 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Paper and Code

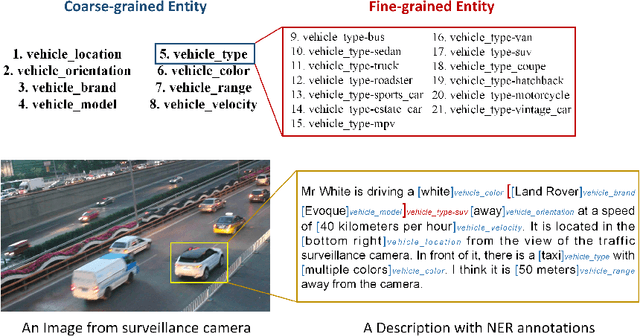
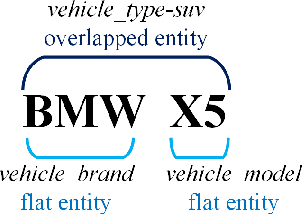
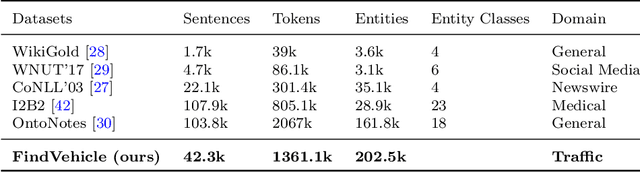
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.