 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing VLAs in Task-Agnostic World Models
May 12, 2026Post-training Vision-Language-Action (VLA) models via reinforcement learning (RL) in learned world models has emerged as an effective strategy to adapt to new tasks without costly real-world interactions. However, while using imagined trajectories reduces the sample complexity of policy training, existing methods still heavily rely on task-specific data to fine-tune both the world and reward models, fundamentally limiting their scalability to unseen tasks. To overcome this, we argue that world and reward models should capture transferable physical priors that enable zero-shot inference. We propose RAW-Dream (Reinforcing VLAs in task-Agnostic World Dreams), a new paradigm that completely disentangles world model learning from downstream task dependencies. RAW-Dream utilizes a world model pre-trained on diverse task-free behaviors for predicting future rollouts, and an off-the-shelf Vision-Language Model (VLM) for reward generation. Because both components are task-agnostic, VLAs can be readily finetuned for any new task entirely within this zero-shot imagination. Furthermore, to mitigate world model hallucinations, we introduce a dual-noise verification mechanism to filter out unreliable rollouts. Extensive experiments across simulation and real-world settings demonstrate consistent performance gains, proving that generalized physical priors can effectively substitute for costly task-dependent data, offering a highly scalable roadmap for VLA adaptation.
Co-Evolving Latent Action World Models
Oct 30, 2025Adapting pre-trained video generation models into controllable world models via latent actions is a promising step towards creating generalist world models. The dominant paradigm adopts a two-stage approach that trains latent action model (LAM) and the world model separately, resulting in redundant training and limiting their potential for co-adaptation. A conceptually simple and appealing idea is to directly replace the forward dynamic model in LAM with a powerful world model and training them jointly, but it is non-trivial and prone to representational collapse. In this work, we propose CoLA-World, which for the first time successfully realizes this synergistic paradigm, resolving the core challenge in joint learning through a critical warm-up phase that effectively aligns the representations of the from-scratch LAM with the pre-trained world model. This unlocks a co-evolution cycle: the world model acts as a knowledgeable tutor, providing gradients to shape a high-quality LAM, while the LAM offers a more precise and adaptable control interface to the world model. Empirically, CoLA-World matches or outperforms prior two-stage methods in both video simulation quality and downstream visual planning, establishing a robust and efficient new paradigm for the field.
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Jul 31, 2025Visual-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent work has begun to explore the incorporation of latent actions, an abstract representation of visual change between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Visual-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. Together, these contributions enable villa-X to achieve superior performance across simulated environments including SIMPLER and LIBERO, as well as on two real-world robot setups including gripper and dexterous hand manipulation. We believe the ViLLA paradigm holds significant promise, and that our villa-X provides a strong foundation for future research.
Reward Models in Deep Reinforcement Learning: A Survey
Jun 18, 2025In reinforcement learning (RL), agents continually interact with the environment and use the feedback to refine their behavior. To guide policy optimization, reward models are introduced as proxies of the desired objectives, such that when the agent maximizes the accumulated reward, it also fulfills the task designer's intentions. Recently, significant attention from both academic and industrial researchers has focused on developing reward models that not only align closely with the true objectives but also facilitate policy optimization. In this survey, we provide a comprehensive review of reward modeling techniques within the deep RL literature. We begin by outlining the background and preliminaries in reward modeling. Next, we present an overview of recent reward modeling approaches, categorizing them based on the source, the mechanism, and the learning paradigm. Building on this understanding, we discuss various applications of these reward modeling techniques and review methods for evaluating reward models. Finally, we conclude by highlighting promising research directions in reward modeling. Altogether, this survey includes both established and emerging methods, filling the vacancy of a systematic review of reward models in current literature.
AD3: Implicit Action is the Key for World Models to Distinguish the Diverse Visual Distractors
Mar 15, 2024Model-based methods have significantly contributed to distinguishing task-irrelevant distractors for visual control. However, prior research has primarily focused on heterogeneous distractors like noisy background videos, leaving homogeneous distractors that closely resemble controllable agents largely unexplored, which poses significant challenges to existing methods. To tackle this problem, we propose Implicit Action Generator (IAG) to learn the implicit actions of visual distractors, and present a new algorithm named implicit Action-informed Diverse visual Distractors Distinguisher (AD3), that leverages the action inferred by IAG to train separated world models. Implicit actions effectively capture the behavior of background distractors, aiding in distinguishing the task-irrelevant components, and the agent can optimize the policy within the task-relevant state space. Our method achieves superior performance on various visual control tasks featuring both heterogeneous and homogeneous distractors. The indispensable role of implicit actions learned by IAG is also empirically validated.
SeMAIL: Eliminating Distractors in Visual Imitation via Separated Models
Jun 19, 2023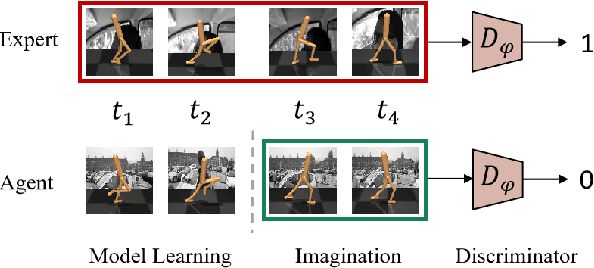



Model-based imitation learning (MBIL) is a popular reinforcement learning method that improves sample efficiency on high-dimension input sources, such as images and videos. Following the convention of MBIL research, existing algorithms are highly deceptive by task-irrelevant information, especially moving distractors in videos. To tackle this problem, we propose a new algorithm - named Separated Model-based Adversarial Imitation Learning (SeMAIL) - decoupling the environment dynamics into two parts by task-relevant dependency, which is determined by agent actions, and training separately. In this way, the agent can imagine its trajectories and imitate the expert behavior efficiently in task-relevant state space. Our method achieves near-expert performance on various visual control tasks with complex observations and the more challenging tasks with different backgrounds from expert observations.