 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge is Power: Advancing Few-shot Action Recognition with Multimodal Semantics from MLLMs
Mar 27, 2026Multimodal Large Language Models (MLLMs) have propelled the field of few-shot action recognition (FSAR). However, preliminary explorations in this area primarily focus on generating captions to form a suboptimal feature->caption->feature pipeline and adopt metric learning solely within the visual space. In this paper, we propose FSAR-LLaVA, the first end-to-end method to leverage MLLMs (such as Video-LLaVA) as a multimodal knowledge base for directly enhancing FSAR. First, at the feature level, we leverage the MLLM's multimodal decoder to extract spatiotemporally and semantically enriched representations, which are then decoupled and enhanced by our Multimodal Feature-Enhanced Module into distinct visual and textual features that fully exploit their semantic knowledge for FSAR. Next, we leverage the versatility of MLLMs to craft input prompts that flexibly adapt to diverse scenarios, and use their aligned outputs to drive our designed Composite Task-Oriented Prototype Construction, effectively bridging the distribution gap between meta-train and meta-test sets. Finally, to enable multimodal features to guide metric learning jointly, we introduce a training-free Multimodal Prototype Matching Metric that adaptively selects the most decisive cues and efficiently leverages the decoupled feature representations produced by MLLMs. Extensive experiments demonstrate superior performance across various tasks with minimal trainable parameters.
Quantization of Climate Change Impacts on Renewable Energy Generation Capacity: A Super-Resolution Recurrent Diffusion Model
Dec 16, 2024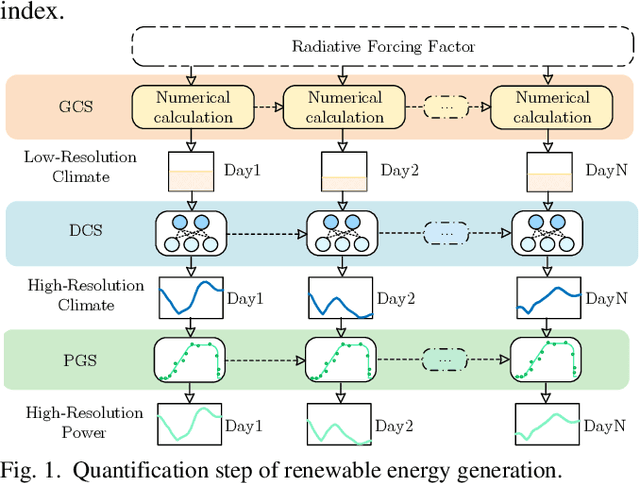
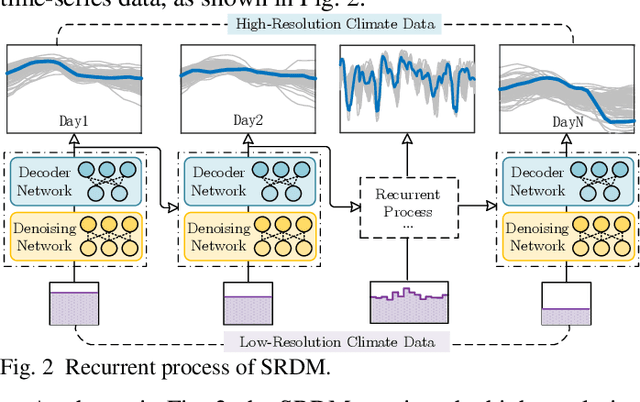
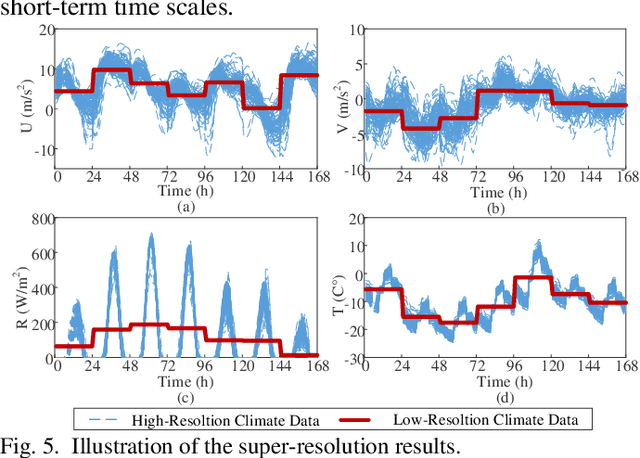
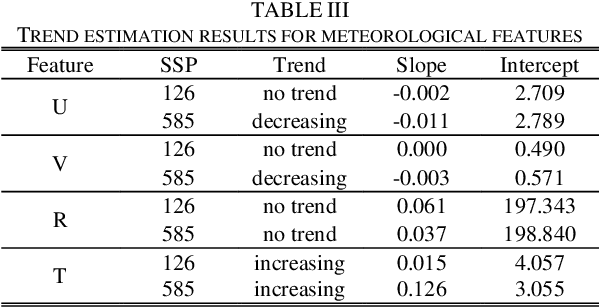
Driven by global climate change and the ongoing energy transition, the coupling between power supply capabilities and meteorological factors has become increasingly significant. Over the long term, accurately quantifying the power generation capacity of renewable energy under the influence of climate change is essential for the development of sustainable power systems. However, due to interdisciplinary differences in data requirements, climate data often lacks the necessary hourly resolution to capture the short-term variability and uncertainties of renewable energy resources. To address this limitation, a super-resolution recurrent diffusion model (SRDM) has been developed to enhance the temporal resolution of climate data and model the short-term uncertainty. The SRDM incorporates a pre-trained decoder and a denoising network, that generates long-term, high-resolution climate data through a recurrent coupling mechanism. The high-resolution climate data is then converted into power value using the mechanism model, enabling the simulation of wind and photovoltaic (PV) power generation capacity on future long-term scales. Case studies were conducted in the Ejina region of Inner Mongolia, China, using fifth-generation reanalysis (ERA5) and coupled model intercomparison project (CMIP6) data under two climate pathways: SSP126 and SSP585. The results demonstrate that the SRDM outperforms existing generative models in generating super-resolution climate data. For the Ejina region, under a high-emission pathway, the annual utilization hours of wind power are projected to decrease by 2.82 hours/year, while those for PV power are projected to decrease by 0.26 hours/year. Furthermore, the research highlights the estimation biases introduced when low-resolution climate data is used for power conversion.
FaceChain-FACT: Face Adapter with Decoupled Training for Identity-preserved Personalization
Oct 16, 2024



In the field of human-centric personalized image generation, the adapter-based method obtains the ability to customize and generate portraits by text-to-image training on facial data. This allows for identity-preserved personalization without additional fine-tuning in inference. Although there are improvements in efficiency and fidelity, there is often a significant performance decrease in test following ability, controllability, and diversity of generated faces compared to the base model. In this paper, we analyze that the performance degradation is attributed to the failure to decouple identity features from other attributes during extraction, as well as the failure to decouple the portrait generation training from the overall generation task. To address these issues, we propose the Face Adapter with deCoupled Training (FACT) framework, focusing on both model architecture and training strategy. To decouple identity features from others, we leverage a transformer-based face-export encoder and harness fine-grained identity features. To decouple the portrait generation training, we propose Face Adapting Increment Regularization~(FAIR), which effectively constrains the effect of face adapters on the facial region, preserving the generative ability of the base model. Additionally, we incorporate a face condition drop and shuffle mechanism, combined with curriculum learning, to enhance facial controllability and diversity. As a result, FACT solely learns identity preservation from training data, thereby minimizing the impact on the original text-to-image capabilities of the base model. Extensive experiments show that FACT has both controllability and fidelity in both text-to-image generation and inpainting solutions for portrait generation.
TopoFR: A Closer Look at Topology Alignment on Face Recognition
Oct 14, 2024



The field of face recognition (FR) has undergone significant advancements with the rise of deep learning. Recently, the success of unsupervised learning and graph neural networks has demonstrated the effectiveness of data structure information. Considering that the FR task can leverage large-scale training data, which intrinsically contains significant structure information, we aim to investigate how to encode such critical structure information into the latent space. As revealed from our observations, directly aligning the structure information between the input and latent spaces inevitably suffers from an overfitting problem, leading to a structure collapse phenomenon in the latent space. To address this problem, we propose TopoFR, a novel FR model that leverages a topological structure alignment strategy called PTSA and a hard sample mining strategy named SDE. Concretely, PTSA uses persistent homology to align the topological structures of the input and latent spaces, effectively preserving the structure information and improving the generalization performance of FR model. To mitigate the impact of hard samples on the latent space structure, SDE accurately identifies hard samples by automatically computing structure damage score (SDS) for each sample, and directs the model to prioritize optimizing these samples. Experimental results on popular face benchmarks demonstrate the superiority of our TopoFR over the state-of-the-art methods. Code and models are available at: https://github.com/modelscope/facechain/tree/main/face_module/TopoFR.
CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
May 17, 2024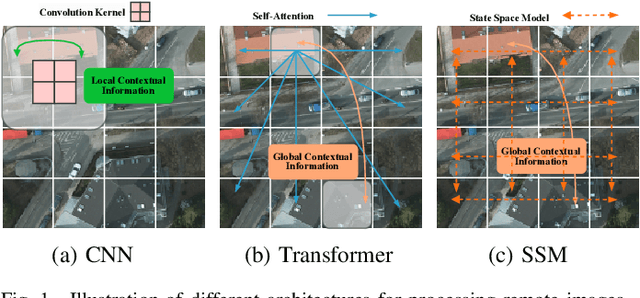
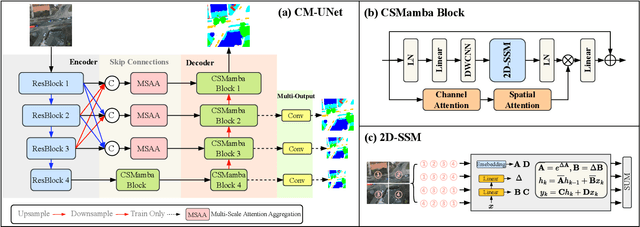
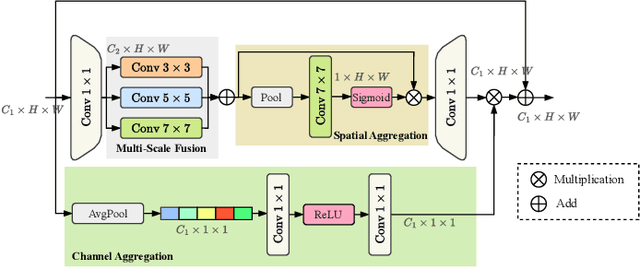
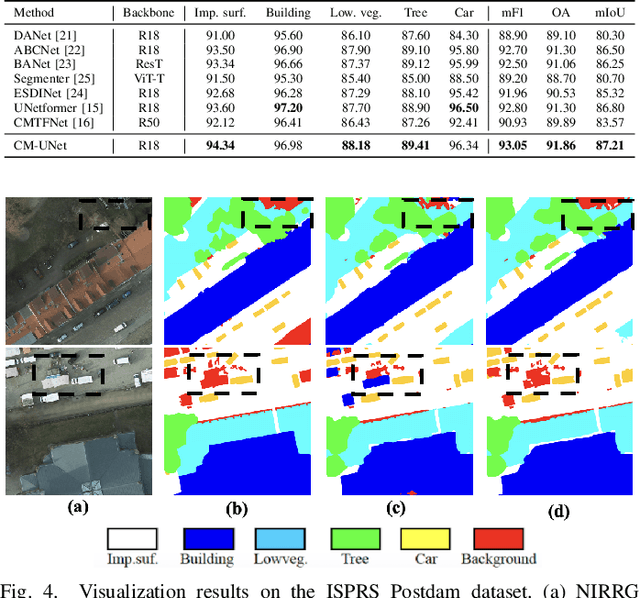
Due to the large-scale image size and object variations, current CNN-based and Transformer-based approaches for remote sensing image semantic segmentation are suboptimal for capturing the long-range dependency or limited to the complex computational complexity. In this paper, we propose CM-UNet, comprising a CNN-based encoder for extracting local image features and a Mamba-based decoder for aggregating and integrating global information, facilitating efficient semantic segmentation of remote sensing images. Specifically, a CSMamba block is introduced to build the core segmentation decoder, which employs channel and spatial attention as the gate activation condition of the vanilla Mamba to enhance the feature interaction and global-local information fusion. Moreover, to further refine the output features from the CNN encoder, a Multi-Scale Attention Aggregation (MSAA) module is employed to merge the different scale features. By integrating the CSMamba block and MSAA module, CM-UNet effectively captures the long-range dependencies and multi-scale global contextual information of large-scale remote-sensing images. Experimental results obtained on three benchmarks indicate that the proposed CM-UNet outperforms existing methods in various performance metrics. The codes are available at https://github.com/XiaoBuL/CM-UNet.
FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio
Mar 04, 2024



In this paper, we abstract the process of people hearing speech, extracting meaningful cues, and creating various dynamically audio-consistent talking faces, termed Listening and Imagining, into the task of high-fidelity diverse talking faces generation from a single audio. Specifically, it involves two critical challenges: one is to effectively decouple identity, content, and emotion from entangled audio, and the other is to maintain intra-video diversity and inter-video consistency. To tackle the issues, we first dig out the intricate relationships among facial factors and simplify the decoupling process, tailoring a Progressive Audio Disentanglement for accurate facial geometry and semantics learning, where each stage incorporates a customized training module responsible for a specific factor. Secondly, to achieve visually diverse and audio-synchronized animation solely from input audio within a single model, we introduce the Controllable Coherent Frame generation, which involves the flexible integration of three trainable adapters with frozen Latent Diffusion Models (LDMs) to focus on maintaining facial geometry and semantics, as well as texture and temporal coherence between frames. In this way, we inherit high-quality diverse generation from LDMs while significantly improving their controllability at a low training cost. Extensive experiments demonstrate the flexibility and effectiveness of our method in handling this paradigm. The codes will be released at https://github.com/modelscope/facechain.
PRCL: Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation
Feb 28, 2024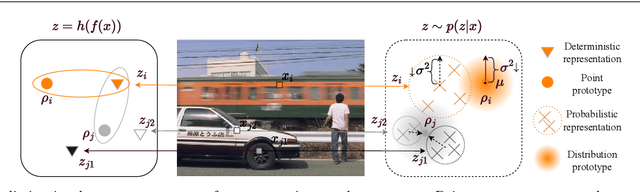
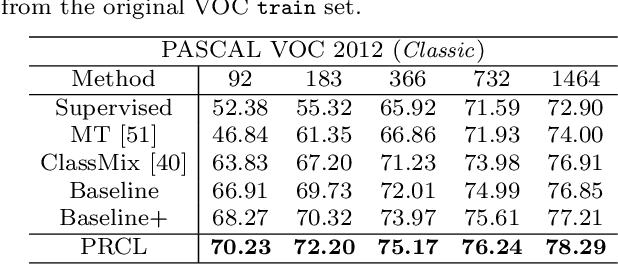
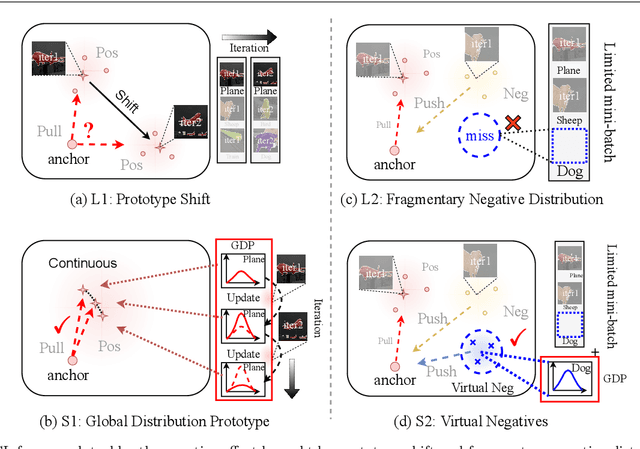
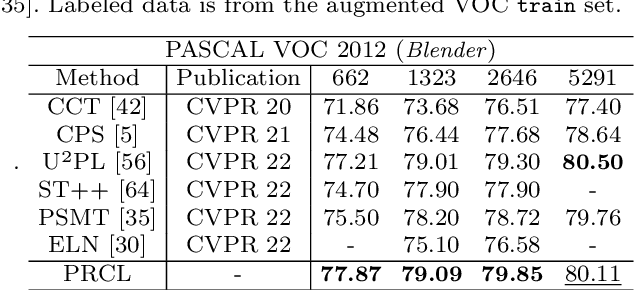
Tremendous breakthroughs have been developed in Semi-Supervised Semantic Segmentation (S4) through contrastive learning. However, due to limited annotations, the guidance on unlabeled images is generated by the model itself, which inevitably exists noise and disturbs the unsupervised training process. To address this issue, we propose a robust contrastive-based S4 framework, termed the Probabilistic Representation Contrastive Learning (PRCL) framework to enhance the robustness of the unsupervised training process. We model the pixel-wise representation as Probabilistic Representations (PR) via multivariate Gaussian distribution and tune the contribution of the ambiguous representations to tolerate the risk of inaccurate guidance in contrastive learning. Furthermore, we introduce Global Distribution Prototypes (GDP) by gathering all PRs throughout the whole training process. Since the GDP contains the information of all representations with the same class, it is robust from the instant noise in representations and bears the intra-class variance of representations. In addition, we generate Virtual Negatives (VNs) based on GDP to involve the contrastive learning process. Extensive experiments on two public benchmarks demonstrate the superiority of our PRCL framework.
TransFace: Calibrating Transformer Training for Face Recognition from a Data-Centric Perspective
Aug 20, 2023



Vision Transformers (ViTs) have demonstrated powerful representation ability in various visual tasks thanks to their intrinsic data-hungry nature. However, we unexpectedly find that ViTs perform vulnerably when applied to face recognition (FR) scenarios with extremely large datasets. We investigate the reasons for this phenomenon and discover that the existing data augmentation approach and hard sample mining strategy are incompatible with ViTs-based FR backbone due to the lack of tailored consideration on preserving face structural information and leveraging each local token information. To remedy these problems, this paper proposes a superior FR model called TransFace, which employs a patch-level data augmentation strategy named DPAP and a hard sample mining strategy named EHSM. Specially, DPAP randomly perturbs the amplitude information of dominant patches to expand sample diversity, which effectively alleviates the overfitting problem in ViTs. EHSM utilizes the information entropy in the local tokens to dynamically adjust the importance weight of easy and hard samples during training, leading to a more stable prediction. Experiments on several benchmarks demonstrate the superiority of our TransFace. Code and models are available at https://github.com/DanJun6737/TransFace.