 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling the Essence: Efficient Reasoning Distillation via Sequence Truncation
Dec 24, 2025Distilling the reasoning capabilities from a large language model (LLM) to a smaller student model often involves training on substantial amounts of reasoning data. However, distillation over lengthy sequences with prompt (P), chain-of-thought (CoT), and answer (A) segments makes the process computationally expensive. In this work, we investigate how the allocation of supervision across different segments (P, CoT, A) affects student performance. Our analysis shows that selective knowledge distillation over only the CoT tokens can be effective when the prompt and answer information is encompassed by it. Building on this insight, we establish a truncation protocol to quantify computation-quality tradeoffs as a function of sequence length. We observe that training on only the first $50\%$ of tokens of every training sequence can retain, on average, $\approx94\%$ of full-sequence performance on math benchmarks while reducing training time, memory usage, and FLOPs by about $50\%$ each. These findings suggest that reasoning distillation benefits from prioritizing early reasoning tokens and provides a simple lever for computation-quality tradeoffs. Codes are available at https://github.com/weiruichen01/distilling-the-essence.
Interplay of Machine Translation, Diacritics, and Diacritization
Apr 09, 2024



We investigate two research questions: (1) how do machine translation (MT) and diacritization influence the performance of each other in a multi-task learning setting (2) the effect of keeping (vs. removing) diacritics on MT performance. We examine these two questions in both high-resource (HR) and low-resource (LR) settings across 55 different languages (36 African languages and 19 European languages). For (1), results show that diacritization significantly benefits MT in the LR scenario, doubling or even tripling performance for some languages, but harms MT in the HR scenario. We find that MT harms diacritization in LR but benefits significantly in HR for some languages. For (2), MT performance is similar regardless of diacritics being kept or removed. In addition, we propose two classes of metrics to measure the complexity of a diacritical system, finding these metrics to correlate positively with the performance of our diacritization models. Overall, our work provides insights for developing MT and diacritization systems under different data size conditions and may have implications that generalize beyond the 55 languages we investigate.
Fumbling in Babel: An Investigation into ChatGPT's Language Identification Ability
Nov 16, 2023Recently, ChatGPT has emerged as a powerful NLP tool that can carry out several tasks. However, the range of languages ChatGPT can handle remains largely a mystery. In this work, we investigate ChatGPT's language identification abilities. For this purpose, we compile Babel-670, a benchmark comprising $670$ languages representing $23$ language families. Languages in Babel-670 run the gamut between the very high-resource to the very low-resource and are spoken in five continents. We then study ChatGPT's (both GPT-3.5 and GPT-4) ability to (i) identify both language names and language codes (ii) under both zero- and few-shot conditions (iii) with and without provision of label set. When compared to smaller finetuned language identification tools, we find that ChatGPT lags behind. Our empirical analysis shows the reality that ChatGPT still resides in a state of potential enhancement before it can sufficiently serve diverse communities.
Improving Neural Machine Translation of Indigenous Languages with Multilingual Transfer Learning
May 14, 2022

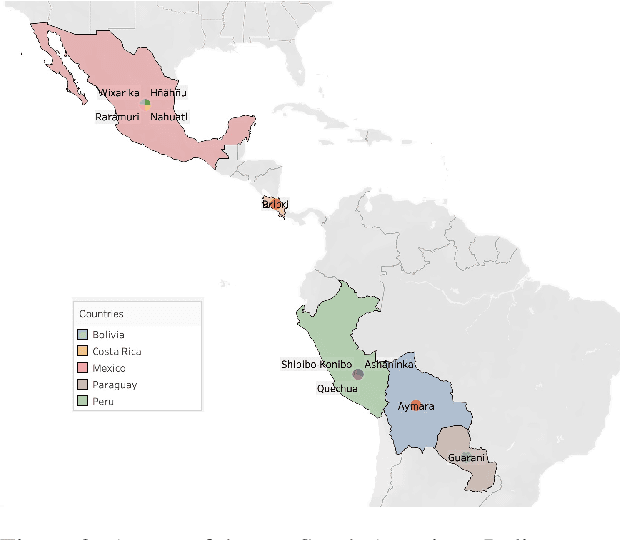

Machine translation (MT) involving Indigenous languages, including those possibly endangered, is challenging due to lack of sufficient parallel data. We describe an approach exploiting bilingual and multilingual pretrained MT models in a transfer learning setting to translate from Spanish to ten South American Indigenous languages. Our models set new SOTA on five out of the ten language pairs we consider, even doubling performance on one of these five pairs. Unlike previous SOTA that perform data augmentation to enlarge the train sets, we retain the low-resource setting to test the effectiveness of our models under such a constraint. In spite of the rarity of linguistic information available about the Indigenous languages, we offer a number of quantitative and qualitative analyses (e.g., as to morphology, tokenization, and orthography) to contextualize our results.
Machine Translation of Low-Resource Indo-European Languages
Aug 08, 2021



Transfer learning has been an important technique for low-resource neural machine translation. In this work, we build two systems to study how relatedness can benefit the translation performance. The primary system adopts machine translation model pre-trained on related language pair and the contrastive system adopts that pre-trained on unrelated language pair. We show that relatedness is not required for transfer learning to work but does benefit the performance.
IndT5: A Text-to-Text Transformer for 10 Indigenous Languages
Apr 27, 2021
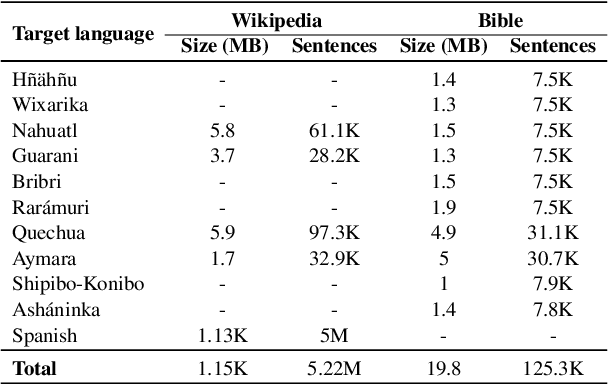

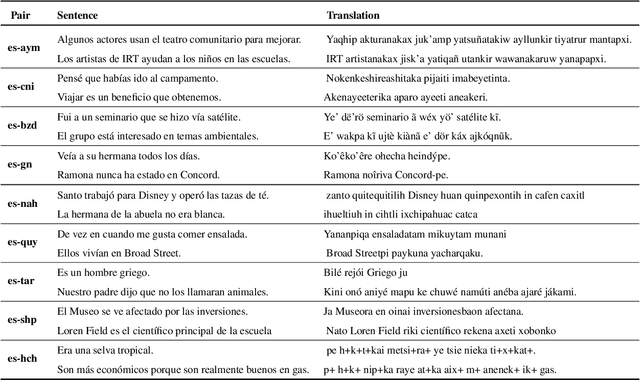
Transformer language models have become fundamental components of natural language processing based pipelines. Although several Transformer models have been introduced to serve many languages, there is a shortage of models pre-trained for low-resource and Indigenous languages. In this work, we introduce IndT5, the first Transformer language model for Indigenous languages. To train IndT5, we build IndCorpus--a new dataset for ten Indigenous languages and Spanish. We also present the application of IndT5 to machine translation by investigating different approaches to translate between Spanish and the Indigenous languages as part of our contribution to the AmericasNLP 2021 Shared Task on Open Machine Translation. IndT5 and IndCorpus are publicly available for research