 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndT5: A Text-to-Text Transformer for 10 Indigenous Languages
Apr 27, 2021
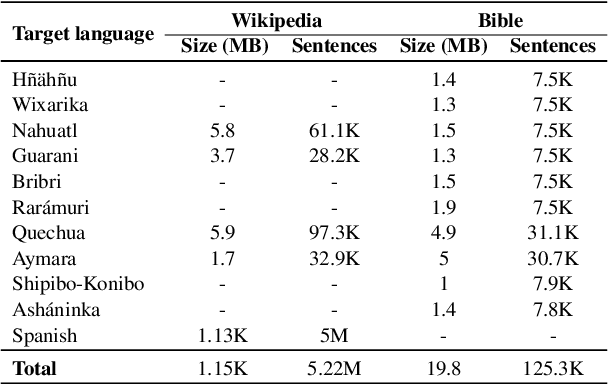

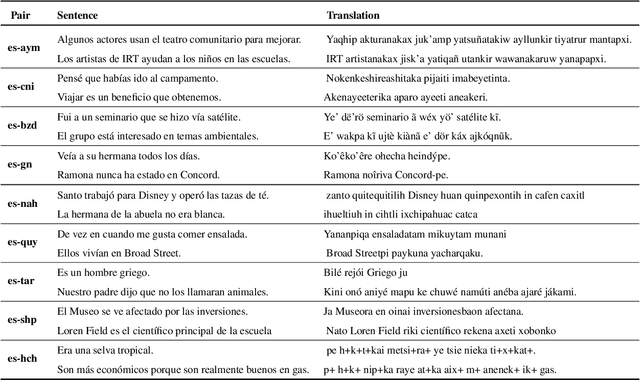
Transformer language models have become fundamental components of natural language processing based pipelines. Although several Transformer models have been introduced to serve many languages, there is a shortage of models pre-trained for low-resource and Indigenous languages. In this work, we introduce IndT5, the first Transformer language model for Indigenous languages. To train IndT5, we build IndCorpus--a new dataset for ten Indigenous languages and Spanish. We also present the application of IndT5 to machine translation by investigating different approaches to translate between Spanish and the Indigenous languages as part of our contribution to the AmericasNLP 2021 Shared Task on Open Machine Translation. IndT5 and IndCorpus are publicly available for research