Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarsEclipse at SemEval-2023 Task 3: Multi-Lingual and Multi-Label Framing Detection with Contrastive Learning
Apr 20, 2023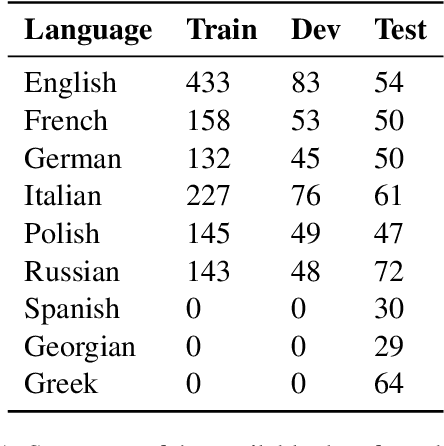



This paper describes our system for SemEval-2023 Task 3 Subtask 2 on Framing Detection. We used a multi-label contrastive loss for fine-tuning large pre-trained language models in a multi-lingual setting, achieving very competitive results: our system was ranked first on the official test set and on the official shared task leaderboard for five of the six languages for which we had training data and for which we could perform fine-tuning. Here, we describe our experimental setup, as well as various ablation studies. The code of our system is available at https://github.com/QishengL/SemEval2023
* SemEval-2023
* framing, contrastive learning, SemEval-2023 task 3
* framing, contrastive learning, SemEval-2023 task 3
Via