 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBizGen: Advancing Article-level Visual Text Rendering for Infographics Generation
Mar 26, 2025Recently, state-of-the-art text-to-image generation models, such as Flux and Ideogram 2.0, have made significant progress in sentence-level visual text rendering. In this paper, we focus on the more challenging scenarios of article-level visual text rendering and address a novel task of generating high-quality business content, including infographics and slides, based on user provided article-level descriptive prompts and ultra-dense layouts. The fundamental challenges are twofold: significantly longer context lengths and the scarcity of high-quality business content data. In contrast to most previous works that focus on a limited number of sub-regions and sentence-level prompts, ensuring precise adherence to ultra-dense layouts with tens or even hundreds of sub-regions in business content is far more challenging. We make two key technical contributions: (i) the construction of scalable, high-quality business content dataset, i.e., Infographics-650K, equipped with ultra-dense layouts and prompts by implementing a layer-wise retrieval-augmented infographic generation scheme; and (ii) a layout-guided cross attention scheme, which injects tens of region-wise prompts into a set of cropped region latent space according to the ultra-dense layouts, and refine each sub-regions flexibly during inference using a layout conditional CFG. We demonstrate the strong results of our system compared to previous SOTA systems such as Flux and SD3 on our BizEval prompt set. Additionally, we conduct thorough ablation experiments to verify the effectiveness of each component. We hope our constructed Infographics-650K and BizEval can encourage the broader community to advance the progress of business content generation.
CalliffusionV2: Personalized Natural Calligraphy Generation with Flexible Multi-modal Control
Oct 03, 2024



In this paper, we introduce CalliffusionV2, a novel system designed to produce natural Chinese calligraphy with flexible multi-modal control. Unlike previous approaches that rely solely on image or text inputs and lack fine-grained control, our system leverages both images to guide generations at fine-grained levels and natural language texts to describe the features of generations. CalliffusionV2 excels at creating a broad range of characters and can quickly learn new styles through a few-shot learning approach. It is also capable of generating non-Chinese characters without prior training. Comprehensive tests confirm that our system produces calligraphy that is both stylistically accurate and recognizable by neural network classifiers and human evaluators.
CalliPaint: Chinese Calligraphy Inpainting with Diffusion Model
Dec 03, 2023Chinese calligraphy can be viewed as a unique form of visual art. Recent advancements in computer vision hold significant potential for the future development of generative models in the realm of Chinese calligraphy. Nevertheless, methods of Chinese calligraphy inpainting, which can be effectively used in the art and education fields, remain relatively unexplored. In this paper, we introduce a new model that harnesses recent advancements in both Chinese calligraphy generation and image inpainting. We demonstrate that our proposed model CalliPaint can produce convincing Chinese calligraphy.
Fumbling in Babel: An Investigation into ChatGPT's Language Identification Ability
Nov 16, 2023Recently, ChatGPT has emerged as a powerful NLP tool that can carry out several tasks. However, the range of languages ChatGPT can handle remains largely a mystery. In this work, we investigate ChatGPT's language identification abilities. For this purpose, we compile Babel-670, a benchmark comprising $670$ languages representing $23$ language families. Languages in Babel-670 run the gamut between the very high-resource to the very low-resource and are spoken in five continents. We then study ChatGPT's (both GPT-3.5 and GPT-4) ability to (i) identify both language names and language codes (ii) under both zero- and few-shot conditions (iii) with and without provision of label set. When compared to smaller finetuned language identification tools, we find that ChatGPT lags behind. Our empirical analysis shows the reality that ChatGPT still resides in a state of potential enhancement before it can sufficiently serve diverse communities.
The Skipped Beat: A Study of Sociopragmatic Understanding in LLMs for 64 Languages
Oct 23, 2023Instruction tuned large language models (LLMs), such as ChatGPT, demonstrate remarkable performance in a wide range of tasks. Despite numerous recent studies that examine the performance of instruction-tuned LLMs on various NLP benchmarks, there remains a lack of comprehensive investigation into their ability to understand cross-lingual sociopragmatic meaning (SM), i.e., meaning embedded within social and interactive contexts. This deficiency arises partly from SM not being adequately represented in any of the existing benchmarks. To address this gap, we present SPARROW, an extensive multilingual benchmark specifically designed for SM understanding. SPARROW comprises 169 datasets covering 13 task types across six primary categories (e.g., anti-social language detection, emotion recognition). SPARROW datasets encompass 64 different languages originating from 12 language families representing 16 writing scripts. We evaluate the performance of various multilingual pretrained language models (e.g., mT5) and instruction-tuned LLMs (e.g., BLOOMZ, ChatGPT) on SPARROW through fine-tuning, zero-shot, and/or few-shot learning. Our comprehensive analysis reveals that existing open-source instruction tuned LLMs still struggle to understand SM across various languages, performing close to a random baseline in some cases. We also find that although ChatGPT outperforms many LLMs, it still falls behind task-specific finetuned models with a gap of 12.19 SPARROW score. Our benchmark is available at: https://github.com/UBC-NLP/SPARROW
Calliffusion: Chinese Calligraphy Generation and Style Transfer with Diffusion Modeling
May 30, 2023

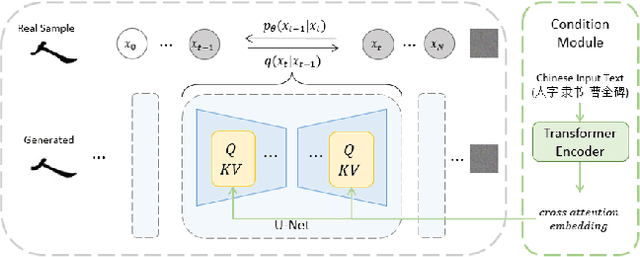

In this paper, we propose Calliffusion, a system for generating high-quality Chinese calligraphy using diffusion models. Our model architecture is based on DDPM (Denoising Diffusion Probabilistic Models), and it is capable of generating common characters in five different scripts and mimicking the styles of famous calligraphers. Experiments demonstrate that our model can generate calligraphy that is difficult to distinguish from real artworks and that our controls for characters, scripts, and styles are effective. Moreover, we demonstrate one-shot transfer learning, using LoRA (Low-Rank Adaptation) to transfer Chinese calligraphy art styles to unseen characters and even out-of-domain symbols such as English letters and digits.
MarsEclipse at SemEval-2023 Task 3: Multi-Lingual and Multi-Label Framing Detection with Contrastive Learning
Apr 20, 2023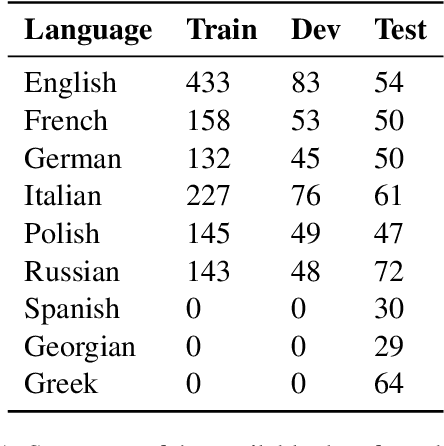



This paper describes our system for SemEval-2023 Task 3 Subtask 2 on Framing Detection. We used a multi-label contrastive loss for fine-tuning large pre-trained language models in a multi-lingual setting, achieving very competitive results: our system was ranked first on the official test set and on the official shared task leaderboard for five of the six languages for which we had training data and for which we could perform fine-tuning. Here, we describe our experimental setup, as well as various ablation studies. The code of our system is available at https://github.com/QishengL/SemEval2023
* framing, contrastive learning, SemEval-2023 task 3