 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Where Are We? Evaluating LLM Performance on African Languages
Feb 26, 2025Africa's rich linguistic heritage remains underrepresented in NLP, largely due to historical policies that favor foreign languages and create significant data inequities. In this paper, we integrate theoretical insights on Africa's language landscape with an empirical evaluation using Sahara - a comprehensive benchmark curated from large-scale, publicly accessible datasets capturing the continent's linguistic diversity. By systematically assessing the performance of leading large language models (LLMs) on Sahara, we demonstrate how policy-induced data variations directly impact model effectiveness across African languages. Our findings reveal that while a few languages perform reasonably well, many Indigenous languages remain marginalized due to sparse data. Leveraging these insights, we offer actionable recommendations for policy reforms and inclusive data practices. Overall, our work underscores the urgent need for a dual approach - combining theoretical understanding with empirical evaluation - to foster linguistic diversity in AI for African communities.
Toucan: Many-to-Many Translation for 150 African Language Pairs
Jul 05, 2024We address a notable gap in Natural Language Processing (NLP) by introducing a collection of resources designed to improve Machine Translation (MT) for low-resource languages, with a specific focus on African languages. First, We introduce two language models (LMs), Cheetah-1.2B and Cheetah-3.7B, with 1.2 billion and 3.7 billion parameters respectively. Next, we finetune the aforementioned models to create toucan, an Afrocentric machine translation model designed to support 156 African language pairs. To evaluate Toucan, we carefully develop an extensive machine translation benchmark, dubbed AfroLingu-MT, tailored for evaluating machine translation. Toucan significantly outperforms other models, showcasing its remarkable performance on MT for African languages. Finally, we train a new model, spBLEU-1K, to enhance translation evaluation metrics, covering 1K languages, including 614 African languages. This work aims to advance the field of NLP, fostering cross-cultural understanding and knowledge exchange, particularly in regions with limited language resources such as Africa. The GitHub repository for the Toucan project is available at https://github.com/UBC-NLP/Toucan.
Interplay of Machine Translation, Diacritics, and Diacritization
Apr 09, 2024



We investigate two research questions: (1) how do machine translation (MT) and diacritization influence the performance of each other in a multi-task learning setting (2) the effect of keeping (vs. removing) diacritics on MT performance. We examine these two questions in both high-resource (HR) and low-resource (LR) settings across 55 different languages (36 African languages and 19 European languages). For (1), results show that diacritization significantly benefits MT in the LR scenario, doubling or even tripling performance for some languages, but harms MT in the HR scenario. We find that MT harms diacritization in LR but benefits significantly in HR for some languages. For (2), MT performance is similar regardless of diacritics being kept or removed. In addition, we propose two classes of metrics to measure the complexity of a diacritical system, finding these metrics to correlate positively with the performance of our diacritization models. Overall, our work provides insights for developing MT and diacritization systems under different data size conditions and may have implications that generalize beyond the 55 languages we investigate.
Cheetah: Natural Language Generation for 517 African Languages
Jan 10, 2024Low-resource African languages pose unique challenges for natural language processing (NLP) tasks, including natural language generation (NLG). In this paper, we develop Cheetah, a massively multilingual NLG language model for African languages. Cheetah supports 517 African languages and language varieties, allowing us to address the scarcity of NLG resources and provide a solution to foster linguistic diversity. We demonstrate the effectiveness of Cheetah through comprehensive evaluations across six generation downstream tasks. In five of the six tasks, Cheetah significantly outperforms other models, showcasing its remarkable performance for generating coherent and contextually appropriate text in a wide range of African languages. We additionally conduct a detailed human evaluation to delve deeper into the linguistic capabilities of Cheetah. The introduction of Cheetah has far-reaching benefits for linguistic diversity. By leveraging pretrained models and adapting them to specific languages, our approach facilitates the development of practical NLG applications for African communities. The findings of this study contribute to advancing NLP research in low-resource settings, enabling greater accessibility and inclusion for African languages in a rapidly expanding digital landscape. We publicly release our models for research.
Fumbling in Babel: An Investigation into ChatGPT's Language Identification Ability
Nov 16, 2023Recently, ChatGPT has emerged as a powerful NLP tool that can carry out several tasks. However, the range of languages ChatGPT can handle remains largely a mystery. In this work, we investigate ChatGPT's language identification abilities. For this purpose, we compile Babel-670, a benchmark comprising $670$ languages representing $23$ language families. Languages in Babel-670 run the gamut between the very high-resource to the very low-resource and are spoken in five continents. We then study ChatGPT's (both GPT-3.5 and GPT-4) ability to (i) identify both language names and language codes (ii) under both zero- and few-shot conditions (iii) with and without provision of label set. When compared to smaller finetuned language identification tools, we find that ChatGPT lags behind. Our empirical analysis shows the reality that ChatGPT still resides in a state of potential enhancement before it can sufficiently serve diverse communities.
UBC-DLNLP at SemEval-2023 Task 12: Impact of Transfer Learning on African Sentiment Analysis
Apr 25, 2023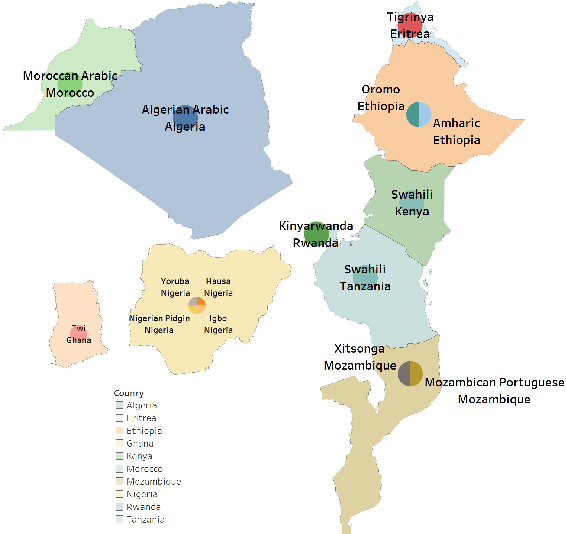
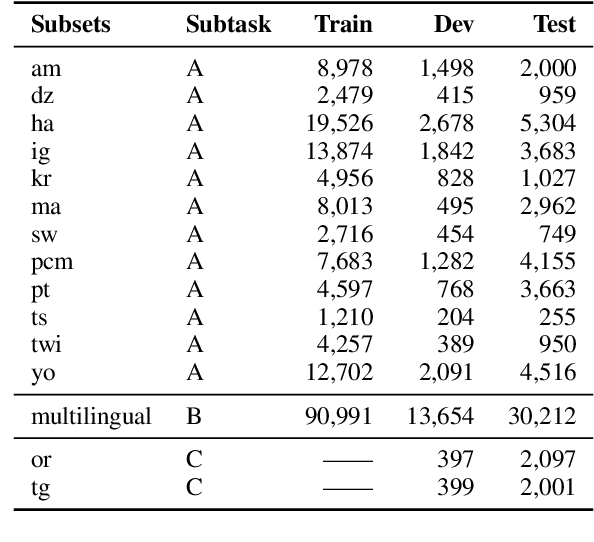
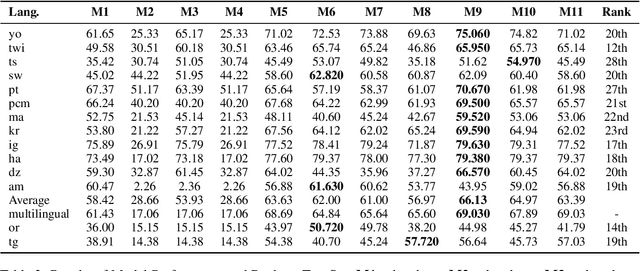
We describe our contribution to the SemEVAl 2023 AfriSenti-SemEval shared task, where we tackle the task of sentiment analysis in 14 different African languages. We develop both monolingual and multilingual models under a full supervised setting (subtasks A and B). We also develop models for the zero-shot setting (subtask C). Our approach involves experimenting with transfer learning using six language models, including further pertaining of some of these models as well as a final finetuning stage. Our best performing models achieve an F1-score of 70.36 on development data and an F1-score of 66.13 on test data. Unsurprisingly, our results demonstrate the effectiveness of transfer learning and fine-tuning techniques for sentiment analysis across multiple languages. Our approach can be applied to other sentiment analysis tasks in different languages and domains.
SERENGETI: Massively Multilingual Language Models for Africa
Dec 21, 2022Multilingual language models (MLMs) acquire valuable, generalizable linguistic information during pretraining and have advanced the state of the art on task-specific finetuning. So far, only ~ 28 out of ~2,000 African languages are covered in existing language models. We ameliorate this limitation by developing SERENGETI, a set of massively multilingual language model that covers 517 African languages and language varieties. We evaluate our novel models on eight natural language understanding tasks across 20 datasets, comparing to four MLMs that each cover any number of African languages. SERENGETI outperforms other models on 11 datasets across the eights tasks and achieves 82.27 average F-1. We also perform error analysis on our models' performance and show the influence of mutual intelligibility when the models are applied under zero-shot settings. We will publicly release our models for research.
Towards Afrocentric NLP for African Languages: Where We Are and Where We Can Go
Mar 17, 2022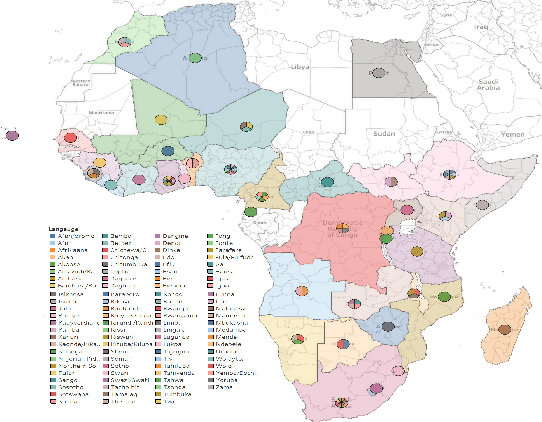
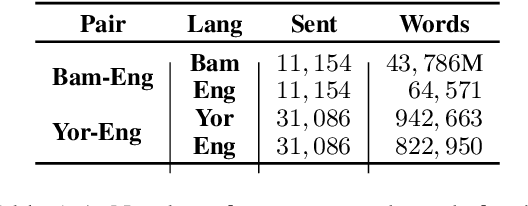
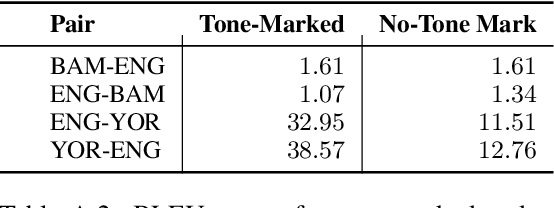
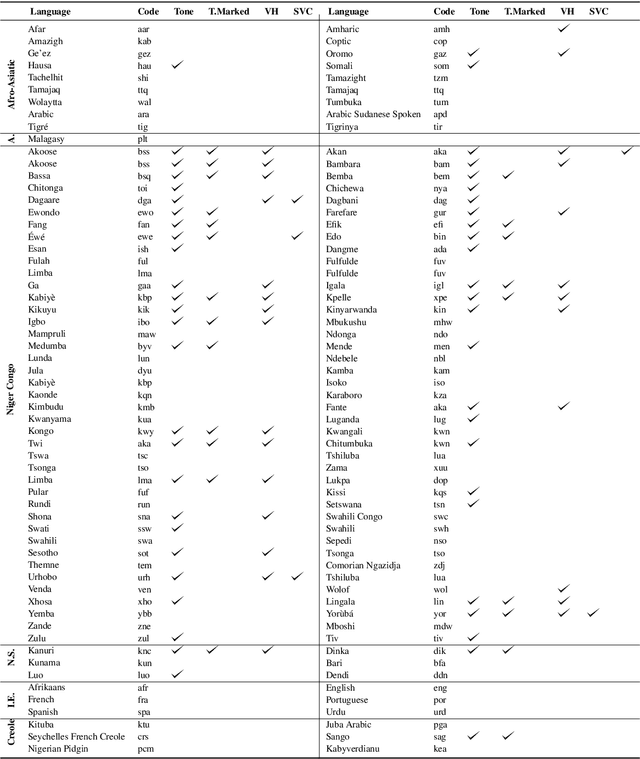
Aligning with ACL 2022 special Theme on "Language Diversity: from Low Resource to Endangered Languages", we discuss the major linguistic and sociopolitical challenges facing development of NLP technologies for African languages. Situating African languages in a typological framework, we discuss how the particulars of these languages can be harnessed. To facilitate future research, we also highlight current efforts, communities, venues, datasets, and tools. Our main objective is to motivate and advocate for an Afrocentric approach to technology development. With this in mind, we recommend \textit{what} technologies to build and \textit{how} to build, evaluate, and deploy them based on the needs of local African communities.
Improving Similar Language Translation With Transfer Learning
Aug 11, 2021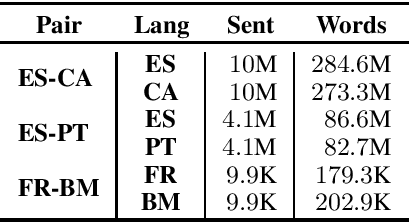

We investigate transfer learning based on pre-trained neural machine translation models to translate between (low-resource) similar languages. This work is part of our contribution to the WMT 2021 Similar Languages Translation Shared Task where we submitted models for different language pairs, including French-Bambara, Spanish-Catalan, and Spanish-Portuguese in both directions. Our models for Catalan-Spanish ($82.79$ BLEU) and Portuguese-Spanish ($87.11$ BLEU) rank top 1 in the official shared task evaluation, and we are the only team to submit models for the French-Bambara pairs.