 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Models in Deep Reinforcement Learning: A Survey
Jun 18, 2025In reinforcement learning (RL), agents continually interact with the environment and use the feedback to refine their behavior. To guide policy optimization, reward models are introduced as proxies of the desired objectives, such that when the agent maximizes the accumulated reward, it also fulfills the task designer's intentions. Recently, significant attention from both academic and industrial researchers has focused on developing reward models that not only align closely with the true objectives but also facilitate policy optimization. In this survey, we provide a comprehensive review of reward modeling techniques within the deep RL literature. We begin by outlining the background and preliminaries in reward modeling. Next, we present an overview of recent reward modeling approaches, categorizing them based on the source, the mechanism, and the learning paradigm. Building on this understanding, we discuss various applications of these reward modeling techniques and review methods for evaluating reward models. Finally, we conclude by highlighting promising research directions in reward modeling. Altogether, this survey includes both established and emerging methods, filling the vacancy of a systematic review of reward models in current literature.
Behavior-Regularized Diffusion Policy Optimization for Offline Reinforcement Learning
Feb 07, 2025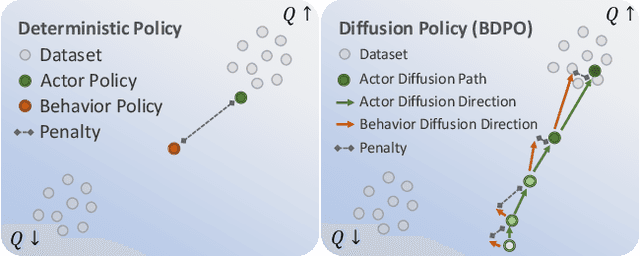
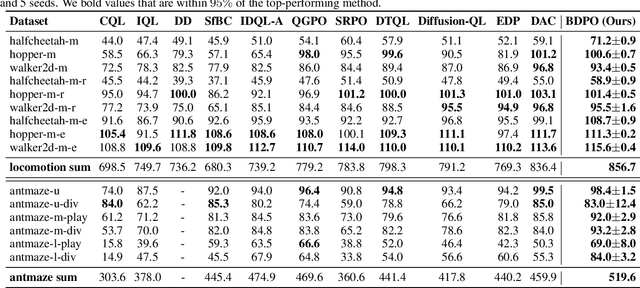
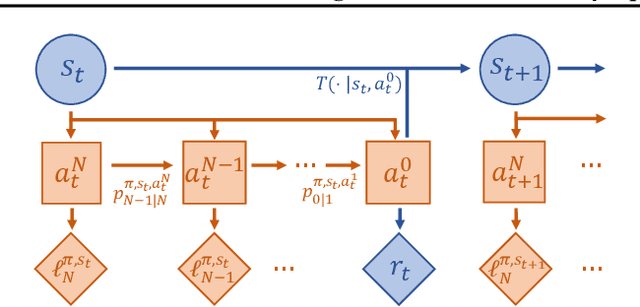
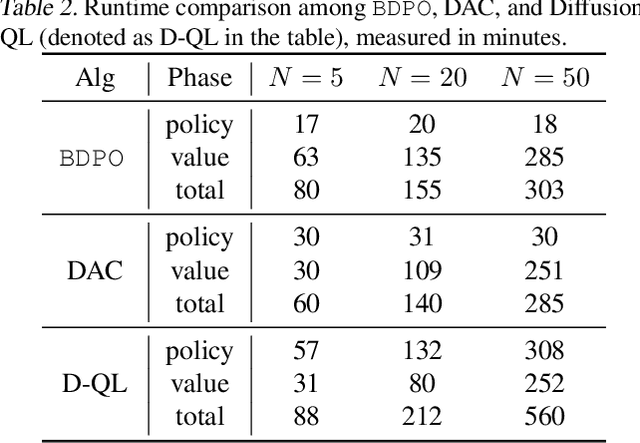
The primary focus of offline reinforcement learning (RL) is to manage the risk of hazardous exploitation of out-of-distribution actions. An effective approach to achieve this goal is through behavior regularization, which augments conventional RL objectives by incorporating constraints that enforce the policy to remain close to the behavior policy. Nevertheless, existing literature on behavior-regularized RL primarily focuses on explicit policy parameterizations, such as Gaussian policies. Consequently, it remains unclear how to extend this framework to more advanced policy parameterizations, such as diffusion models. In this paper, we introduce BDPO, a principled behavior-regularized RL framework tailored for diffusion-based policies, thereby combining the expressive power of diffusion policies and the robustness provided by regularization. The key ingredient of our method is to calculate the Kullback-Leibler (KL) regularization analytically as the accumulated discrepancies in reverse-time transition kernels along the diffusion trajectory. By integrating the regularization, we develop an efficient two-time-scale actor-critic RL algorithm that produces the optimal policy while respecting the behavior constraint. Comprehensive evaluations conducted on synthetic 2D tasks and continuous control tasks from the D4RL benchmark validate its effectiveness and superior performance.
Hindsight Preference Learning for Offline Preference-based Reinforcement Learning
Jul 05, 2024



Offline preference-based reinforcement learning (RL), which focuses on optimizing policies using human preferences between pairs of trajectory segments selected from an offline dataset, has emerged as a practical avenue for RL applications. Existing works rely on extracting step-wise reward signals from trajectory-wise preference annotations, assuming that preferences correlate with the cumulative Markovian rewards. However, such methods fail to capture the holistic perspective of data annotation: Humans often assess the desirability of a sequence of actions by considering the overall outcome rather than the immediate rewards. To address this challenge, we propose to model human preferences using rewards conditioned on future outcomes of the trajectory segments, i.e. the hindsight information. For downstream RL optimization, the reward of each step is calculated by marginalizing over possible future outcomes, the distribution of which is approximated by a variational auto-encoder trained using the offline dataset. Our proposed method, Hindsight Preference Learning (HPL), can facilitate credit assignment by taking full advantage of vast trajectory data available in massive unlabeled datasets. Comprehensive empirical studies demonstrate the benefits of HPL in delivering robust and advantageous rewards across various domains. Our code is publicly released at https://github.com/typoverflow/WiseRL.
Diffusion Spectral Representation for Reinforcement Learning
Jun 23, 2024



Diffusion-based models have achieved notable empirical successes in reinforcement learning (RL) due to their expressiveness in modeling complex distributions. Despite existing methods being promising, the key challenge of extending existing methods for broader real-world applications lies in the computational cost at inference time, i.e., sampling from a diffusion model is considerably slow as it often requires tens to hundreds of iterations to generate even one sample. To circumvent this issue, we propose to leverage the flexibility of diffusion models for RL from a representation learning perspective. In particular, by exploiting the connection between diffusion model and energy-based model, we develop Diffusion Spectral Representation (Diff-SR), a coherent algorithm framework that enables extracting sufficient representations for value functions in Markov decision processes (MDP) and partially observable Markov decision processes (POMDP). We further demonstrate how Diff-SR facilitates efficient policy optimization and practical algorithms while explicitly bypassing the difficulty and inference cost of sampling from the diffusion model. Finally, we provide comprehensive empirical studies to verify the benefits of Diff-SR in delivering robust and advantageous performance across various benchmarks with both fully and partially observable settings.
Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
Mar 12, 2024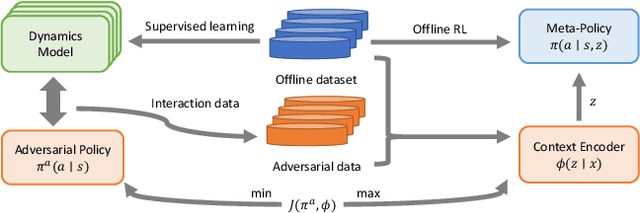
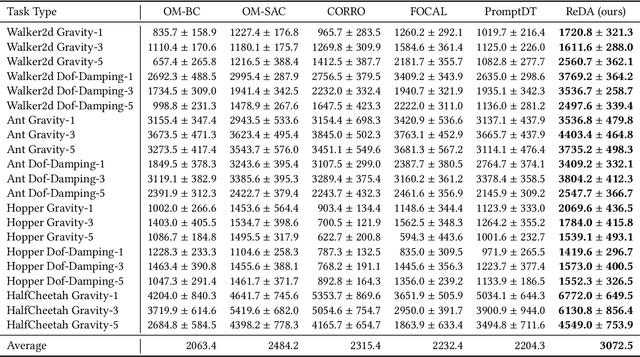
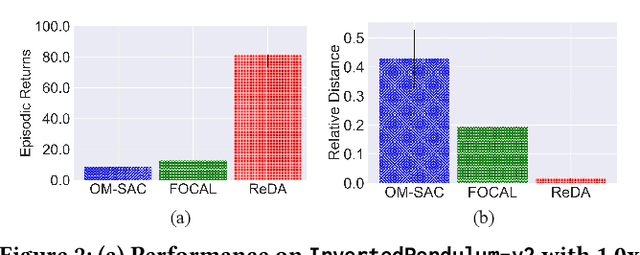
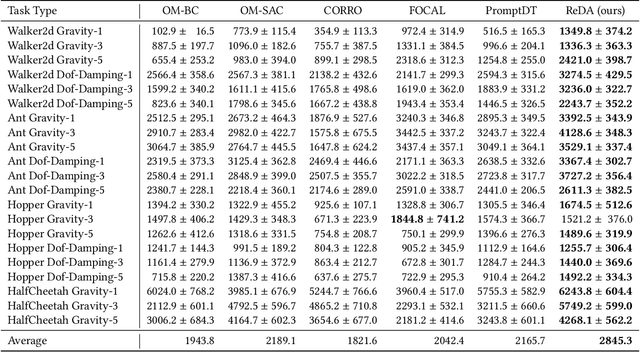
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
Generalizable Task Representation Learning for Offline Meta-Reinforcement Learning with Data Limitations
Dec 26, 2023



Generalization and sample efficiency have been long-standing issues concerning reinforcement learning, and thus the field of Offline Meta-Reinforcement Learning~(OMRL) has gained increasing attention due to its potential of solving a wide range of problems with static and limited offline data. Existing OMRL methods often assume sufficient training tasks and data coverage to apply contrastive learning to extract task representations. However, such assumptions are not applicable in several real-world applications and thus undermine the generalization ability of the representations. In this paper, we consider OMRL with two types of data limitations: limited training tasks and limited behavior diversity and propose a novel algorithm called GENTLE for learning generalizable task representations in the face of data limitations. GENTLE employs Task Auto-Encoder~(TAE), which is an encoder-decoder architecture to extract the characteristics of the tasks. Unlike existing methods, TAE is optimized solely by reconstruction of the state transition and reward, which captures the generative structure of the task models and produces generalizable representations when training tasks are limited. To alleviate the effect of limited behavior diversity, we consistently construct pseudo-transitions to align the data distribution used to train TAE with the data distribution encountered during testing. Empirically, GENTLE significantly outperforms existing OMRL methods on both in-distribution tasks and out-of-distribution tasks across both the given-context protocol and the one-shot protocol.