 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyMam: A Mamba-Based Generator for Artistic Style Transfer
Jan 19, 2026Image style transfer aims to integrate the visual patterns of a specific artistic style into a content image while preserving its content structure. Existing methods mainly rely on the generative adversarial network (GAN) or stable diffusion (SD). GAN-based approaches using CNNs or Transformers struggle to jointly capture local and global dependencies, leading to artifacts and disharmonious patterns. SD-based methods reduce such issues but often fail to preserve content structures and suffer from slow inference. To address these issues, we revisit GAN and propose a mamba-based generator, termed as StyMam, to produce high-quality stylized images without introducing artifacts and disharmonious patterns. Specifically, we introduce a mamba-based generator with a residual dual-path strip scanning mechanism and a channel-reweighted spatial attention module. The former efficiently captures local texture features, while the latter models global dependencies. Finally, extensive qualitative and quantitative experiments demonstrate that the proposed method outperforms state-of-the-art algorithms in both quality and speed.
Referring Flexible Image Restoration
Apr 16, 2024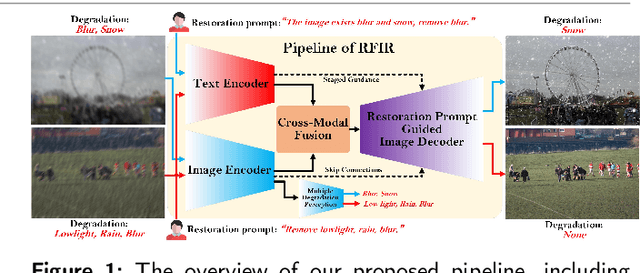


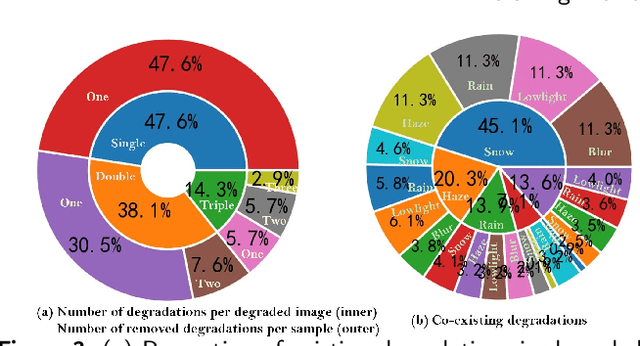
In reality, images often exhibit multiple degradations, such as rain and fog at night (triple degradations). However, in many cases, individuals may not want to remove all degradations, for instance, a blurry lens revealing a beautiful snowy landscape (double degradations). In such scenarios, people may only desire to deblur. These situations and requirements shed light on a new challenge in image restoration, where a model must perceive and remove specific degradation types specified by human commands in images with multiple degradations. We term this task Referring Flexible Image Restoration (RFIR). To address this, we first construct a large-scale synthetic dataset called RFIR, comprising 153,423 samples with the degraded image, text prompt for specific degradation removal and restored image. RFIR consists of five basic degradation types: blur, rain, haze, low light and snow while six main sub-categories are included for varying degrees of degradation removal. To tackle the challenge, we propose a novel transformer-based multi-task model named TransRFIR, which simultaneously perceives degradation types in the degraded image and removes specific degradation upon text prompt. TransRFIR is based on two devised attention modules, Multi-Head Agent Self-Attention (MHASA) and Multi-Head Agent Cross Attention (MHACA), where MHASA and MHACA introduce the agent token and reach the linear complexity, achieving lower computation cost than vanilla self-attention and cross-attention and obtaining competitive performances. Our TransRFIR achieves state-of-the-art performances compared with other counterparts and is proven as an effective architecture for image restoration. We release our project at https://github.com/GuanRunwei/FIR-CP.
FindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Apr 21, 2023
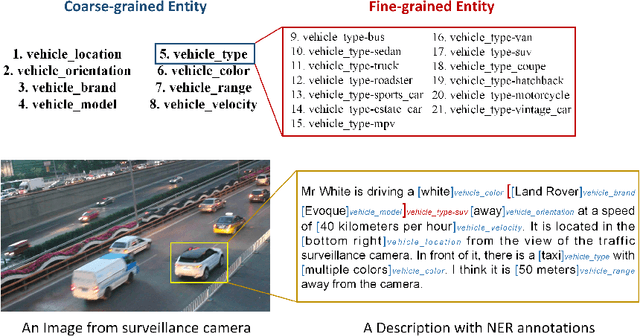
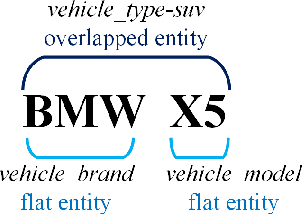
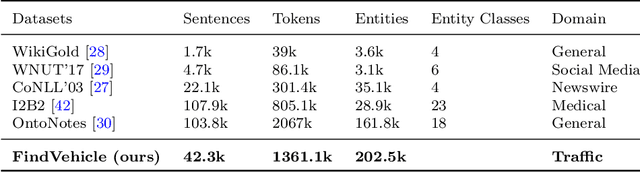
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.