 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge is Power: Advancing Few-shot Action Recognition with Multimodal Semantics from MLLMs
Mar 27, 2026Multimodal Large Language Models (MLLMs) have propelled the field of few-shot action recognition (FSAR). However, preliminary explorations in this area primarily focus on generating captions to form a suboptimal feature->caption->feature pipeline and adopt metric learning solely within the visual space. In this paper, we propose FSAR-LLaVA, the first end-to-end method to leverage MLLMs (such as Video-LLaVA) as a multimodal knowledge base for directly enhancing FSAR. First, at the feature level, we leverage the MLLM's multimodal decoder to extract spatiotemporally and semantically enriched representations, which are then decoupled and enhanced by our Multimodal Feature-Enhanced Module into distinct visual and textual features that fully exploit their semantic knowledge for FSAR. Next, we leverage the versatility of MLLMs to craft input prompts that flexibly adapt to diverse scenarios, and use their aligned outputs to drive our designed Composite Task-Oriented Prototype Construction, effectively bridging the distribution gap between meta-train and meta-test sets. Finally, to enable multimodal features to guide metric learning jointly, we introduce a training-free Multimodal Prototype Matching Metric that adaptively selects the most decisive cues and efficiently leverages the decoupled feature representations produced by MLLMs. Extensive experiments demonstrate superior performance across various tasks with minimal trainable parameters.
LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
Mar 20, 2026Recent advances in diffusion models have significantly improved text-to-video generation, enabling personalized content creation with fine-grained control over both foreground and background elements. However, precise face-attribute alignment across subjects remains challenging, as existing methods lack explicit mechanisms to ensure intra-group consistency. Addressing this gap requires both explicit modeling strategies and face-attribute-aware data resources. We therefore propose LumosX, a framework that advances both data and model design. On the data side, a tailored collection pipeline orchestrates captions and visual cues from independent videos, while multimodal large language models (MLLMs) infer and assign subject-specific dependencies. These extracted relational priors impose a finer-grained structure that amplifies the expressive control of personalized video generation and enables the construction of a comprehensive benchmark. On the modeling side, Relational Self-Attention and Relational Cross-Attention intertwine position-aware embeddings with refined attention dynamics to inscribe explicit subject-attribute dependencies, enforcing disciplined intra-group cohesion and amplifying the separation between distinct subject clusters. Comprehensive evaluations on our benchmark demonstrate that LumosX achieves state-of-the-art performance in fine-grained, identity-consistent, and semantically aligned personalized multi-subject video generation. Code and models are available at https://jiazheng-xing.github.io/lumosx-home/.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025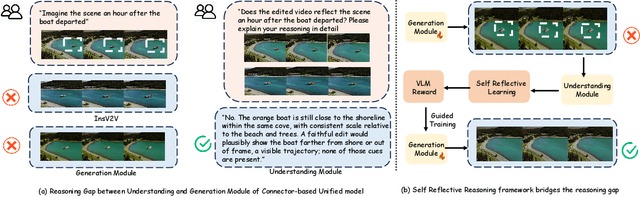
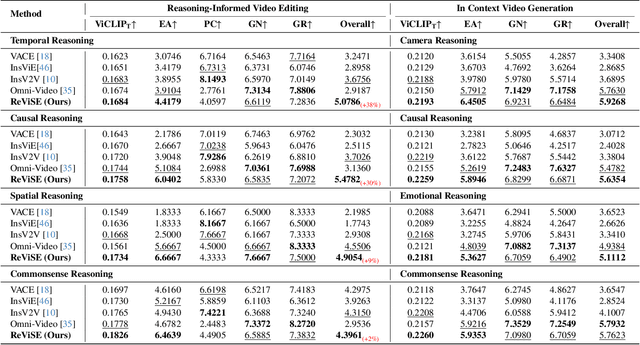

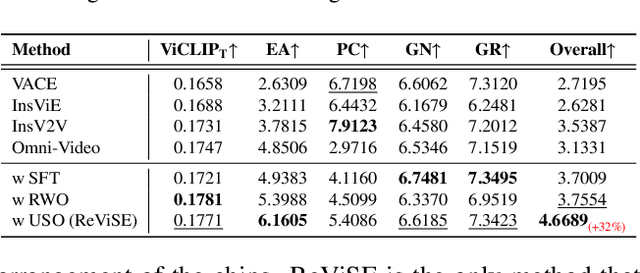
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
OptMark: Robust Multi-bit Diffusion Watermarking via Inference Time Optimization
Aug 29, 2025



Watermarking diffusion-generated images is crucial for copyright protection and user tracking. However, current diffusion watermarking methods face significant limitations: zero-bit watermarking systems lack the capacity for large-scale user tracking, while multi-bit methods are highly sensitive to certain image transformations or generative attacks, resulting in a lack of comprehensive robustness. In this paper, we propose OptMark, an optimization-based approach that embeds a robust multi-bit watermark into the intermediate latents of the diffusion denoising process. OptMark strategically inserts a structural watermark early to resist generative attacks and a detail watermark late to withstand image transformations, with tailored regularization terms to preserve image quality and ensure imperceptibility. To address the challenge of memory consumption growing linearly with the number of denoising steps during optimization, OptMark incorporates adjoint gradient methods, reducing memory usage from O(N) to O(1). Experimental results demonstrate that OptMark achieves invisible multi-bit watermarking while ensuring robust resilience against valuemetric transformations, geometric transformations, editing, and regeneration attacks.
Cyc3D: Fine-grained Controllable 3D Generation via Cycle Consistency Regularization
Apr 21, 2025


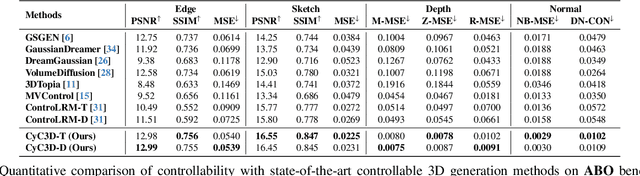
Despite the remarkable progress of 3D generation, achieving controllability, i.e., ensuring consistency between generated 3D content and input conditions like edge and depth, remains a significant challenge. Existing methods often struggle to maintain accurate alignment, leading to noticeable discrepancies. To address this issue, we propose \name{}, a new framework that enhances controllable 3D generation by explicitly encouraging cyclic consistency between the second-order 3D content, generated based on extracted signals from the first-order generation, and its original input controls. Specifically, we employ an efficient feed-forward backbone that can generate a 3D object from an input condition and a text prompt. Given an initial viewpoint and a control signal, a novel view is rendered from the generated 3D content, from which the extracted condition is used to regenerate the 3D content. This re-generated output is then rendered back to the initial viewpoint, followed by another round of control signal extraction, forming a cyclic process with two consistency constraints. \emph{View consistency} ensures coherence between the two generated 3D objects, measured by semantic similarity to accommodate generative diversity. \emph{Condition consistency} aligns the final extracted signal with the original input control, preserving structural or geometric details throughout the process. Extensive experiments on popular benchmarks demonstrate that \name{} significantly improves controllability, especially for fine-grained details, outperforming existing methods across various conditions (e.g., +14.17\% PSNR for edge, +6.26\% PSNR for sketch).
Visual Object Tracking across Diverse Data Modalities: A Review
Dec 13, 2024



Visual Object Tracking (VOT) is an attractive and significant research area in computer vision, which aims to recognize and track specific targets in video sequences where the target objects are arbitrary and class-agnostic. The VOT technology could be applied in various scenarios, processing data of diverse modalities such as RGB, thermal infrared and point cloud. Besides, since no one sensor could handle all the dynamic and varying environments, multi-modal VOT is also investigated. This paper presents a comprehensive survey of the recent progress of both single-modal and multi-modal VOT, especially the deep learning methods. Specifically, we first review three types of mainstream single-modal VOT, including RGB, thermal infrared and point cloud tracking. In particular, we conclude four widely-used single-modal frameworks, abstracting their schemas and categorizing the existing inheritors. Then we summarize four kinds of multi-modal VOT, including RGB-Depth, RGB-Thermal, RGB-LiDAR and RGB-Language. Moreover, the comparison results in plenty of VOT benchmarks of the discussed modalities are presented. Finally, we provide recommendations and insightful observations, inspiring the future development of this fast-growing literature.
TryOn-Adapter: Efficient Fine-Grained Clothing Identity Adaptation for High-Fidelity Virtual Try-On
Apr 01, 2024



Virtual try-on focuses on adjusting the given clothes to fit a specific person seamlessly while avoiding any distortion of the patterns and textures of the garment. However, the clothing identity uncontrollability and training inefficiency of existing diffusion-based methods, which struggle to maintain the identity even with full parameter training, are significant limitations that hinder the widespread applications. In this work, we propose an effective and efficient framework, termed TryOn-Adapter. Specifically, we first decouple clothing identity into fine-grained factors: style for color and category information, texture for high-frequency details, and structure for smooth spatial adaptive transformation. Our approach utilizes a pre-trained exemplar-based diffusion model as the fundamental network, whose parameters are frozen except for the attention layers. We then customize three lightweight modules (Style Preserving, Texture Highlighting, and Structure Adapting) incorporated with fine-tuning techniques to enable precise and efficient identity control. Meanwhile, we introduce the training-free T-RePaint strategy to further enhance clothing identity preservation while maintaining the realistic try-on effect during the inference. Our experiments demonstrate that our approach achieves state-of-the-art performance on two widely-used benchmarks. Additionally, compared with recent full-tuning diffusion-based methods, we only use about half of their tunable parameters during training. The code will be made publicly available at https://github.com/jiazheng-xing/TryOn-Adapter.
SDSTrack: Self-Distillation Symmetric Adapter Learning for Multi-Modal Visual Object Tracking
Mar 28, 2024


Multimodal Visual Object Tracking (VOT) has recently gained significant attention due to its robustness. Early research focused on fully fine-tuning RGB-based trackers, which was inefficient and lacked generalized representation due to the scarcity of multimodal data. Therefore, recent studies have utilized prompt tuning to transfer pre-trained RGB-based trackers to multimodal data. However, the modality gap limits pre-trained knowledge recall, and the dominance of the RGB modality persists, preventing the full utilization of information from other modalities. To address these issues, we propose a novel symmetric multimodal tracking framework called SDSTrack. We introduce lightweight adaptation for efficient fine-tuning, which directly transfers the feature extraction ability from RGB to other domains with a small number of trainable parameters and integrates multimodal features in a balanced, symmetric manner. Furthermore, we design a complementary masked patch distillation strategy to enhance the robustness of trackers in complex environments, such as extreme weather, poor imaging, and sensor failure. Extensive experiments demonstrate that SDSTrack outperforms state-of-the-art methods in various multimodal tracking scenarios, including RGB+Depth, RGB+Thermal, and RGB+Event tracking, and exhibits impressive results in extreme conditions. Our source code is available at https://github.com/hoqolo/SDSTrack.
FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio
Mar 04, 2024



In this paper, we abstract the process of people hearing speech, extracting meaningful cues, and creating various dynamically audio-consistent talking faces, termed Listening and Imagining, into the task of high-fidelity diverse talking faces generation from a single audio. Specifically, it involves two critical challenges: one is to effectively decouple identity, content, and emotion from entangled audio, and the other is to maintain intra-video diversity and inter-video consistency. To tackle the issues, we first dig out the intricate relationships among facial factors and simplify the decoupling process, tailoring a Progressive Audio Disentanglement for accurate facial geometry and semantics learning, where each stage incorporates a customized training module responsible for a specific factor. Secondly, to achieve visually diverse and audio-synchronized animation solely from input audio within a single model, we introduce the Controllable Coherent Frame generation, which involves the flexible integration of three trainable adapters with frozen Latent Diffusion Models (LDMs) to focus on maintaining facial geometry and semantics, as well as texture and temporal coherence between frames. In this way, we inherit high-quality diverse generation from LDMs while significantly improving their controllability at a low training cost. Extensive experiments demonstrate the flexibility and effectiveness of our method in handling this paradigm. The codes will be released at https://github.com/modelscope/facechain.
M2-CLIP: A Multimodal, Multi-task Adapting Framework for Video Action Recognition
Jan 22, 2024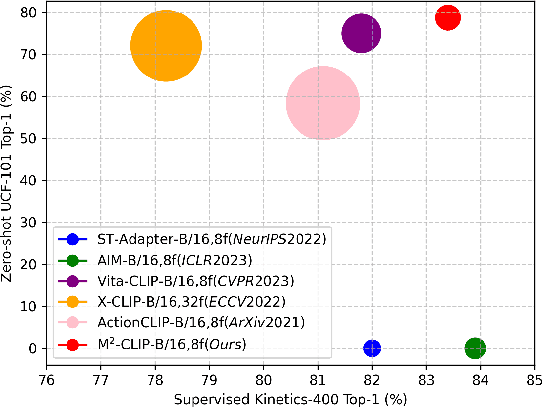
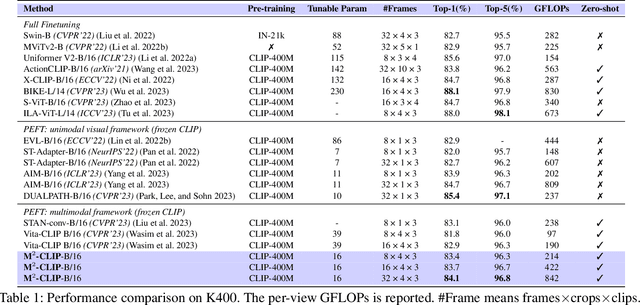

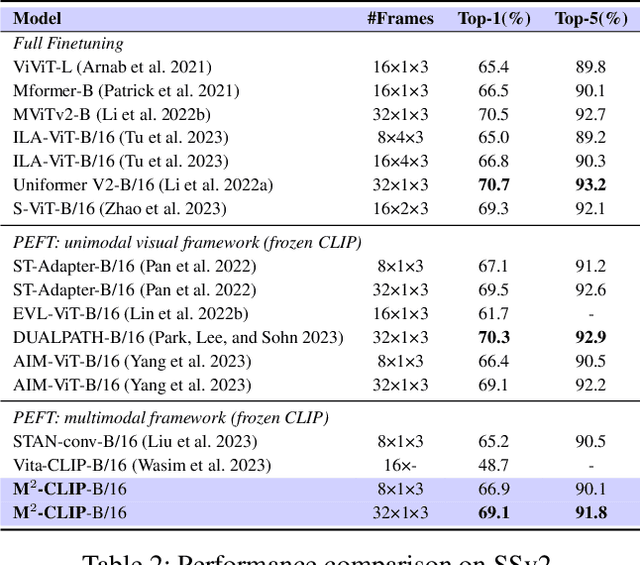
Recently, the rise of large-scale vision-language pretrained models like CLIP, coupled with the technology of Parameter-Efficient FineTuning (PEFT), has captured substantial attraction in video action recognition. Nevertheless, prevailing approaches tend to prioritize strong supervised performance at the expense of compromising the models' generalization capabilities during transfer. In this paper, we introduce a novel Multimodal, Multi-task CLIP adapting framework named \name to address these challenges, preserving both high supervised performance and robust transferability. Firstly, to enhance the individual modality architectures, we introduce multimodal adapters to both the visual and text branches. Specifically, we design a novel visual TED-Adapter, that performs global Temporal Enhancement and local temporal Difference modeling to improve the temporal representation capabilities of the visual encoder. Moreover, we adopt text encoder adapters to strengthen the learning of semantic label information. Secondly, we design a multi-task decoder with a rich set of supervisory signals to adeptly satisfy the need for strong supervised performance and generalization within a multimodal framework. Experimental results validate the efficacy of our approach, demonstrating exceptional performance in supervised learning while maintaining strong generalization in zero-shot scenarios.