 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Spatial and Temporal Modeling for Few-shot Action Recognition
Paper and Code
Jan 19, 2023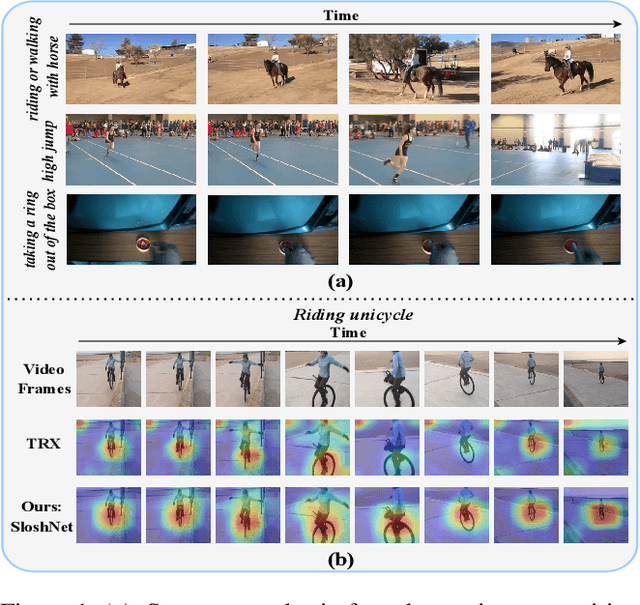

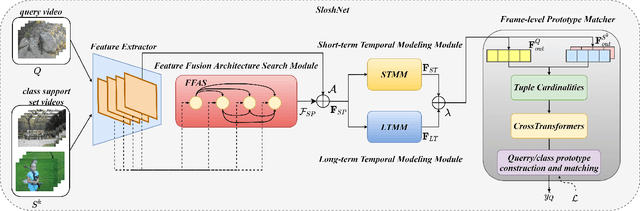
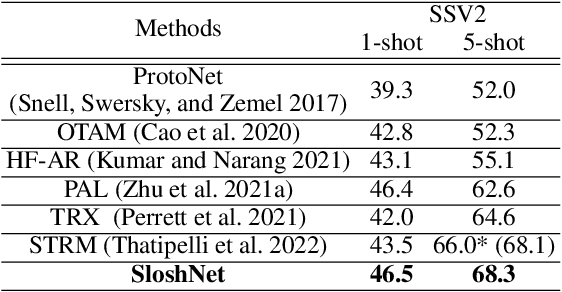
Spatial and temporal modeling is one of the most core aspects of few-shot action recognition. Most previous works mainly focus on long-term temporal relation modeling based on high-level spatial representations, without considering the crucial low-level spatial features and short-term temporal relations. Actually, the former feature could bring rich local semantic information, and the latter feature could represent motion characteristics of adjacent frames, respectively. In this paper, we propose SloshNet, a new framework that revisits the spatial and temporal modeling for few-shot action recognition in a finer manner. First, to exploit the low-level spatial features, we design a feature fusion architecture search module to automatically search for the best combination of the low-level and high-level spatial features. Next, inspired by the recent transformer, we introduce a long-term temporal modeling module to model the global temporal relations based on the extracted spatial appearance features. Meanwhile, we design another short-term temporal modeling module to encode the motion characteristics between adjacent frame representations. After that, the final predictions can be obtained by feeding the embedded rich spatial-temporal features to a common frame-level class prototype matcher. We extensively validate the proposed SloshNet on four few-shot action recognition datasets, including Something-Something V2, Kinetics, UCF101, and HMDB51. It achieves favorable results against state-of-the-art methods in all datasets.