 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar-STDA: A High-Performance Spatial-Temporal Denoising Autoencoder for Interference Mitigation of FMCW Radars
Jul 18, 2023



With its small size, low cost and all-weather operation, millimeter-wave radar can accurately measure the distance, azimuth and radial velocity of a target compared to other traffic sensors. However, in practice, millimeter-wave radars are plagued by various interferences, leading to a drop in target detection accuracy or even failure to detect targets. This is undesirable in autonomous vehicles and traffic surveillance, as it is likely to threaten human life and cause property damage. Therefore, interference mitigation is of great significance for millimeter-wave radar-based target detection. Currently, the development of deep learning is rapid, but existing deep learning-based interference mitigation models still have great limitations in terms of model size and inference speed. For these reasons, we propose Radar-STDA, a Radar-Spatial Temporal Denoising Autoencoder. Radar-STDA is an efficient nano-level denoising autoencoder that takes into account both spatial and temporal information of range-Doppler maps. Among other methods, it achieves a maximum SINR of 17.08 dB with only 140,000 parameters. It obtains 207.6 FPS on an RTX A4000 GPU and 56.8 FPS on an NVIDIA Jetson AGXXavier respectively when denoising range-Doppler maps for three consecutive frames. Moreover, we release a synthetic data set called Ra-inf for the task, which involves 384,769 range-Doppler maps with various clutters from objects of no interest and receiver noise in realistic scenarios. To the best of our knowledge, Ra-inf is the first synthetic dataset of radar interference. To support the community, our research is open-source via the link \url{https://github.com/GuanRunwei/rd_map_temporal_spatial_denoising_autoencoder}.
EVOQUER: Enhancing Temporal Grounding with Video-Pivoted BackQuery Generation
Sep 10, 2021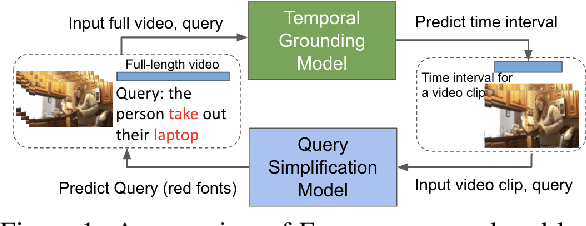
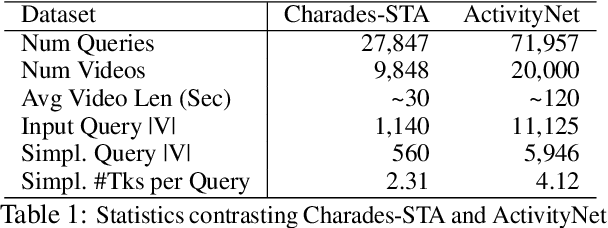
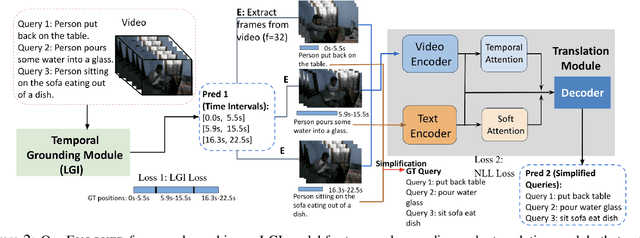
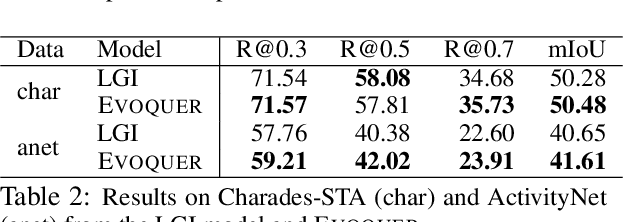
Temporal grounding aims to predict a time interval of a video clip corresponding to a natural language query input. In this work, we present EVOQUER, a temporal grounding framework incorporating an existing text-to-video grounding model and a video-assisted query generation network. Given a query and an untrimmed video, the temporal grounding model predicts the target interval, and the predicted video clip is fed into a video translation task by generating a simplified version of the input query. EVOQUER forms closed-loop learning by incorporating loss functions from both temporal grounding and query generation serving as feedback. Our experiments on two widely used datasets, Charades-STA and ActivityNet, show that EVOQUER achieves promising improvements by 1.05 and 1.31 at R@0.7. We also discuss how the query generation task could facilitate error analysis by explaining temporal grounding model behavior.