 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSENSOR: Imitate Third-Person Expert's Behaviors via Active Sensoring
Paper and Code
Apr 04, 2024
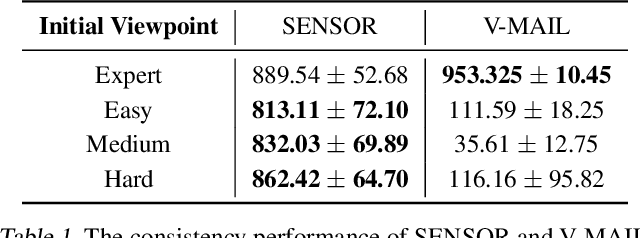


In many real-world visual Imitation Learning (IL) scenarios, there is a misalignment between the agent's and the expert's perspectives, which might lead to the failure of imitation. Previous methods have generally solved this problem by domain alignment, which incurs extra computation and storage costs, and these methods fail to handle the \textit{hard cases} where the viewpoint gap is too large. To alleviate the above problems, we introduce active sensoring in the visual IL setting and propose a model-based SENSory imitatOR (SENSOR) to automatically change the agent's perspective to match the expert's. SENSOR jointly learns a world model to capture the dynamics of latent states, a sensor policy to control the camera, and a motor policy to control the agent. Experiments on visual locomotion tasks show that SENSOR can efficiently simulate the expert's perspective and strategy, and outperforms most baseline methods.