 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarNeXt: Real-Time and Reliable 3D Object Detector Based On 4D mmWave Imaging Radar
Jan 04, 2025



3D object detection is crucial for Autonomous Driving (AD) and Advanced Driver Assistance Systems (ADAS). However, most 3D detectors prioritize detection accuracy, often overlooking network inference speed in practical applications. In this paper, we propose RadarNeXt, a real-time and reliable 3D object detector based on the 4D mmWave radar point clouds. It leverages the re-parameterizable neural networks to catch multi-scale features, reduce memory cost and accelerate the inference. Moreover, to highlight the irregular foreground features of radar point clouds and suppress background clutter, we propose a Multi-path Deformable Foreground Enhancement Network (MDFEN), ensuring detection accuracy while minimizing the sacrifice of speed and excessive number of parameters. Experimental results on View-of-Delft and TJ4DRadSet datasets validate the exceptional performance and efficiency of RadarNeXt, achieving 50.48 and 32.30 mAPs with the variant using our proposed MDFEN. Notably, our RadarNeXt variants achieve inference speeds of over 67.10 FPS on the RTX A4000 GPU and 28.40 FPS on the Jetson AGX Orin. This research demonstrates that RadarNeXt brings a novel and effective paradigm for 3D perception based on 4D mmWave radar.
NanoMVG: USV-Centric Low-Power Multi-Task Visual Grounding based on Prompt-Guided Camera and 4D mmWave Radar
Aug 30, 2024



Recently, visual grounding and multi-sensors setting have been incorporated into perception system for terrestrial autonomous driving systems and Unmanned Surface Vehicles (USVs), yet the high complexity of modern learning-based visual grounding model using multi-sensors prevents such model to be deployed on USVs in the real-life. To this end, we design a low-power multi-task model named NanoMVG for waterway embodied perception, guiding both camera and 4D millimeter-wave radar to locate specific object(s) through natural language. NanoMVG can perform both box-level and mask-level visual grounding tasks simultaneously. Compared to other visual grounding models, NanoMVG achieves highly competitive performance on the WaterVG dataset, particularly in harsh environments and boasts ultra-low power consumption for long endurance.
Talk2Radar: Bridging Natural Language with 4D mmWave Radar for 3D Referring Expression Comprehension
May 21, 2024



Embodied perception is essential for intelligent vehicles and robots, enabling more natural interaction and task execution. However, these advancements currently embrace vision level, rarely focusing on using 3D modeling sensors, which limits the full understanding of surrounding objects with multi-granular characteristics. Recently, as a promising automotive sensor with affordable cost, 4D Millimeter-Wave radar provides denser point clouds than conventional radar and perceives both semantic and physical characteristics of objects, thus enhancing the reliability of perception system. To foster the development of natural language-driven context understanding in radar scenes for 3D grounding, we construct the first dataset, Talk2Radar, which bridges these two modalities for 3D Referring Expression Comprehension. Talk2Radar contains 8,682 referring prompt samples with 20,558 referred objects. Moreover, we propose a novel model, T-RadarNet for 3D REC upon point clouds, achieving state-of-the-art performances on Talk2Radar dataset compared with counterparts, where Deformable-FPN and Gated Graph Fusion are meticulously designed for efficient point cloud feature modeling and cross-modal fusion between radar and text features, respectively. Further, comprehensive experiments are conducted to give a deep insight into radar-based 3D REC. We release our project at https://github.com/GuanRunwei/Talk2Radar.
Referring Flexible Image Restoration
Apr 16, 2024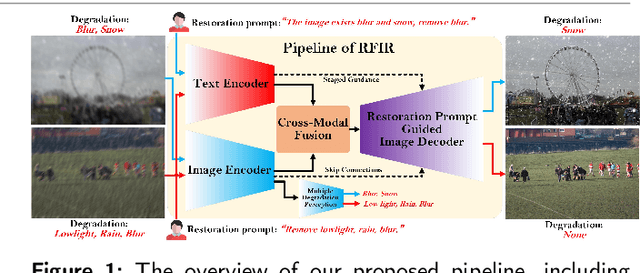


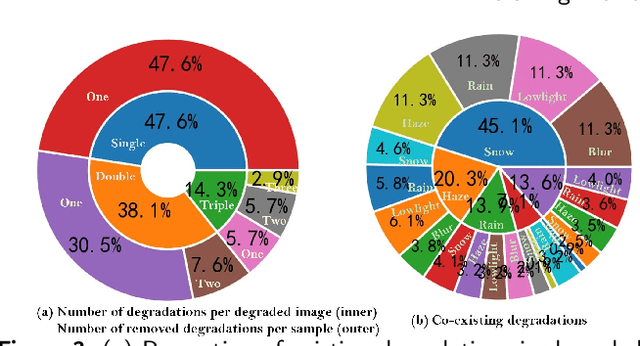
In reality, images often exhibit multiple degradations, such as rain and fog at night (triple degradations). However, in many cases, individuals may not want to remove all degradations, for instance, a blurry lens revealing a beautiful snowy landscape (double degradations). In such scenarios, people may only desire to deblur. These situations and requirements shed light on a new challenge in image restoration, where a model must perceive and remove specific degradation types specified by human commands in images with multiple degradations. We term this task Referring Flexible Image Restoration (RFIR). To address this, we first construct a large-scale synthetic dataset called RFIR, comprising 153,423 samples with the degraded image, text prompt for specific degradation removal and restored image. RFIR consists of five basic degradation types: blur, rain, haze, low light and snow while six main sub-categories are included for varying degrees of degradation removal. To tackle the challenge, we propose a novel transformer-based multi-task model named TransRFIR, which simultaneously perceives degradation types in the degraded image and removes specific degradation upon text prompt. TransRFIR is based on two devised attention modules, Multi-Head Agent Self-Attention (MHASA) and Multi-Head Agent Cross Attention (MHACA), where MHASA and MHACA introduce the agent token and reach the linear complexity, achieving lower computation cost than vanilla self-attention and cross-attention and obtaining competitive performances. Our TransRFIR achieves state-of-the-art performances compared with other counterparts and is proven as an effective architecture for image restoration. We release our project at https://github.com/GuanRunwei/FIR-CP.
WaterVG: Waterway Visual Grounding based on Text-Guided Vision and mmWave Radar
Apr 01, 2024



The perception of waterways based on human intent is significant for autonomous navigation and operations of Unmanned Surface Vehicles (USVs) in water environments. Inspired by visual grounding, we introduce WaterVG, the first visual grounding dataset designed for USV-based waterway perception based on human prompts. WaterVG encompasses prompts describing multiple targets, with annotations at the instance level including bounding boxes and masks. Notably, WaterVG includes 11,568 samples with 34,987 referred targets, whose prompts integrates both visual and radar characteristics. The pattern of text-guided two sensors equips a finer granularity of text prompts with visual and radar features of referred targets. Moreover, we propose a low-power visual grounding model, Potamoi, which is a multi-task model with a well-designed Phased Heterogeneous Modality Fusion (PHMF) mode, including Adaptive Radar Weighting (ARW) and Multi-Head Slim Cross Attention (MHSCA). Exactly, ARW extracts required radar features to fuse with vision for prompt alignment. MHSCA is an efficient fusion module with a remarkably small parameter count and FLOPs, elegantly fusing scenario context captured by two sensors with linguistic features, which performs expressively on visual grounding tasks. Comprehensive experiments and evaluations have been conducted on WaterVG, where our Potamoi archives state-of-the-art performances compared with counterparts.
Achelous++: Power-Oriented Water-Surface Panoptic Perception Framework on Edge Devices based on Vision-Radar Fusion and Pruning of Heterogeneous Modalities
Dec 14, 2023



Urban water-surface robust perception serves as the foundation for intelligent monitoring of aquatic environments and the autonomous navigation and operation of unmanned vessels, especially in the context of waterway safety. It is worth noting that current multi-sensor fusion and multi-task learning models consume substantial power and heavily rely on high-power GPUs for inference. This contributes to increased carbon emissions, a concern that runs counter to the prevailing emphasis on environmental preservation and the pursuit of sustainable, low-carbon urban environments. In light of these concerns, this paper concentrates on low-power, lightweight, multi-task panoptic perception through the fusion of visual and 4D radar data, which is seen as a promising low-cost perception method. We propose a framework named Achelous++ that facilitates the development and comprehensive evaluation of multi-task water-surface panoptic perception models. Achelous++ can simultaneously execute five perception tasks with high speed and low power consumption, including object detection, object semantic segmentation, drivable-area segmentation, waterline segmentation, and radar point cloud semantic segmentation. Furthermore, to meet the demand for developers to customize models for real-time inference on low-performance devices, a novel multi-modal pruning strategy known as Heterogeneous-Aware SynFlow (HA-SynFlow) is proposed. Besides, Achelous++ also supports random pruning at initialization with different layer-wise sparsity, such as Uniform and Erdos-Renyi-Kernel (ERK). Overall, our Achelous++ framework achieves state-of-the-art performance on the WaterScenes benchmark, excelling in both accuracy and power efficiency compared to other single-task and multi-task models. We release and maintain the code at https://github.com/GuanRunwei/Achelous.
Efficient-VRNet: An Exquisite Fusion Network for Riverway Panoptic Perception based on Asymmetric Fair Fusion of Vision and 4D mmWave Radar
Aug 20, 2023



Panoptic perception is essential to unmanned surface vehicles (USVs) for autonomous navigation. The current panoptic perception scheme is mainly based on vision only, that is, object detection and semantic segmentation are performed simultaneously based on camera sensors. Nevertheless, the fusion of camera and radar sensors is regarded as a promising method which could substitute pure vision methods, but almost all works focus on object detection only. Therefore, how to maximize and subtly fuse the features of vision and radar to improve both detection and segmentation is a challenge. In this paper, we focus on riverway panoptic perception based on USVs, which is a considerably unexplored field compared with road panoptic perception. We propose Efficient-VRNet, a model based on Contextual Clustering (CoC) and the asymmetric fusion of vision and 4D mmWave radar, which treats both vision and radar modalities fairly. Efficient-VRNet can simultaneously perform detection and segmentation of riverway objects and drivable area segmentation. Furthermore, we adopt an uncertainty-based panoptic perception training strategy to train Efficient-VRNet. In the experiments, our Efficient-VRNet achieves better performances on our collected dataset than other uni-modal models, especially in adverse weather and environment with poor lighting conditions. Our code and models are available at \url{https://github.com/GuanRunwei/Efficient-VRNet}.
Radar-STDA: A High-Performance Spatial-Temporal Denoising Autoencoder for Interference Mitigation of FMCW Radars
Jul 18, 2023



With its small size, low cost and all-weather operation, millimeter-wave radar can accurately measure the distance, azimuth and radial velocity of a target compared to other traffic sensors. However, in practice, millimeter-wave radars are plagued by various interferences, leading to a drop in target detection accuracy or even failure to detect targets. This is undesirable in autonomous vehicles and traffic surveillance, as it is likely to threaten human life and cause property damage. Therefore, interference mitigation is of great significance for millimeter-wave radar-based target detection. Currently, the development of deep learning is rapid, but existing deep learning-based interference mitigation models still have great limitations in terms of model size and inference speed. For these reasons, we propose Radar-STDA, a Radar-Spatial Temporal Denoising Autoencoder. Radar-STDA is an efficient nano-level denoising autoencoder that takes into account both spatial and temporal information of range-Doppler maps. Among other methods, it achieves a maximum SINR of 17.08 dB with only 140,000 parameters. It obtains 207.6 FPS on an RTX A4000 GPU and 56.8 FPS on an NVIDIA Jetson AGXXavier respectively when denoising range-Doppler maps for three consecutive frames. Moreover, we release a synthetic data set called Ra-inf for the task, which involves 384,769 range-Doppler maps with various clutters from objects of no interest and receiver noise in realistic scenarios. To the best of our knowledge, Ra-inf is the first synthetic dataset of radar interference. To support the community, our research is open-source via the link \url{https://github.com/GuanRunwei/rd_map_temporal_spatial_denoising_autoencoder}.
Achelous: A Fast Unified Water-surface Panoptic Perception Framework based on Fusion of Monocular Camera and 4D mmWave Radar
Jul 14, 2023Current perception models for different tasks usually exist in modular forms on Unmanned Surface Vehicles (USVs), which infer extremely slowly in parallel on edge devices, causing the asynchrony between perception results and USV position, and leading to error decisions of autonomous navigation. Compared with Unmanned Ground Vehicles (UGVs), the robust perception of USVs develops relatively slowly. Moreover, most current multi-task perception models are huge in parameters, slow in inference and not scalable. Oriented on this, we propose Achelous, a low-cost and fast unified panoptic perception framework for water-surface perception based on the fusion of a monocular camera and 4D mmWave radar. Achelous can simultaneously perform five tasks, detection and segmentation of visual targets, drivable-area segmentation, waterline segmentation and radar point cloud segmentation. Besides, models in Achelous family, with less than around 5 million parameters, achieve about 18 FPS on an NVIDIA Jetson AGX Xavier, 11 FPS faster than HybridNets, and exceed YOLOX-Tiny and Segformer-B0 on our collected dataset about 5 mAP$_{\text{50-95}}$ and 0.7 mIoU, especially under situations of adverse weather, dark environments and camera failure. To our knowledge, Achelous is the first comprehensive panoptic perception framework combining vision-level and point-cloud-level tasks for water-surface perception. To promote the development of the intelligent transportation community, we release our codes in \url{https://github.com/GuanRunwei/Achelous}.
FindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Apr 21, 2023
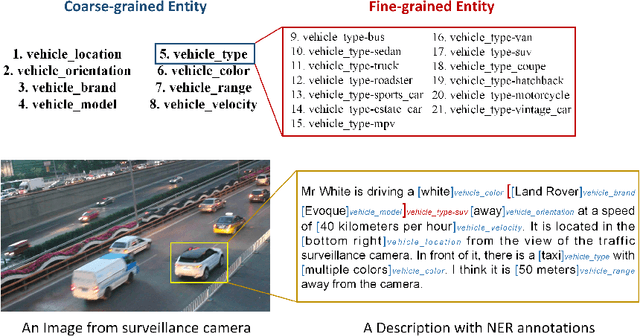
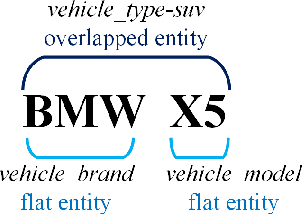
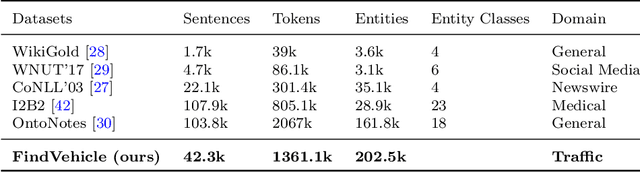
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.