 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRWKV: Focusing on Object Edges for Low-Light Image Enhancement
Jul 24, 2025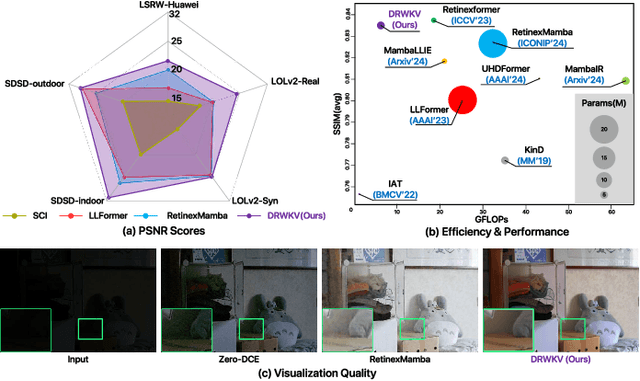
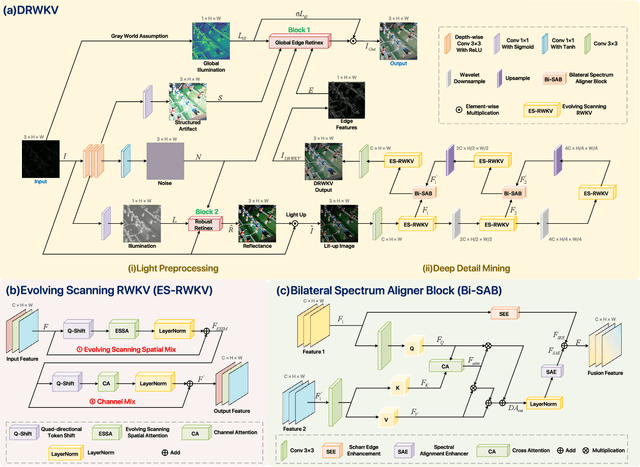


Low-light image enhancement remains a challenging task, particularly in preserving object edge continuity and fine structural details under extreme illumination degradation. In this paper, we propose a novel model, DRWKV (Detailed Receptance Weighted Key Value), which integrates our proposed Global Edge Retinex (GER) theory, enabling effective decoupling of illumination and edge structures for enhanced edge fidelity. Secondly, we introduce Evolving WKV Attention, a spiral-scanning mechanism that captures spatial edge continuity and models irregular structures more effectively. Thirdly, we design the Bilateral Spectrum Aligner (Bi-SAB) and a tailored MS2-Loss to jointly align luminance and chrominance features, improving visual naturalness and mitigating artifacts. Extensive experiments on five LLIE benchmarks demonstrate that DRWKV achieves leading performance in PSNR, SSIM, and NIQE while maintaining low computational complexity. Furthermore, DRWKV enhances downstream performance in low-light multi-object tracking tasks, validating its generalization capabilities.
DialogueAgents: A Hybrid Agent-Based Speech Synthesis Framework for Multi-Party Dialogue
Apr 20, 2025Speech synthesis is crucial for human-computer interaction, enabling natural and intuitive communication. However, existing datasets involve high construction costs due to manual annotation and suffer from limited character diversity, contextual scenarios, and emotional expressiveness. To address these issues, we propose DialogueAgents, a novel hybrid agent-based speech synthesis framework, which integrates three specialized agents -- a script writer, a speech synthesizer, and a dialogue critic -- to collaboratively generate dialogues. Grounded in a diverse character pool, the framework iteratively refines dialogue scripts and synthesizes speech based on speech review, boosting emotional expressiveness and paralinguistic features of the synthesized dialogues. Using DialogueAgent, we contribute MultiTalk, a bilingual, multi-party, multi-turn speech dialogue dataset covering diverse topics. Extensive experiments demonstrate the effectiveness of our framework and the high quality of the MultiTalk dataset. We release the dataset and code https://github.com/uirlx/DialogueAgents to facilitate future research on advanced speech synthesis models and customized data generation.
RMDM: Radio Map Diffusion Model with Physics Informed
Jan 31, 2025



With the rapid development of wireless communication technology, the efficient utilization of spectrum resources, optimization of communication quality, and intelligent communication have become critical. Radio map reconstruction is essential for enabling advanced applications, yet challenges such as complex signal propagation and sparse data hinder accurate reconstruction. To address these issues, we propose the **Radio Map Diffusion Model (RMDM)**, a physics-informed framework that integrates **Physics-Informed Neural Networks (PINNs)** to incorporate constraints like the **Helmholtz equation**. RMDM employs a dual U-Net architecture: the first ensures physical consistency by minimizing PDE residuals, boundary conditions, and source constraints, while the second refines predictions via diffusion-based denoising. By leveraging physical laws, RMDM significantly enhances accuracy, robustness, and generalization. Experiments demonstrate that RMDM outperforms state-of-the-art methods, achieving **NMSE of 0.0031** and **RMSE of 0.0125** under the Static RM (SRM) setting, and **NMSE of 0.0047** and **RMSE of 0.0146** under the Dynamic RM (DRM) setting. These results establish a novel paradigm for integrating physics-informed and data-driven approaches in radio map reconstruction, particularly under sparse data conditions.
Free-T2M: Frequency Enhanced Text-to-Motion Diffusion Model With Consistency Loss
Jan 30, 2025



Rapid progress in text-to-motion generation has been largely driven by diffusion models. However, existing methods focus solely on temporal modeling, thereby overlooking frequency-domain analysis. We identify two key phases in motion denoising: the **semantic planning stage** and the **fine-grained improving stage**. To address these phases effectively, we propose **Fre**quency **e**nhanced **t**ext-**to**-**m**otion diffusion model (**Free-T2M**), incorporating stage-specific consistency losses that enhance the robustness of static features and improve fine-grained accuracy. Extensive experiments demonstrate the effectiveness of our method. Specifically, on StableMoFusion, our method reduces the FID from **0.189** to **0.051**, establishing a new SOTA performance within the diffusion architecture. These findings highlight the importance of incorporating frequency-domain insights into text-to-motion generation for more precise and robust results.
Towards Multi-dimensional Explanation Alignment for Medical Classification
Oct 28, 2024



The lack of interpretability in the field of medical image analysis has significant ethical and legal implications. Existing interpretable methods in this domain encounter several challenges, including dependency on specific models, difficulties in understanding and visualization, as well as issues related to efficiency. To address these limitations, we propose a novel framework called Med-MICN (Medical Multi-dimensional Interpretable Concept Network). Med-MICN provides interpretability alignment for various angles, including neural symbolic reasoning, concept semantics, and saliency maps, which are superior to current interpretable methods. Its advantages include high prediction accuracy, interpretability across multiple dimensions, and automation through an end-to-end concept labeling process that reduces the need for extensive human training effort when working with new datasets. To demonstrate the effectiveness and interpretability of Med-MICN, we apply it to four benchmark datasets and compare it with baselines. The results clearly demonstrate the superior performance and interpretability of our Med-MICN.
DRIVE: Dependable Robust Interpretable Visionary Ensemble Framework in Autonomous Driving
Sep 16, 2024



Recent advancements in autonomous driving have seen a paradigm shift towards end-to-end learning paradigms, which map sensory inputs directly to driving actions, thereby enhancing the robustness and adaptability of autonomous vehicles. However, these models often sacrifice interpretability, posing significant challenges to trust, safety, and regulatory compliance. To address these issues, we introduce DRIVE -- Dependable Robust Interpretable Visionary Ensemble Framework in Autonomous Driving, a comprehensive framework designed to improve the dependability and stability of explanations in end-to-end unsupervised autonomous driving models. Our work specifically targets the inherent instability problems observed in the Driving through the Concept Gridlock (DCG) model, which undermine the trustworthiness of its explanations and decision-making processes. We define four key attributes of DRIVE: consistent interpretability, stable interpretability, consistent output, and stable output. These attributes collectively ensure that explanations remain reliable and robust across different scenarios and perturbations. Through extensive empirical evaluations, we demonstrate the effectiveness of our framework in enhancing the stability and dependability of explanations, thereby addressing the limitations of current models. Our contributions include an in-depth analysis of the dependability issues within the DCG model, a rigorous definition of DRIVE with its fundamental properties, a framework to implement DRIVE, and novel metrics for evaluating the dependability of concept-based explainable autonomous driving models. These advancements lay the groundwork for the development of more reliable and trusted autonomous driving systems, paving the way for their broader acceptance and deployment in real-world applications.
A Hopfieldian View-based Interpretation for Chain-of-Thought Reasoning
Jun 18, 2024



Chain-of-Thought (CoT) holds a significant place in augmenting the reasoning performance for large language models (LLMs). While some studies focus on improving CoT accuracy through methods like retrieval enhancement, yet a rigorous explanation for why CoT achieves such success remains unclear. In this paper, we analyze CoT methods under two different settings by asking the following questions: (1) For zero-shot CoT, why does prompting the model with "let's think step by step" significantly impact its outputs? (2) For few-shot CoT, why does providing examples before questioning the model could substantially improve its reasoning ability? To answer these questions, we conduct a top-down explainable analysis from the Hopfieldian view and propose a Read-and-Control approach for controlling the accuracy of CoT. Through extensive experiments on seven datasets for three different tasks, we demonstrate that our framework can decipher the inner workings of CoT, provide reasoning error localization, and control to come up with the correct reasoning path.
SATO: Stable Text-to-Motion Framework
May 02, 2024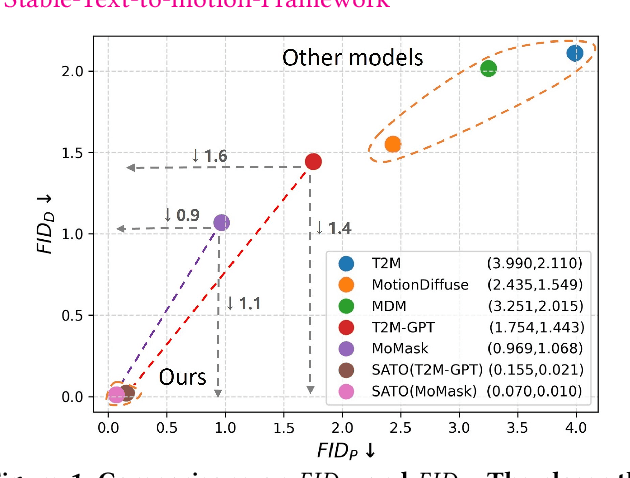

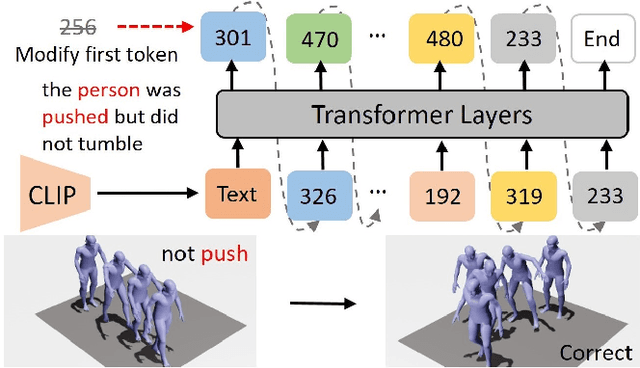
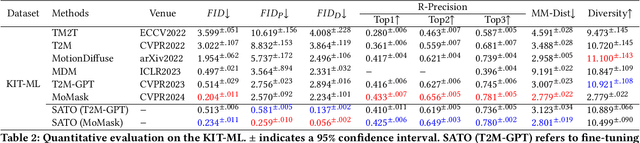
Is the Text to Motion model robust? Recent advancements in Text to Motion models primarily stem from more accurate predictions of specific actions. However, the text modality typically relies solely on pre-trained Contrastive Language-Image Pretraining (CLIP) models. Our research has uncovered a significant issue with the text-to-motion model: its predictions often exhibit inconsistent outputs, resulting in vastly different or even incorrect poses when presented with semantically similar or identical text inputs. In this paper, we undertake an analysis to elucidate the underlying causes of this instability, establishing a clear link between the unpredictability of model outputs and the erratic attention patterns of the text encoder module. Consequently, we introduce a formal framework aimed at addressing this issue, which we term the Stable Text-to-Motion Framework (SATO). SATO consists of three modules, each dedicated to stable attention, stable prediction, and maintaining a balance between accuracy and robustness trade-off. We present a methodology for constructing an SATO that satisfies the stability of attention and prediction. To verify the stability of the model, we introduced a new textual synonym perturbation dataset based on HumanML3D and KIT-ML. Results show that SATO is significantly more stable against synonyms and other slight perturbations while keeping its high accuracy performance.