 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoFlow-SLAM: Real-Time Endoscopic SLAM with Flow-Constrained Gaussian Splatting
Jun 26, 2025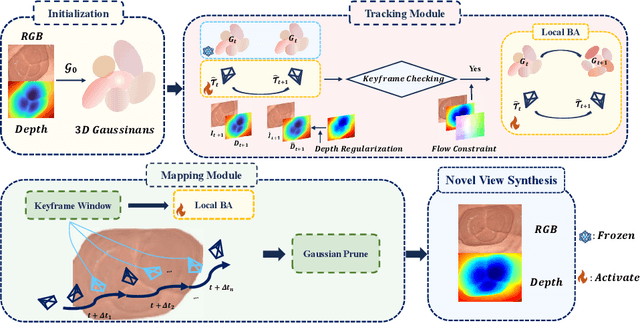
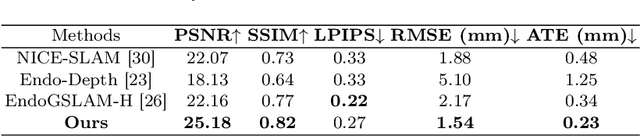
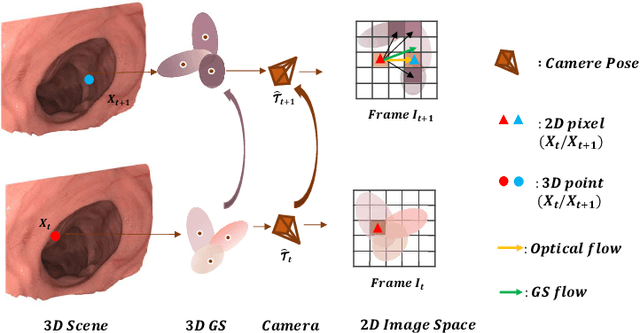
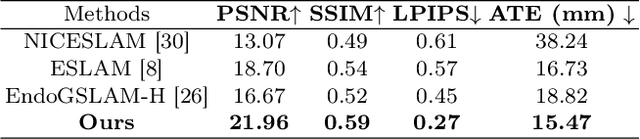
Efficient three-dimensional reconstruction and real-time visualization are critical in surgical scenarios such as endoscopy. In recent years, 3D Gaussian Splatting (3DGS) has demonstrated remarkable performance in efficient 3D reconstruction and rendering. Most 3DGS-based Simultaneous Localization and Mapping (SLAM) methods only rely on the appearance constraints for optimizing both 3DGS and camera poses. However, in endoscopic scenarios, the challenges include photometric inconsistencies caused by non-Lambertian surfaces and dynamic motion from breathing affects the performance of SLAM systems. To address these issues, we additionally introduce optical flow loss as a geometric constraint, which effectively constrains both the 3D structure of the scene and the camera motion. Furthermore, we propose a depth regularisation strategy to mitigate the problem of photometric inconsistencies and ensure the validity of 3DGS depth rendering in endoscopic scenes. In addition, to improve scene representation in the SLAM system, we improve the 3DGS refinement strategy by focusing on viewpoints corresponding to Keyframes with suboptimal rendering quality frames, achieving better rendering results. Extensive experiments on the C3VD static dataset and the StereoMIS dynamic dataset demonstrate that our method outperforms existing state-of-the-art methods in novel view synthesis and pose estimation, exhibiting high performance in both static and dynamic surgical scenes. The source code will be publicly available upon paper acceptance.
From High-SNR Radar Signal to ECG: A Transfer Learning Model with Cardio-Focusing Algorithm for Scenarios with Limited Data
Jun 24, 2025Electrocardiogram (ECG), as a crucial find-grained cardiac feature, has been successfully recovered from radar signals in the literature, but the performance heavily relies on the high-quality radar signal and numerous radar-ECG pairs for training, restricting the applications in new scenarios due to data scarcity. Therefore, this work will focus on radar-based ECG recovery in new scenarios with limited data and propose a cardio-focusing and -tracking (CFT) algorithm to precisely track the cardiac location to ensure an efficient acquisition of high-quality radar signals. Furthermore, a transfer learning model (RFcardi) is proposed to extract cardio-related information from the radar signal without ECG ground truth based on the intrinsic sparsity of cardiac features, and only a few synchronous radar-ECG pairs are required to fine-tune the pre-trained model for the ECG recovery. The experimental results reveal that the proposed CFT can dynamically identify the cardiac location, and the RFcardi model can effectively generate faithful ECG recoveries after using a small number of radar-ECG pairs for training. The code and dataset are available after the publication.
RadarNeXt: Real-Time and Reliable 3D Object Detector Based On 4D mmWave Imaging Radar
Jan 04, 2025



3D object detection is crucial for Autonomous Driving (AD) and Advanced Driver Assistance Systems (ADAS). However, most 3D detectors prioritize detection accuracy, often overlooking network inference speed in practical applications. In this paper, we propose RadarNeXt, a real-time and reliable 3D object detector based on the 4D mmWave radar point clouds. It leverages the re-parameterizable neural networks to catch multi-scale features, reduce memory cost and accelerate the inference. Moreover, to highlight the irregular foreground features of radar point clouds and suppress background clutter, we propose a Multi-path Deformable Foreground Enhancement Network (MDFEN), ensuring detection accuracy while minimizing the sacrifice of speed and excessive number of parameters. Experimental results on View-of-Delft and TJ4DRadSet datasets validate the exceptional performance and efficiency of RadarNeXt, achieving 50.48 and 32.30 mAPs with the variant using our proposed MDFEN. Notably, our RadarNeXt variants achieve inference speeds of over 67.10 FPS on the RTX A4000 GPU and 28.40 FPS on the Jetson AGX Orin. This research demonstrates that RadarNeXt brings a novel and effective paradigm for 3D perception based on 4D mmWave radar.
NanoMVG: USV-Centric Low-Power Multi-Task Visual Grounding based on Prompt-Guided Camera and 4D mmWave Radar
Aug 30, 2024



Recently, visual grounding and multi-sensors setting have been incorporated into perception system for terrestrial autonomous driving systems and Unmanned Surface Vehicles (USVs), yet the high complexity of modern learning-based visual grounding model using multi-sensors prevents such model to be deployed on USVs in the real-life. To this end, we design a low-power multi-task model named NanoMVG for waterway embodied perception, guiding both camera and 4D millimeter-wave radar to locate specific object(s) through natural language. NanoMVG can perform both box-level and mask-level visual grounding tasks simultaneously. Compared to other visual grounding models, NanoMVG achieves highly competitive performance on the WaterVG dataset, particularly in harsh environments and boasts ultra-low power consumption for long endurance.
Achelous++: Power-Oriented Water-Surface Panoptic Perception Framework on Edge Devices based on Vision-Radar Fusion and Pruning of Heterogeneous Modalities
Dec 14, 2023



Urban water-surface robust perception serves as the foundation for intelligent monitoring of aquatic environments and the autonomous navigation and operation of unmanned vessels, especially in the context of waterway safety. It is worth noting that current multi-sensor fusion and multi-task learning models consume substantial power and heavily rely on high-power GPUs for inference. This contributes to increased carbon emissions, a concern that runs counter to the prevailing emphasis on environmental preservation and the pursuit of sustainable, low-carbon urban environments. In light of these concerns, this paper concentrates on low-power, lightweight, multi-task panoptic perception through the fusion of visual and 4D radar data, which is seen as a promising low-cost perception method. We propose a framework named Achelous++ that facilitates the development and comprehensive evaluation of multi-task water-surface panoptic perception models. Achelous++ can simultaneously execute five perception tasks with high speed and low power consumption, including object detection, object semantic segmentation, drivable-area segmentation, waterline segmentation, and radar point cloud semantic segmentation. Furthermore, to meet the demand for developers to customize models for real-time inference on low-performance devices, a novel multi-modal pruning strategy known as Heterogeneous-Aware SynFlow (HA-SynFlow) is proposed. Besides, Achelous++ also supports random pruning at initialization with different layer-wise sparsity, such as Uniform and Erdos-Renyi-Kernel (ERK). Overall, our Achelous++ framework achieves state-of-the-art performance on the WaterScenes benchmark, excelling in both accuracy and power efficiency compared to other single-task and multi-task models. We release and maintain the code at https://github.com/GuanRunwei/Achelous.
H2O+: An Improved Framework for Hybrid Offline-and-Online RL with Dynamics Gaps
Sep 22, 2023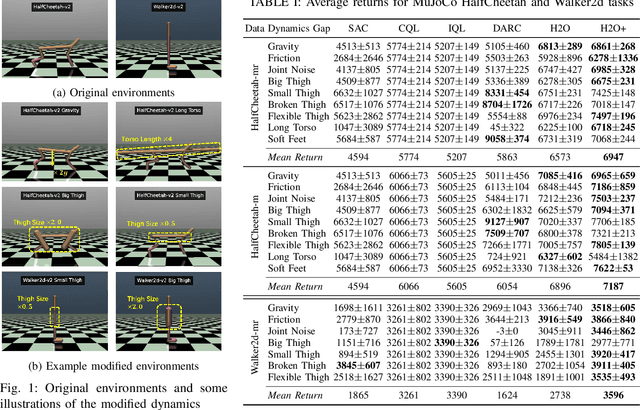
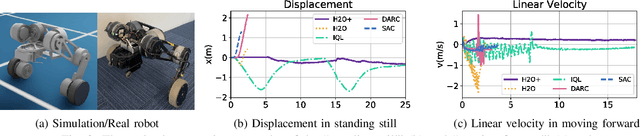
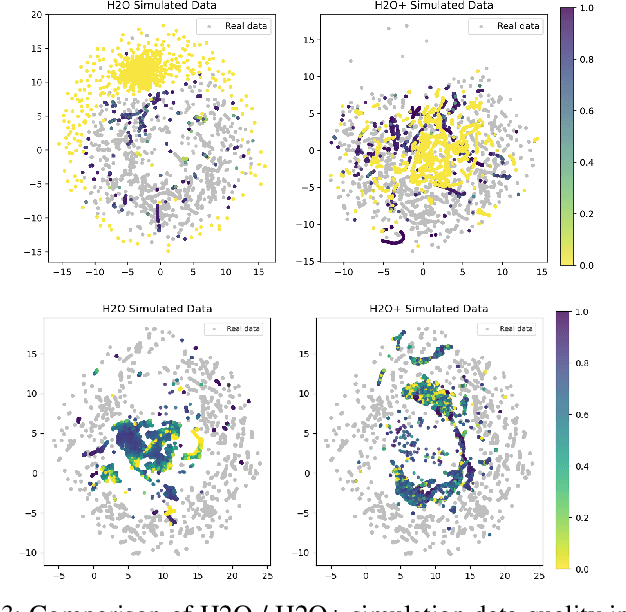
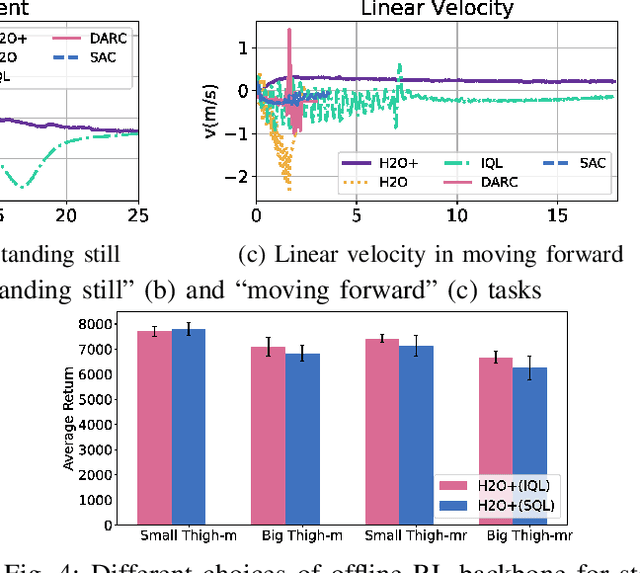
Solving real-world complex tasks using reinforcement learning (RL) without high-fidelity simulation environments or large amounts of offline data can be quite challenging. Online RL agents trained in imperfect simulation environments can suffer from severe sim-to-real issues. Offline RL approaches although bypass the need for simulators, often pose demanding requirements on the size and quality of the offline datasets. The recently emerged hybrid offline-and-online RL provides an attractive framework that enables joint use of limited offline data and imperfect simulator for transferable policy learning. In this paper, we develop a new algorithm, called H2O+, which offers great flexibility to bridge various choices of offline and online learning methods, while also accounting for dynamics gaps between the real and simulation environment. Through extensive simulation and real-world robotics experiments, we demonstrate superior performance and flexibility over advanced cross-domain online and offline RL algorithms.