 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
Jan 14, 2026Deep research systems are widely used for multi-step web research, analysis, and cross-source synthesis, yet their evaluation remains challenging. Existing benchmarks often require annotation-intensive task construction, rely on static evaluation dimensions, or fail to reliably verify facts when citations are missing. To bridge these gaps, we introduce DeepResearchEval, an automated framework for deep research task construction and agentic evaluation. For task construction, we propose a persona-driven pipeline generating realistic, complex research tasks anchored in diverse user profiles, applying a two-stage filter Task Qualification and Search Necessity to retain only tasks requiring multi-source evidence integration and external retrieval. For evaluation, we propose an agentic pipeline with two components: an Adaptive Point-wise Quality Evaluation that dynamically derives task-specific evaluation dimensions, criteria, and weights conditioned on each generated task, and an Active Fact-Checking that autonomously extracts and verifies report statements via web search, even when citations are missing.
A Rigorous Benchmark with Multidimensional Evaluation for Deep Research Agents: From Answers to Reports
Oct 02, 2025Artificial intelligence is undergoing the paradigm shift from closed language models to interconnected agent systems capable of external perception and information integration. As a representative embodiment, Deep Research Agents (DRAs) systematically exhibit the capabilities for task decomposition, cross-source retrieval, multi-stage reasoning, and structured output, which markedly enhance performance on complex and open-ended tasks. However, existing benchmarks remain deficient in evaluation dimensions, response formatting, and scoring mechanisms, limiting their capacity to assess such systems effectively. This paper introduces a rigorous benchmark and a multidimensional evaluation framework tailored to DRAs and report-style responses. The benchmark comprises 214 expert-curated challenging queries distributed across 10 broad thematic domains, each accompanied by manually constructed reference bundles to support composite evaluation. The framework enables comprehensive evaluation of long-form reports generated by DRAs, incorporating integrated scoring metrics for semantic quality, topical focus, and retrieval trustworthiness. Extensive experimentation confirms the superior performance of mainstream DRAs over web-search-tool-augmented reasoning models, yet reveals considerable scope for further improvement. This study provides a robust foundation for capability assessment, architectural refinement, and paradigm advancement in DRA systems.
PrismLayers: Open Data for High-Quality Multi-Layer Transparent Image Generative Models
May 28, 2025Generating high-quality, multi-layer transparent images from text prompts can unlock a new level of creative control, allowing users to edit each layer as effortlessly as editing text outputs from LLMs. However, the development of multi-layer generative models lags behind that of conventional text-to-image models due to the absence of a large, high-quality corpus of multi-layer transparent data. In this paper, we address this fundamental challenge by: (i) releasing the first open, ultra-high-fidelity PrismLayers (PrismLayersPro) dataset of 200K (20K) multilayer transparent images with accurate alpha mattes, (ii) introducing a trainingfree synthesis pipeline that generates such data on demand using off-the-shelf diffusion models, and (iii) delivering a strong, open-source multi-layer generation model, ART+, which matches the aesthetics of modern text-to-image generation models. The key technical contributions include: LayerFLUX, which excels at generating high-quality single transparent layers with accurate alpha mattes, and MultiLayerFLUX, which composes multiple LayerFLUX outputs into complete images, guided by human-annotated semantic layout. To ensure higher quality, we apply a rigorous filtering stage to remove artifacts and semantic mismatches, followed by human selection. Fine-tuning the state-of-the-art ART model on our synthetic PrismLayersPro yields ART+, which outperforms the original ART in 60% of head-to-head user study comparisons and even matches the visual quality of images generated by the FLUX.1-[dev] model. We anticipate that our work will establish a solid dataset foundation for the multi-layer transparent image generation task, enabling research and applications that require precise, editable, and visually compelling layered imagery.
BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation
Mar 26, 2025Recently, state-of-the-art text-to-image generation models, such as Flux and Ideogram 2.0, have made significant progress in sentence-level visual text rendering. In this paper, we focus on the more challenging scenarios of article-level visual text rendering and address a novel task of generating high-quality business content, including infographics and slides, based on user provided article-level descriptive prompts and ultra-dense layouts. The fundamental challenges are twofold: significantly longer context lengths and the scarcity of high-quality business content data. In contrast to most previous works that focus on a limited number of sub-regions and sentence-level prompts, ensuring precise adherence to ultra-dense layouts with tens or even hundreds of sub-regions in business content is far more challenging. We make two key technical contributions: (i) the construction of scalable, high-quality business content dataset, i.e., Infographics-650K, equipped with ultra-dense layouts and prompts by implementing a layer-wise retrieval-augmented infographic generation scheme; and (ii) a layout-guided cross attention scheme, which injects tens of region-wise prompts into a set of cropped region latent space according to the ultra-dense layouts, and refine each sub-regions flexibly during inference using a layout conditional CFG. We demonstrate the strong results of our system compared to previous SOTA systems such as Flux and SD3 on our BizEval prompt set. Additionally, we conduct thorough ablation experiments to verify the effectiveness of each component. We hope our constructed Infographics-650K and BizEval can encourage the broader community to advance the progress of business content generation.
RMDM: Radio Map Diffusion Model with Physics Informed
Jan 31, 2025



With the rapid development of wireless communication technology, the efficient utilization of spectrum resources, optimization of communication quality, and intelligent communication have become critical. Radio map reconstruction is essential for enabling advanced applications, yet challenges such as complex signal propagation and sparse data hinder accurate reconstruction. To address these issues, we propose the **Radio Map Diffusion Model (RMDM)**, a physics-informed framework that integrates **Physics-Informed Neural Networks (PINNs)** to incorporate constraints like the **Helmholtz equation**. RMDM employs a dual U-Net architecture: the first ensures physical consistency by minimizing PDE residuals, boundary conditions, and source constraints, while the second refines predictions via diffusion-based denoising. By leveraging physical laws, RMDM significantly enhances accuracy, robustness, and generalization. Experiments demonstrate that RMDM outperforms state-of-the-art methods, achieving **NMSE of 0.0031** and **RMSE of 0.0125** under the Static RM (SRM) setting, and **NMSE of 0.0047** and **RMSE of 0.0146** under the Dynamic RM (DRM) setting. These results establish a novel paradigm for integrating physics-informed and data-driven approaches in radio map reconstruction, particularly under sparse data conditions.
Free-T2M: Frequency Enhanced Text-to-Motion Diffusion Model With Consistency Loss
Jan 30, 2025



Rapid progress in text-to-motion generation has been largely driven by diffusion models. However, existing methods focus solely on temporal modeling, thereby overlooking frequency-domain analysis. We identify two key phases in motion denoising: the **semantic planning stage** and the **fine-grained improving stage**. To address these phases effectively, we propose **Fre**quency **e**nhanced **t**ext-**to**-**m**otion diffusion model (**Free-T2M**), incorporating stage-specific consistency losses that enhance the robustness of static features and improve fine-grained accuracy. Extensive experiments demonstrate the effectiveness of our method. Specifically, on StableMoFusion, our method reduces the FID from **0.189** to **0.051**, establishing a new SOTA performance within the diffusion architecture. These findings highlight the importance of incorporating frequency-domain insights into text-to-motion generation for more precise and robust results.
RSC-SNN: Exploring the Trade-off Between Adversarial Robustness and Accuracy in Spiking Neural Networks via Randomized Smoothing Coding
Jul 29, 2024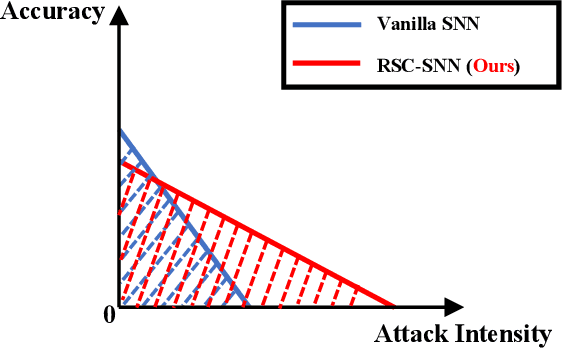



Spiking Neural Networks (SNNs) have received widespread attention due to their unique neuronal dynamics and low-power nature. Previous research empirically shows that SNNs with Poisson coding are more robust than Artificial Neural Networks (ANNs) on small-scale datasets. However, it is still unclear in theory how the adversarial robustness of SNNs is derived, and whether SNNs can still maintain its adversarial robustness advantage on large-scale dataset tasks. This work theoretically demonstrates that SNN's inherent adversarial robustness stems from its Poisson coding. We reveal the conceptual equivalence of Poisson coding and randomized smoothing in defense strategies, and analyze in depth the trade-off between accuracy and adversarial robustness in SNNs via the proposed Randomized Smoothing Coding (RSC) method. Experiments demonstrate that the proposed RSC-SNNs show remarkable adversarial robustness, surpassing ANNs and achieving state-of-the-art robustness results on large-scale dataset ImageNet. Our open-source implementation code is available at this https URL: https://github.com/KemingWu/RSC-SNN.