 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-Hand: Universal Hand Motion Forecasting in Egocentric Views
Nov 18, 2025Forecasting how human hands move in egocentric views is critical for applications like augmented reality and human-robot policy transfer. Recently, several hand trajectory prediction (HTP) methods have been developed to generate future possible hand waypoints, which still suffer from insufficient prediction targets, inherent modality gaps, entangled hand-head motion, and limited validation in downstream tasks. To address these limitations, we present a universal hand motion forecasting framework considering multi-modal input, multi-dimensional and multi-target prediction patterns, and multi-task affordances for downstream applications. We harmonize multiple modalities by vision-language fusion, global context incorporation, and task-aware text embedding injection, to forecast hand waypoints in both 2D and 3D spaces. A novel dual-branch diffusion is proposed to concurrently predict human head and hand movements, capturing their motion synergy in egocentric vision. By introducing target indicators, the prediction model can forecast the specific joint waypoints of the wrist or the fingers, besides the widely studied hand center points. In addition, we enable Uni-Hand to additionally predict hand-object interaction states (contact/separation) to facilitate downstream tasks better. As the first work to incorporate downstream task evaluation in the literature, we build novel benchmarks to assess the real-world applicability of hand motion forecasting algorithms. The experimental results on multiple publicly available datasets and our newly proposed benchmarks demonstrate that Uni-Hand achieves the state-of-the-art performance in multi-dimensional and multi-target hand motion forecasting. Extensive validation in multiple downstream tasks also presents its impressive human-robot policy transfer to enable robotic manipulation, and effective feature enhancement for action anticipation/recognition.
EgoLoc: A Generalizable Solution for Temporal Interaction Localization in Egocentric Videos
Aug 17, 2025Analyzing hand-object interaction in egocentric vision facilitates VR/AR applications and human-robot policy transfer. Existing research has mostly focused on modeling the behavior paradigm of interactive actions (i.e., ``how to interact''). However, the more challenging and fine-grained problem of capturing the critical moments of contact and separation between the hand and the target object (i.e., ``when to interact'') is still underexplored, which is crucial for immersive interactive experiences in mixed reality and robotic motion planning. Therefore, we formulate this problem as temporal interaction localization (TIL). Some recent works extract semantic masks as TIL references, but suffer from inaccurate object grounding and cluttered scenarios. Although current temporal action localization (TAL) methods perform well in detecting verb-noun action segments, they rely on category annotations during training and exhibit limited precision in localizing hand-object contact/separation moments. To address these issues, we propose a novel zero-shot approach dubbed EgoLoc to localize hand-object contact and separation timestamps in egocentric videos. EgoLoc introduces hand-dynamics-guided sampling to generate high-quality visual prompts. It exploits the vision-language model to identify contact/separation attributes, localize specific timestamps, and provide closed-loop feedback for further refinement. EgoLoc eliminates the need for object masks and verb-noun taxonomies, leading to generalizable zero-shot implementation. Comprehensive experiments on the public dataset and our novel benchmarks demonstrate that EgoLoc achieves plausible TIL for egocentric videos. It is also validated to effectively facilitate multiple downstream applications in egocentric vision and robotic manipulation tasks. Code and relevant data will be released at https://github.com/IRMVLab/EgoLoc.
SATO: Stable Text-to-Motion Framework
May 02, 2024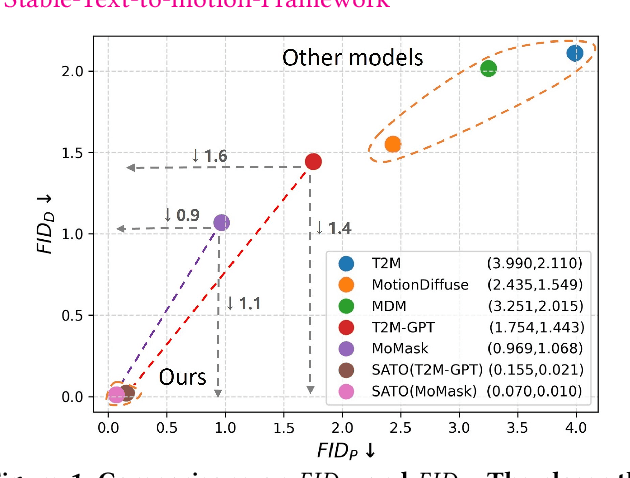

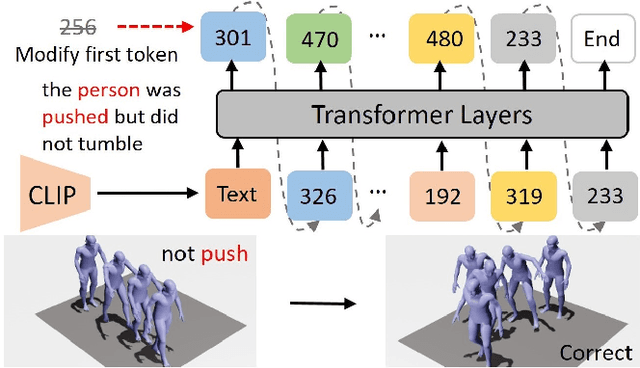
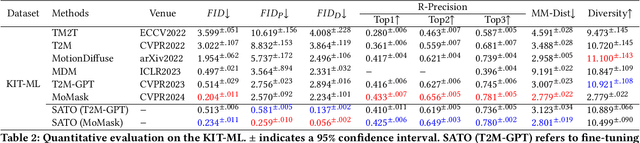
Is the Text to Motion model robust? Recent advancements in Text to Motion models primarily stem from more accurate predictions of specific actions. However, the text modality typically relies solely on pre-trained Contrastive Language-Image Pretraining (CLIP) models. Our research has uncovered a significant issue with the text-to-motion model: its predictions often exhibit inconsistent outputs, resulting in vastly different or even incorrect poses when presented with semantically similar or identical text inputs. In this paper, we undertake an analysis to elucidate the underlying causes of this instability, establishing a clear link between the unpredictability of model outputs and the erratic attention patterns of the text encoder module. Consequently, we introduce a formal framework aimed at addressing this issue, which we term the Stable Text-to-Motion Framework (SATO). SATO consists of three modules, each dedicated to stable attention, stable prediction, and maintaining a balance between accuracy and robustness trade-off. We present a methodology for constructing an SATO that satisfies the stability of attention and prediction. To verify the stability of the model, we introduced a new textual synonym perturbation dataset based on HumanML3D and KIT-ML. Results show that SATO is significantly more stable against synonyms and other slight perturbations while keeping its high accuracy performance.