 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Guided Diffusion Sampling for Offline-to-Online Reinforcement Learning
Jul 17, 2024



Combining offline and online reinforcement learning (RL) techniques is indeed crucial for achieving efficient and safe learning where data acquisition is expensive. Existing methods replay offline data directly in the online phase, resulting in a significant challenge of data distribution shift and subsequently causing inefficiency in online fine-tuning. To address this issue, we introduce an innovative approach, \textbf{E}nergy-guided \textbf{DI}ffusion \textbf{S}ampling (EDIS), which utilizes a diffusion model to extract prior knowledge from the offline dataset and employs energy functions to distill this knowledge for enhanced data generation in the online phase. The theoretical analysis demonstrates that EDIS exhibits reduced suboptimality compared to solely utilizing online data or directly reusing offline data. EDIS is a plug-in approach and can be combined with existing methods in offline-to-online RL setting. By implementing EDIS to off-the-shelf methods Cal-QL and IQL, we observe a notable 20% average improvement in empirical performance on MuJoCo, AntMaze, and Adroit environments. Code is available at \url{https://github.com/liuxhym/EDIS}.
Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
Mar 12, 2024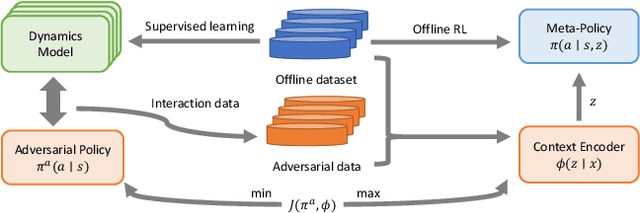
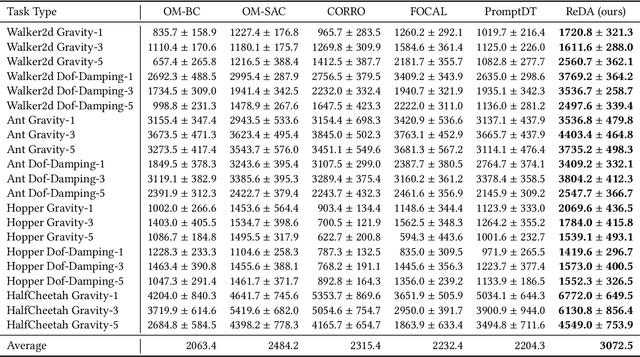
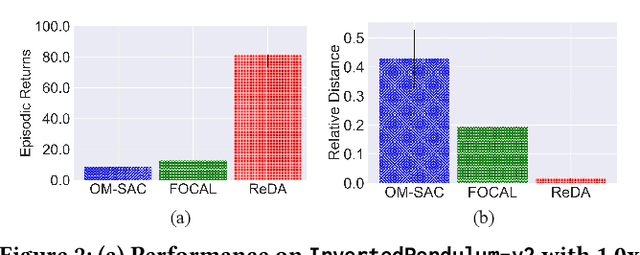
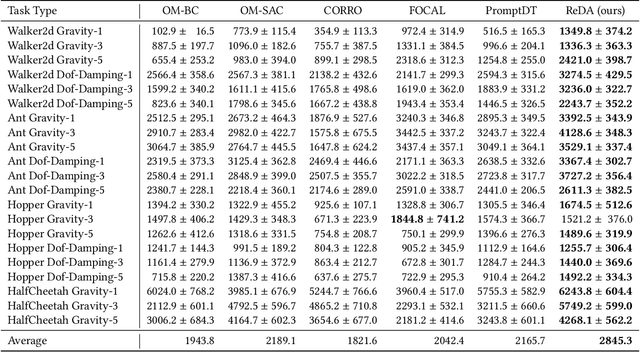
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
How To Guide Your Learner: Imitation Learning with Active Adaptive Expert Involvement
Mar 03, 2023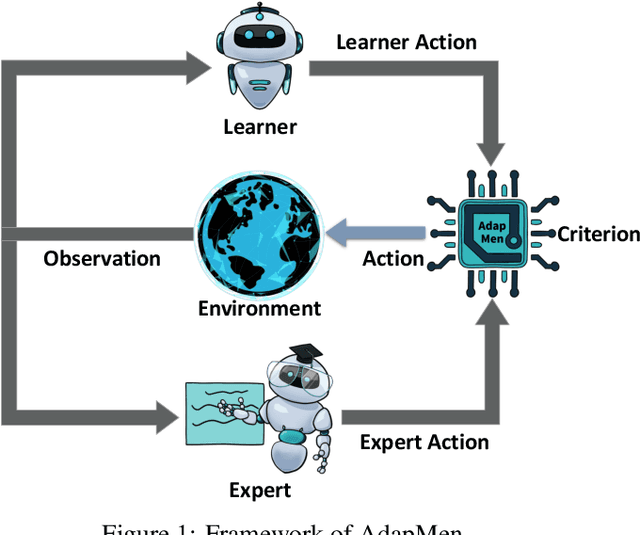

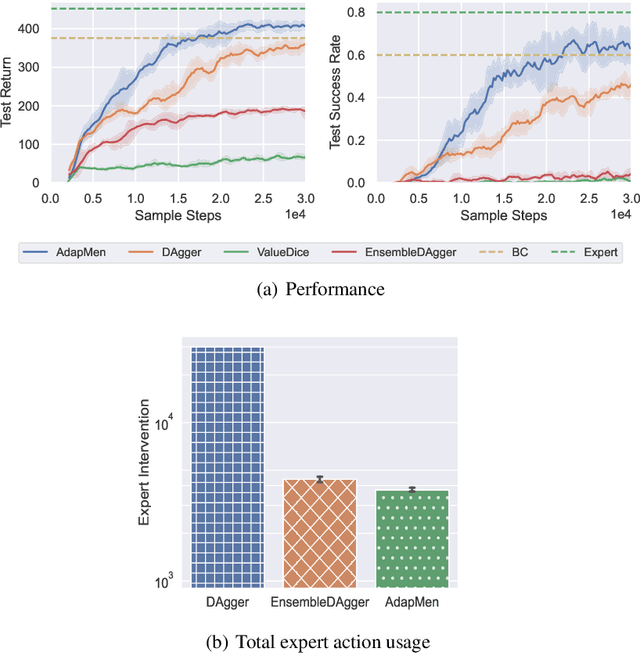

Imitation learning aims to mimic the behavior of experts without explicit reward signals. Passive imitation learning methods which use static expert datasets typically suffer from compounding error, low sample efficiency, and high hyper-parameter sensitivity. In contrast, active imitation learning methods solicit expert interventions to address the limitations. However, recent active imitation learning methods are designed based on human intuitions or empirical experience without theoretical guarantee. In this paper, we propose a novel active imitation learning framework based on a teacher-student interaction model, in which the teacher's goal is to identify the best teaching behavior and actively affect the student's learning process. By solving the optimization objective of this framework, we propose a practical implementation, naming it AdapMen. Theoretical analysis shows that AdapMen can improve the error bound and avoid compounding error under mild conditions. Experiments on the MetaDrive benchmark and Atari 2600 games validate our theoretical analysis and show that our method achieves near-expert performance with much less expert involvement and total sampling steps than previous methods. The code is available at https://github.com/liuxhym/AdapMen.
Hybrid Value Estimation for Off-policy Evaluation and Offline Reinforcement Learning
Jun 04, 2022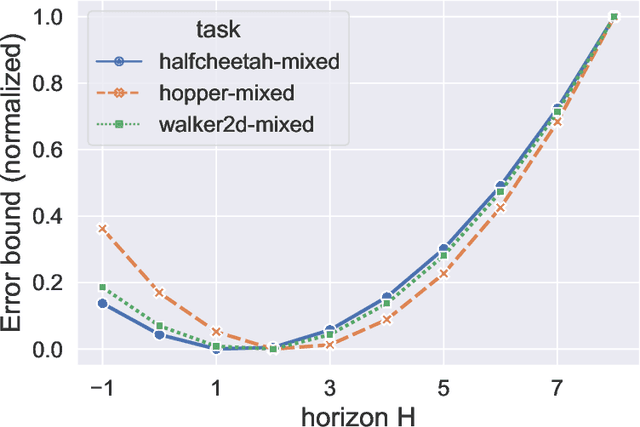
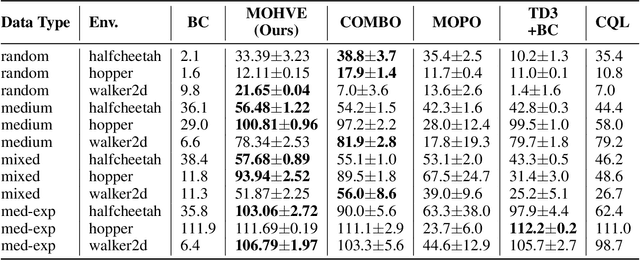
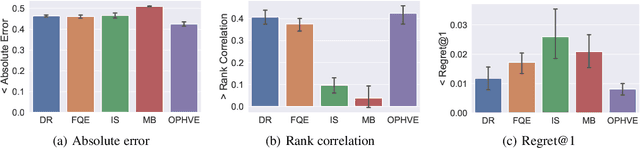

Value function estimation is an indispensable subroutine in reinforcement learning, which becomes more challenging in the offline setting. In this paper, we propose Hybrid Value Estimation (HVE) to reduce value estimation error, which trades off bias and variance by balancing between the value estimation from offline data and the learned model. Theoretical analysis discloses that HVE enjoys a better error bound than the direct methods. HVE can be leveraged in both off-policy evaluation and offline reinforcement learning settings. We, therefore, provide two concrete algorithms Off-policy HVE (OPHVE) and Model-based Offline HVE (MOHVE), respectively. Empirical evaluations on MuJoCo tasks corroborate the theoretical claim. OPHVE outperforms other off-policy evaluation methods in all three metrics measuring the estimation effectiveness, while MOHVE achieves better or comparable performance with state-of-the-art offline reinforcement learning algorithms. We hope that HVE could shed some light on further research on reinforcement learning from fixed data.
Regret Minimization Experience Replay
Jun 06, 2021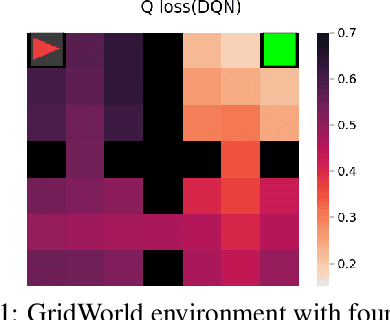

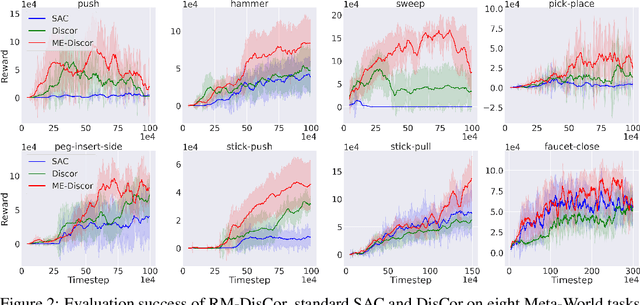
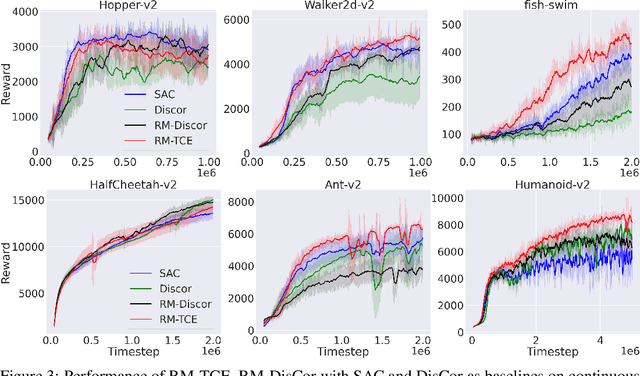
In reinforcement learning, experience replay stores past samples for further reuse. Prioritized sampling is a promising technique to better utilize these samples. Previous criteria of prioritization include TD error, recentness and corrective feedback, which are mostly heuristically designed. In this work, we start from the regret minimization objective, and obtain an optimal prioritization strategy for Bellman update that can directly maximize the return of the policy. The theory suggests that data with higher hindsight TD error, better on-policiness and more accurate Q value should be assigned with higher weights during sampling. Thus most previous criteria only consider this strategy partially. We not only provide theoretical justifications for previous criteria, but also propose two new methods to compute the prioritization weight, namely ReMERN and ReMERT. ReMERN learns an error network, while ReMERT exploits the temporal ordering of states. Both methods outperform previous prioritized sampling algorithms in challenging RL benchmarks, including MuJoCo, Atari and Meta-World.