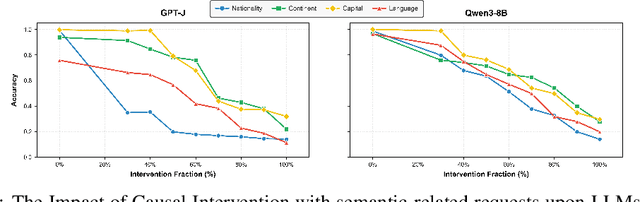
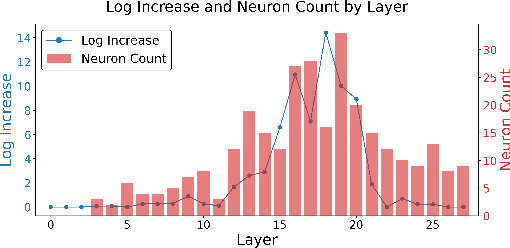
Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi hop reasoning, implicit subjects function as query neurons, which sequentially activate corresponding value neurons across transformer layers to accumulate information toward the final answer, a dynamic prior KE work has overlooked. Guided by this insight, we propose ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall, a framework that leverages neuron-level attribution to identify and edit these critical query-value (Q-V) pathways. ACE provides a mechanistically grounded solution for multi-hop KE, empirically outperforming state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B. Our analysis further reveals more fine-grained activation patterns in Qwen3 and demonstrates that the semantic interpretability of value neurons is orchestrated by query-driven accumulation. These findings establish a new pathway for advancing KE capabilities based on the principled understanding of internal reasoning mechanisms.
From High-SNR Radar Signal to ECG: A Transfer Learning Model with Cardio-Focusing Algorithm for Scenarios with Limited Data
Jun 24, 2025Electrocardiogram (ECG), as a crucial find-grained cardiac feature, has been successfully recovered from radar signals in the literature, but the performance heavily relies on the high-quality radar signal and numerous radar-ECG pairs for training, restricting the applications in new scenarios due to data scarcity. Therefore, this work will focus on radar-based ECG recovery in new scenarios with limited data and propose a cardio-focusing and -tracking (CFT) algorithm to precisely track the cardiac location to ensure an efficient acquisition of high-quality radar signals. Furthermore, a transfer learning model (RFcardi) is proposed to extract cardio-related information from the radar signal without ECG ground truth based on the intrinsic sparsity of cardiac features, and only a few synchronous radar-ECG pairs are required to fine-tune the pre-trained model for the ECG recovery. The experimental results reveal that the proposed CFT can dynamically identify the cardiac location, and the RFcardi model can effectively generate faithful ECG recoveries after using a small number of radar-ECG pairs for training. The code and dataset are available after the publication.
Da Yu: Towards USV-Based Image Captioning for Waterway Surveillance and Scene Understanding
Jun 24, 2025Automated waterway environment perception is crucial for enabling unmanned surface vessels (USVs) to understand their surroundings and make informed decisions. Most existing waterway perception models primarily focus on instance-level object perception paradigms (e.g., detection, segmentation). However, due to the complexity of waterway environments, current perception datasets and models fail to achieve global semantic understanding of waterways, limiting large-scale monitoring and structured log generation. With the advancement of vision-language models (VLMs), we leverage image captioning to introduce WaterCaption, the first captioning dataset specifically designed for waterway environments. WaterCaption focuses on fine-grained, multi-region long-text descriptions, providing a new research direction for visual geo-understanding and spatial scene cognition. Exactly, it includes 20.2k image-text pair data with 1.8 million vocabulary size. Additionally, we propose Da Yu, an edge-deployable multi-modal large language model for USVs, where we propose a novel vision-to-language projector called Nano Transformer Adaptor (NTA). NTA effectively balances computational efficiency with the capacity for both global and fine-grained local modeling of visual features, thereby significantly enhancing the model's ability to generate long-form textual outputs. Da Yu achieves an optimal balance between performance and efficiency, surpassing state-of-the-art models on WaterCaption and several other captioning benchmarks.
IMTS is Worth Time $\times$ Channel Patches: Visual Masked Autoencoders for Irregular Multivariate Time Series Prediction
May 28, 2025Irregular Multivariate Time Series (IMTS) forecasting is challenging due to the unaligned nature of multi-channel signals and the prevalence of extensive missing data. Existing methods struggle to capture reliable temporal patterns from such data due to significant missing values. While pre-trained foundation models show potential for addressing these challenges, they are typically designed for Regularly Sampled Time Series (RTS). Motivated by the visual Mask AutoEncoder's (MAE) powerful capability for modeling sparse multi-channel information and its success in RTS forecasting, we propose VIMTS, a framework adapting Visual MAE for IMTS forecasting. To mitigate the effect of missing values, VIMTS first processes IMTS along the timeline into feature patches at equal intervals. These patches are then complemented using learned cross-channel dependencies. Then it leverages visual MAE's capability in handling sparse multichannel data for patch reconstruction, followed by a coarse-to-fine technique to generate precise predictions from focused contexts. In addition, we integrate self-supervised learning for improved IMTS modeling by adapting the visual MAE to IMTS data. Extensive experiments demonstrate VIMTS's superior performance and few-shot capability, advancing the application of visual foundation models in more general time series tasks. Our code is available at https://github.com/WHU-HZY/VIMTS.
Robust Hypothesis Generation: LLM-Automated Language Bias for Inductive Logic Programming
May 27, 2025Automating robust hypothesis generation in open environments is pivotal for AI cognition. We introduce a novel framework integrating a multi-agent system, powered by Large Language Models (LLMs), with Inductive Logic Programming (ILP). Our system's LLM agents autonomously define a structured symbolic vocabulary (predicates) and relational templates , i.e., \emph{language bias} directly from raw textual data. This automated symbolic grounding (the construction of the language bias), traditionally an expert-driven bottleneck for ILP, then guides the transformation of text into facts for an ILP solver, which inductively learns interpretable rules. This approach overcomes traditional ILP's reliance on predefined symbolic structures and the noise-sensitivity of pure LLM methods. Extensive experiments in diverse, challenging scenarios validate superior performance, paving a new path for automated, explainable, and verifiable hypothesis generation.
Interpreting Social Bias in LVLMs via Information Flow Analysis and Multi-Round Dialogue Evaluation
May 27, 2025Large Vision Language Models (LVLMs) have achieved remarkable progress in multimodal tasks, yet they also exhibit notable social biases. These biases often manifest as unintended associations between neutral concepts and sensitive human attributes, leading to disparate model behaviors across demographic groups. While existing studies primarily focus on detecting and quantifying such biases, they offer limited insight into the underlying mechanisms within the models. To address this gap, we propose an explanatory framework that combines information flow analysis with multi-round dialogue evaluation, aiming to understand the origin of social bias from the perspective of imbalanced internal information utilization. Specifically, we first identify high-contribution image tokens involved in the model's reasoning process for neutral questions via information flow analysis. Then, we design a multi-turn dialogue mechanism to evaluate the extent to which these key tokens encode sensitive information. Extensive experiments reveal that LVLMs exhibit systematic disparities in information usage when processing images of different demographic groups, suggesting that social bias is deeply rooted in the model's internal reasoning dynamics. Furthermore, we complement our findings from a textual modality perspective, showing that the model's semantic representations already display biased proximity patterns, thereby offering a cross-modal explanation of bias formation.
An Empirical Study of the Anchoring Effect in LLMs: Existence, Mechanism, and Potential Mitigations
May 21, 2025The rise of Large Language Models (LLMs) like ChatGPT has advanced natural language processing, yet concerns about cognitive biases are growing. In this paper, we investigate the anchoring effect, a cognitive bias where the mind relies heavily on the first information as anchors to make affected judgments. We explore whether LLMs are affected by anchoring, the underlying mechanisms, and potential mitigation strategies. To facilitate studies at scale on the anchoring effect, we introduce a new dataset, SynAnchors. Combining refined evaluation metrics, we benchmark current widely used LLMs. Our findings show that LLMs' anchoring bias exists commonly with shallow-layer acting and is not eliminated by conventional strategies, while reasoning can offer some mitigation. This recontextualization via cognitive psychology urges that LLM evaluations focus not on standard benchmarks or over-optimized robustness tests, but on cognitive-bias-aware trustworthy evaluation.
Recover from Horcrux: A Spectrogram Augmentation Method for Cardiac Feature Monitoring from Radar Signal Components
Mar 25, 2025Radar-based wellness monitoring is becoming an effective measurement to provide accurate vital signs in a contactless manner, but data scarcity retards the related research on deep-learning-based methods. Data augmentation is commonly used to enrich the dataset by modifying the existing data, but most augmentation techniques can only couple with classification tasks. To enable the augmentation for regression tasks, this research proposes a spectrogram augmentation method, Horcrux, for radar-based cardiac feature monitoring (e.g., heartbeat detection, electrocardiogram reconstruction) with both classification and regression tasks involved. The proposed method is designed to increase the diversity of input samples while the augmented spectrogram is still faithful to the original ground truth vital sign. In addition, Horcrux proposes to inject zero values in specific areas to enhance the awareness of the deep learning model on subtle cardiac features, improving the performance for the limited dataset. Experimental result shows that Horcrux achieves an overall improvement of 16.20% in cardiac monitoring and has the potential to be extended to other spectrogram-based tasks. The code will be released upon publication.