 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyc3D: Fine-grained Controllable 3D Generation via Cycle Consistency Regularization
Apr 21, 2025


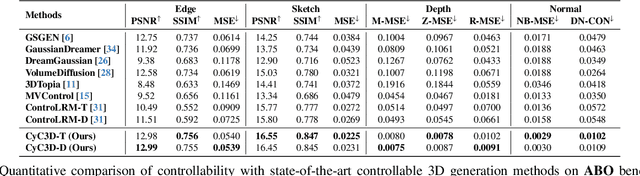
Despite the remarkable progress of 3D generation, achieving controllability, i.e., ensuring consistency between generated 3D content and input conditions like edge and depth, remains a significant challenge. Existing methods often struggle to maintain accurate alignment, leading to noticeable discrepancies. To address this issue, we propose \name{}, a new framework that enhances controllable 3D generation by explicitly encouraging cyclic consistency between the second-order 3D content, generated based on extracted signals from the first-order generation, and its original input controls. Specifically, we employ an efficient feed-forward backbone that can generate a 3D object from an input condition and a text prompt. Given an initial viewpoint and a control signal, a novel view is rendered from the generated 3D content, from which the extracted condition is used to regenerate the 3D content. This re-generated output is then rendered back to the initial viewpoint, followed by another round of control signal extraction, forming a cyclic process with two consistency constraints. \emph{View consistency} ensures coherence between the two generated 3D objects, measured by semantic similarity to accommodate generative diversity. \emph{Condition consistency} aligns the final extracted signal with the original input control, preserving structural or geometric details throughout the process. Extensive experiments on popular benchmarks demonstrate that \name{} significantly improves controllability, especially for fine-grained details, outperforming existing methods across various conditions (e.g., +14.17\% PSNR for edge, +6.26\% PSNR for sketch).
4DStyleGaussian: Zero-shot 4D Style Transfer with Gaussian Splatting
Oct 14, 20243D neural style transfer has gained significant attention for its potential to provide user-friendly stylization with spatial consistency. However, existing 3D style transfer methods often fall short in terms of inference efficiency, generalization ability, and struggle to handle dynamic scenes with temporal consistency. In this paper, we introduce 4DStyleGaussian, a novel 4D style transfer framework designed to achieve real-time stylization of arbitrary style references while maintaining reasonable content affinity, multi-view consistency, and temporal coherence. Our approach leverages an embedded 4D Gaussian Splatting technique, which is trained using a reversible neural network for reducing content loss in the feature distillation process. Utilizing the 4D embedded Gaussians, we predict a 4D style transformation matrix that facilitates spatially and temporally consistent style transfer with Gaussian Splatting. Experiments demonstrate that our method can achieve high-quality and zero-shot stylization for 4D scenarios with enhanced efficiency and spatial-temporal consistency.
ControLRM: Fast and Controllable 3D Generation via Large Reconstruction Model
Oct 12, 2024



Despite recent advancements in 3D generation methods, achieving controllability still remains a challenging issue. Current approaches utilizing score-distillation sampling are hindered by laborious procedures that consume a significant amount of time. Furthermore, the process of first generating 2D representations and then mapping them to 3D lacks internal alignment between the two forms of representation. To address these challenges, we introduce ControLRM, an end-to-end feed-forward model designed for rapid and controllable 3D generation using a large reconstruction model (LRM). ControLRM comprises a 2D condition generator, a condition encoding transformer, and a triplane decoder transformer. Instead of training our model from scratch, we advocate for a joint training framework. In the condition training branch, we lock the triplane decoder and reuses the deep and robust encoding layers pretrained with millions of 3D data in LRM. In the image training branch, we unlock the triplane decoder to establish an implicit alignment between the 2D and 3D representations. To ensure unbiased evaluation, we curate evaluation samples from three distinct datasets (G-OBJ, GSO, ABO) rather than relying on cherry-picking manual generation. The comprehensive experiments conducted on quantitative and qualitative comparisons of 3D controllability and generation quality demonstrate the strong generalization capacity of our proposed approach.
RobustMVS: Single Domain Generalized Deep Multi-view Stereo
May 15, 2024



Despite the impressive performance of Multi-view Stereo (MVS) approaches given plenty of training samples, the performance degradation when generalizing to unseen domains has not been clearly explored yet. In this work, we focus on the domain generalization problem in MVS. To evaluate the generalization results, we build a novel MVS domain generalization benchmark including synthetic and real-world datasets. In contrast to conventional domain generalization benchmarks, we consider a more realistic but challenging scenario, where only one source domain is available for training. The MVS problem can be analogized back to the feature matching task, and maintaining robust feature consistency among views is an important factor for improving generalization performance. To address the domain generalization problem in MVS, we propose a novel MVS framework, namely RobustMVS. A DepthClustering-guided Whitening (DCW) loss is further introduced to preserve the feature consistency among different views, which decorrelates multi-view features from viewpoint-specific style information based on geometric priors from depth maps. The experimental results further show that our method achieves superior performance on the domain generalization benchmark.
StyleDyRF: Zero-shot 4D Style Transfer for Dynamic Neural Radiance Fields
Mar 13, 2024



4D style transfer aims at transferring arbitrary visual style to the synthesized novel views of a dynamic 4D scene with varying viewpoints and times. Existing efforts on 3D style transfer can effectively combine the visual features of style images and neural radiance fields (NeRF) but fail to handle the 4D dynamic scenes limited by the static scene assumption. Consequently, we aim to handle the novel challenging problem of 4D style transfer for the first time, which further requires the consistency of stylized results on dynamic objects. In this paper, we introduce StyleDyRF, a method that represents the 4D feature space by deforming a canonical feature volume and learns a linear style transformation matrix on the feature volume in a data-driven fashion. To obtain the canonical feature volume, the rays at each time step are deformed with the geometric prior of a pre-trained dynamic NeRF to render the feature map under the supervision of pre-trained visual encoders. With the content and style cues in the canonical feature volume and the style image, we can learn the style transformation matrix from their covariance matrices with lightweight neural networks. The learned style transformation matrix can reflect a direct matching of feature covariance from the content volume to the given style pattern, in analogy with the optimization of the Gram matrix in traditional 2D neural style transfer. The experimental results show that our method not only renders 4D photorealistic style transfer results in a zero-shot manner but also outperforms existing methods in terms of visual quality and consistency.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023



Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
CostFormer:Cost Transformer for Cost Aggregation in Multi-view Stereo
May 17, 2023



The core of Multi-view Stereo(MVS) is the matching process among reference and source pixels. Cost aggregation plays a significant role in this process, while previous methods focus on handling it via CNNs. This may inherit the natural limitation of CNNs that fail to discriminate repetitive or incorrect matches due to limited local receptive fields. To handle the issue, we aim to involve Transformer into cost aggregation. However, another problem may occur due to the quadratically growing computational complexity caused by Transformer, resulting in memory overflow and inference latency. In this paper, we overcome these limits with an efficient Transformer-based cost aggregation network, namely CostFormer. The Residual Depth-Aware Cost Transformer(RDACT) is proposed to aggregate long-range features on cost volume via self-attention mechanisms along the depth and spatial dimensions. Furthermore, Residual Regression Transformer(RRT) is proposed to enhance spatial attention. The proposed method is a universal plug-in to improve learning-based MVS methods.